 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHDRFace: Rethinking Face Restoration with High-Dimensional Representation
May 14, 2026Face restoration under complex degradations still remains an ill-posed inverse problem due to severe information loss. Although diffusion models benefit from strong generative priors, most methods still condition only on low-quality inputs, making it difficult to recover identity-critical details under heavy degradations. In this work, we propose HDRFace, a High-Dimensional Representation conditioned Face restoration framework that injects semantically rich priors into the conditional flow without modifying the generative backbone. Our pipeline first obtains a structurally reliable intermediate restoration with an off-the-shelf restorer, then uses a pretrained high-dimensional feature encoder to extract fine-grained facial representations from both the low-quality input and the intermediate result, and injects them as additional conditions for generation. We further introduce SDFM, a Structure-Detail aware adaptive Fusion Mechanism that emphasizes global constraints during structure modeling and strengthens representation guidance during detail synthesis, balancing structural consistency and detail fidelity. To validate the generalization ability of our method, we implement the proposed framework on two generative models, SD V2.1-base and Qwen-Image, and consistently observe stable and coherent performance gains across different architectures.
BeautyGRPO: Aesthetic Alignment for Face Retouching via Dynamic Path Guidance and Fine-Grained Preference Modeling
Mar 01, 2026Face retouching requires removing subtle imperfections while preserving unique facial identity features, in order to enhance overall aesthetic appeal. However, existing methods suffer from a fundamental trade-off. Supervised learning on labeled data is constrained to pixel-level label mimicry, failing to capture complex subjective human aesthetic preferences. Conversely, while online reinforcement learning (RL) excels at preference alignment, its stochastic exploration paradigm conflicts with the high-fidelity demands of face retouching and often introduces noticeable noise artifacts due to accumulated stochastic drift. To address these limitations, we propose BeautyGRPO, a reinforcement learning framework that aligns face retouching with human aesthetic preferences. We construct FRPref-10K, a fine-grained preference dataset covering five key retouching dimensions, and train a specialized reward model capable of evaluating subtle perceptual differences. To reconcile exploration and fidelity, we introduce Dynamic Path Guidance (DPG). DPG stabilizes the stochastic sampling trajectory by dynamically computing an anchor-based ODE path and replanning a guided trajectory at each sampling timestep, effectively correcting stochastic drift while maintaining controlled exploration. Extensive experiments show that BeautyGRPO outperforms both specialized face retouching methods and general image editing models, achieving superior texture quality, more accurate blemish removal, and overall results that better align with human aesthetic preferences.
I3Net: Implicit Instance-Invariant Network for Adapting One-Stage Object Detectors
Mar 30, 2021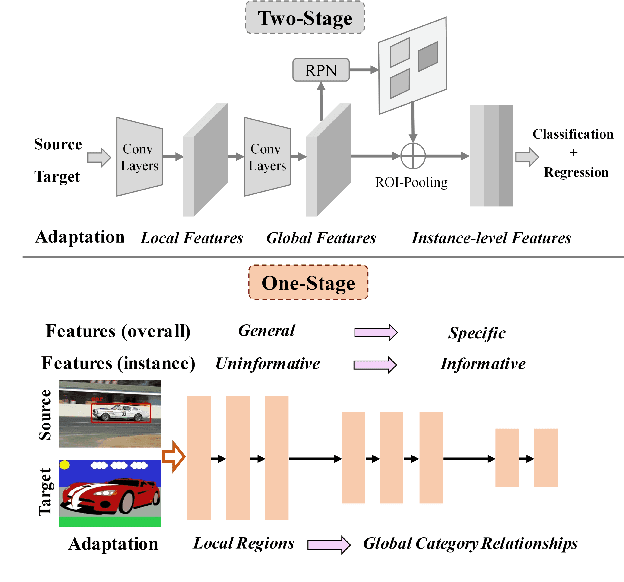
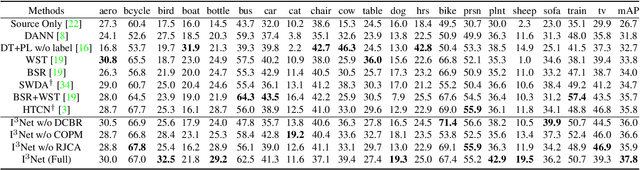
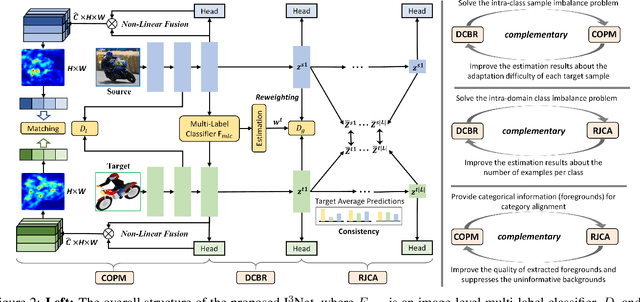
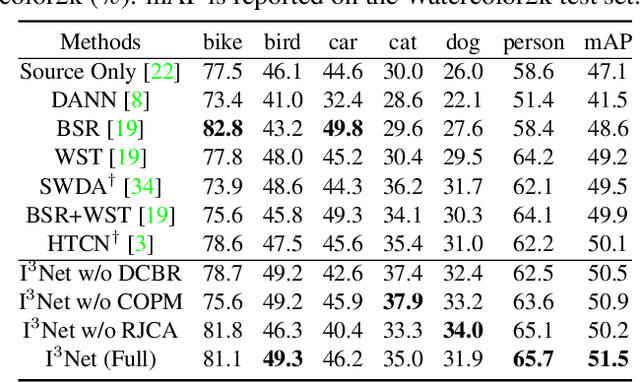
Recent works on two-stage cross-domain detection have widely explored the local feature patterns to achieve more accurate adaptation results. These methods heavily rely on the region proposal mechanisms and ROI-based instance-level features to design fine-grained feature alignment modules with respect to the foreground objects. However, for one-stage detectors, it is hard or even impossible to obtain explicit instance-level features in the detection pipelines. Motivated by this, we propose an Implicit Instance-Invariant Network (I3Net), which is tailored for adapting one-stage detectors and implicitly learns instance-invariant features via exploiting the natural characteristics of deep features in different layers. Specifically, we facilitate the adaptation from three aspects: (1) Dynamic and Class-Balanced Reweighting (DCBR) strategy, which considers the coexistence of intra-domain and intra-class variations to assign larger weights to those sample-scarce categories and easy-to-adapt samples; (2) Category-aware Object Pattern Matching (COPM) module, which boosts the cross-domain foreground objects matching guided by the categorical information and suppresses the uninformative background features; (3) Regularized Joint Category Alignment (RJCA) module, which jointly enforces the category alignment at different domain-specific layers with a consistency regularization. Experiments reveal that I3Net exceeds the state-of-the-art performance on benchmark datasets.
Harmonizing Transferability and Discriminability for Adapting Object Detectors
Mar 13, 2020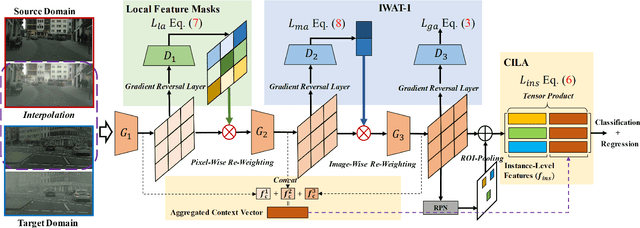
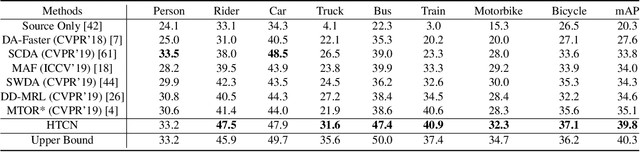
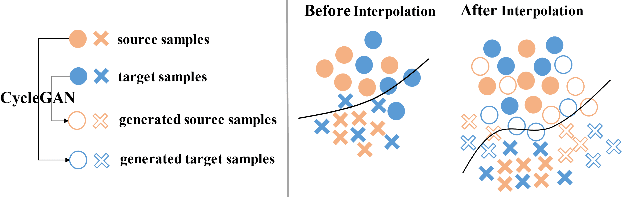

Recent advances in adaptive object detection have achieved compelling results in virtue of adversarial feature adaptation to mitigate the distributional shifts along the detection pipeline. Whilst adversarial adaptation significantly enhances the transferability of feature representations, the feature discriminability of object detectors remains less investigated. Moreover, transferability and discriminability may come at a contradiction in adversarial adaptation given the complex combinations of objects and the differentiated scene layouts between domains. In this paper, we propose a Hierarchical Transferability Calibration Network (HTCN) that hierarchically (local-region/image/instance) calibrates the transferability of feature representations for harmonizing transferability and discriminability. The proposed model consists of three components: (1) Importance Weighted Adversarial Training with input Interpolation (IWAT-I), which strengthens the global discriminability by re-weighting the interpolated image-level features; (2) Context-aware Instance-Level Alignment (CILA) module, which enhances the local discriminability by capturing the underlying complementary effect between the instance-level feature and the global context information for the instance-level feature alignment; (3) local feature masks that calibrate the local transferability to provide semantic guidance for the following discriminative pattern alignment. Experimental results show that HTCN significantly outperforms the state-of-the-art methods on benchmark datasets.