 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistencyDet: A Robust Object Detector with a Denoising Paradigm of Consistency Model
Apr 17, 2024



Object detection, a quintessential task in the realm of perceptual computing, can be tackled using a generative methodology. In the present study, we introduce a novel framework designed to articulate object detection as a denoising diffusion process, which operates on the perturbed bounding boxes of annotated entities. This framework, termed ConsistencyDet, leverages an innovative denoising concept known as the Consistency Model. The hallmark of this model is its self-consistency feature, which empowers the model to map distorted information from any temporal stage back to its pristine state, thereby realizing a "one-step denoising" mechanism. Such an attribute markedly elevates the operational efficiency of the model, setting it apart from the conventional Diffusion Model. Throughout the training phase, ConsistencyDet initiates the diffusion sequence with noise-infused boxes derived from the ground-truth annotations and conditions the model to perform the denoising task. Subsequently, in the inference stage, the model employs a denoising sampling strategy that commences with bounding boxes randomly sampled from a normal distribution. Through iterative refinement, the model transforms an assortment of arbitrarily generated boxes into definitive detections. Comprehensive evaluations employing standard benchmarks, such as MS-COCO and LVIS, corroborate that ConsistencyDet surpasses other leading-edge detectors in performance metrics. Our code is available at https://github.com/Tankowa/ConsistencyDet.
ConsistencyDet: Robust Object Detector with Denoising Paradigm of Consistency Model
Apr 11, 2024Object detection, a quintessential task in the realm of perceptual computing, can be tackled using a generative methodology. In the present study, we introduce a novel framework designed to articulate object detection as a denoising diffusion process, which operates on perturbed bounding boxes of annotated entities. This framework, termed ConsistencyDet, leverages an innovative denoising concept known as the Consistency Model. The hallmark of this model is its self-consistency feature, which empowers the model to map distorted information from any temporal stage back to its pristine state, thereby realizing a ``one-step denoising'' mechanism. Such an attribute markedly elevates the operational efficiency of the model, setting it apart from the conventional Diffusion Model. Throughout the training phase, ConsistencyDet initiates the diffusion sequence with noise-infused boxes derived from the ground-truth annotations and conditions the model to perform the denoising task. Subsequently, in the inference stage, the model employs a denoising sampling strategy that commences with bounding boxes randomly sampled from a normal distribution. Through iterative refinement, the model transforms an assortment of arbitrarily generated boxes into the definitive detections. Comprehensive evaluations employing standard benchmarks, such as MS-COCO and LVIS, corroborate that ConsistencyDet surpasses other leading-edge detectors in performance metrics.
Improving Detection of ChatGPT-Generated Fake Science Using Real Publication Text: Introducing xFakeBibs a Supervised-Learning Network Algorithm
Aug 15, 2023ChatGPT is becoming a new reality. In this paper, we show how to distinguish ChatGPT-generated publications from counterparts produced by scientists. Using a newly designed supervised Machine Learning algorithm, we demonstrate how to detect machine-generated publications from those produced by scientists. The algorithm was trained using 100 real publication abstracts, followed by a 10-fold calibration approach to establish a lower-upper bound range of acceptance. In the comparison with ChatGPT content, it was evident that ChatGPT contributed merely 23\% of the bigram content, which is less than 50\% of any of the other 10 calibrating folds. This analysis highlights a significant disparity in technical terms where ChatGPT fell short of matching real science. When categorizing the individual articles, the xFakeBibs algorithm accurately identified 98 out of 100 publications as fake, with 2 articles incorrectly classified as real publications. Though this work introduced an algorithmic approach that detected the ChatGPT-generated fake science with a high degree of accuracy, it remains challenging to detect all fake records. This work is indeed a step in the right direction to counter fake science and misinformation.
ChatGPT is not Enough: Enhancing Large Language Models with Knowledge Graphs for Fact-aware Language Modeling
Jun 20, 2023Recently, ChatGPT, a representative large language model (LLM), has gained considerable attention due to its powerful emergent abilities. Some researchers suggest that LLMs could potentially replace structured knowledge bases like knowledge graphs (KGs) and function as parameterized knowledge bases. However, while LLMs are proficient at learning probabilistic language patterns based on large corpus and engaging in conversations with humans, they, like previous smaller pre-trained language models (PLMs), still have difficulty in recalling facts while generating knowledge-grounded contents. To overcome these limitations, researchers have proposed enhancing data-driven PLMs with knowledge-based KGs to incorporate explicit factual knowledge into PLMs, thus improving their performance to generate texts requiring factual knowledge and providing more informed responses to user queries. This paper reviews the studies on enhancing PLMs with KGs, detailing existing knowledge graph enhanced pre-trained language models (KGPLMs) as well as their applications. Inspired by existing studies on KGPLM, this paper proposes to enhance LLMs with KGs by developing knowledge graph-enhanced large language models (KGLLMs). KGLLM provides a solution to enhance LLMs' factual reasoning ability, opening up new avenues for LLM research.
Unifying Large Language Models and Knowledge Graphs: A Roadmap
Jun 20, 2023Large language models (LLMs), such as ChatGPT and GPT4, are making new waves in the field of natural language processing and artificial intelligence, due to their emergent ability and generalizability. However, LLMs are black-box models, which often fall short of capturing and accessing factual knowledge. In contrast, Knowledge Graphs (KGs), Wikipedia and Huapu for example, are structured knowledge models that explicitly store rich factual knowledge. KGs can enhance LLMs by providing external knowledge for inference and interpretability. Meanwhile, KGs are difficult to construct and evolving by nature, which challenges the existing methods in KGs to generate new facts and represent unseen knowledge. Therefore, it is complementary to unify LLMs and KGs together and simultaneously leverage their advantages. In this article, we present a forward-looking roadmap for the unification of LLMs and KGs. Our roadmap consists of three general frameworks, namely, 1) KG-enhanced LLMs, which incorporate KGs during the pre-training and inference phases of LLMs, or for the purpose of enhancing understanding of the knowledge learned by LLMs; 2) LLM-augmented KGs, that leverage LLMs for different KG tasks such as embedding, completion, construction, graph-to-text generation, and question answering; and 3) Synergized LLMs + KGs, in which LLMs and KGs play equal roles and work in a mutually beneficial way to enhance both LLMs and KGs for bidirectional reasoning driven by both data and knowledge. We review and summarize existing efforts within these three frameworks in our roadmap and pinpoint their future research directions.
Fair Causal Feature Selection
Jun 17, 2023



Causal feature selection has recently received increasing attention in machine learning. Existing causal feature selection algorithms select unique causal features of a class variable as the optimal feature subset. However, a class variable usually has multiple states, and it is unfair to select the same causal features for different states of a class variable. To address this problem, we employ the class-specific mutual information to evaluate the causal information carried by each state of the class attribute, and theoretically analyze the unique relationship between each state and the causal features. Based on this, a Fair Causal Feature Selection algorithm (FairCFS) is proposed to fairly identifies the causal features for each state of the class variable. Specifically, FairCFS uses the pairwise comparisons of class-specific mutual information and the size of class-specific mutual information values from the perspective of each state, and follows a divide-and-conquer framework to find causal features. The correctness and application condition of FairCFS are theoretically proved, and extensive experiments are conducted to demonstrate the efficiency and superiority of FairCFS compared to the state-of-the-art approaches.
A Comprehensive Survey on Automatic Knowledge Graph Construction
Feb 10, 2023Automatic knowledge graph construction aims to manufacture structured human knowledge. To this end, much effort has historically been spent extracting informative fact patterns from different data sources. However, more recently, research interest has shifted to acquiring conceptualized structured knowledge beyond informative data. In addition, researchers have also been exploring new ways of handling sophisticated construction tasks in diversified scenarios. Thus, there is a demand for a systematic review of paradigms to organize knowledge structures beyond data-level mentions. To meet this demand, we comprehensively survey more than 300 methods to summarize the latest developments in knowledge graph construction. A knowledge graph is built in three steps: knowledge acquisition, knowledge refinement, and knowledge evolution. The processes of knowledge acquisition are reviewed in detail, including obtaining entities with fine-grained types and their conceptual linkages to knowledge graphs; resolving coreferences; and extracting entity relationships in complex scenarios. The survey covers models for knowledge refinement, including knowledge graph completion, and knowledge fusion. Methods to handle knowledge evolution are also systematically presented, including condition knowledge acquisition, condition knowledge graph completion, and knowledge dynamic. We present the paradigms to compare the distinction among these methods along the axis of the data environment, motivation, and architecture. Additionally, we also provide briefs on accessible resources that can help readers to develop practical knowledge graph systems. The survey concludes with discussions on the challenges and possible directions for future exploration.
Block-Structured Optimization for Subgraph Detection in Interdependent Networks
Oct 06, 2022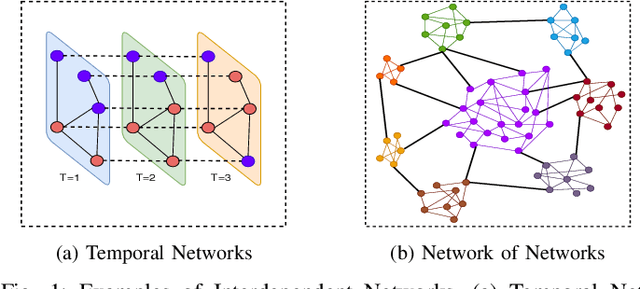
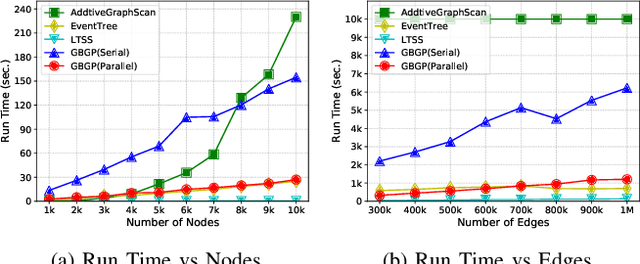
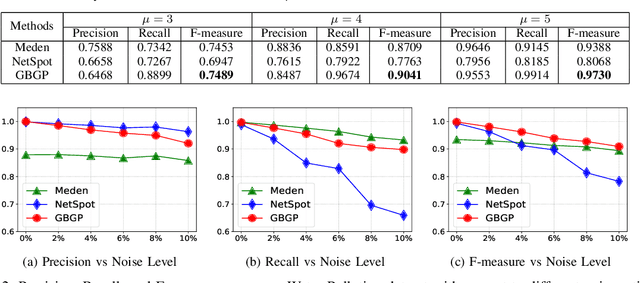
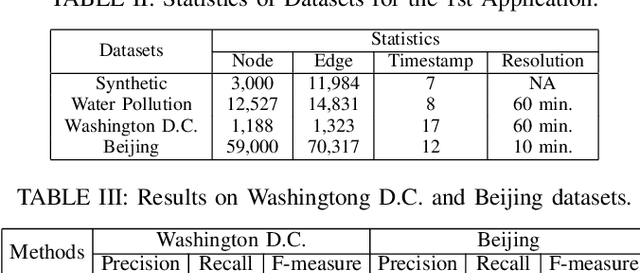
We propose a generalized framework for block-structured nonconvex optimization, which can be applied to structured subgraph detection in interdependent networks, such as multi-layer networks, temporal networks, networks of networks, and many others. Specifically, we design an effective, efficient, and parallelizable projection algorithm, namely Graph Block-structured Gradient Projection (GBGP), to optimize a general non-linear function subject to graph-structured constraints. We prove that our algorithm: 1) runs in nearly-linear time on the network size; 2) enjoys a theoretical approximation guarantee. Moreover, we demonstrate how our framework can be applied to two very practical applications and conduct comprehensive experiments to show the effectiveness and efficiency of our proposed algorithm.
Deep Forest with Hashing Screening and Window Screening
Jul 25, 2022
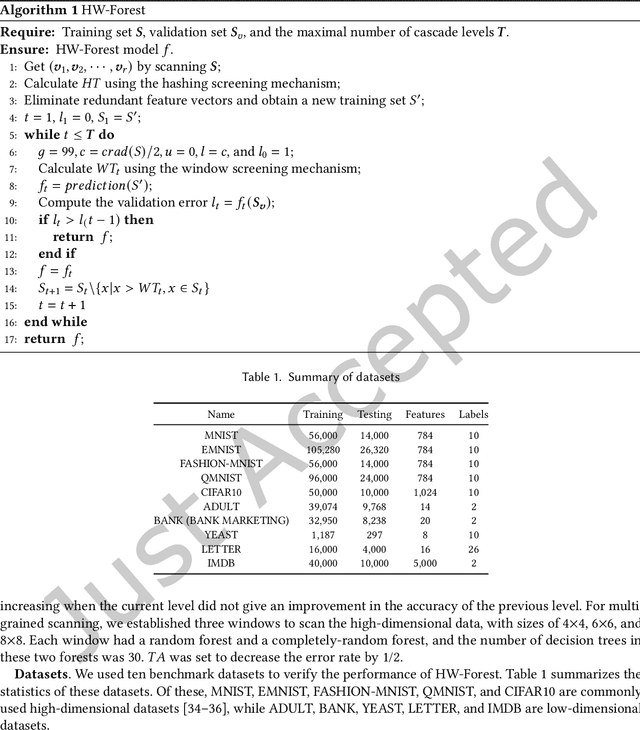
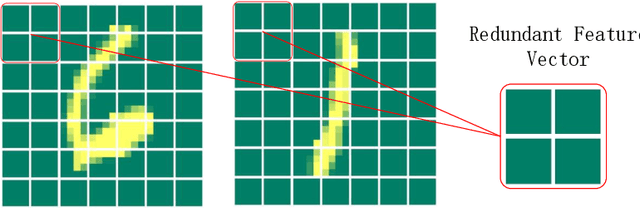
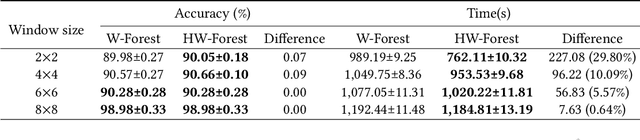
As a novel deep learning model, gcForest has been widely used in various applications. However, the current multi-grained scanning of gcForest produces many redundant feature vectors, and this increases the time cost of the model. To screen out redundant feature vectors, we introduce a hashing screening mechanism for multi-grained scanning and propose a model called HW-Forest which adopts two strategies, hashing screening and window screening. HW-Forest employs perceptual hashing algorithm to calculate the similarity between feature vectors in hashing screening strategy, which is used to remove the redundant feature vectors produced by multi-grained scanning and can significantly decrease the time cost and memory consumption. Furthermore, we adopt a self-adaptive instance screening strategy to improve the performance of our approach, called window screening, which can achieve higher accuracy without hyperparameter tuning on different datasets. Our experimental results show that HW-Forest has higher accuracy than other models, and the time cost is also reduced.
Embedding Knowledge for Document Summarization: A Survey
Apr 24, 2022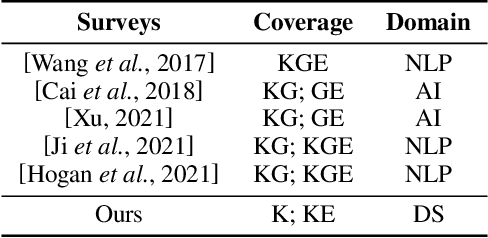
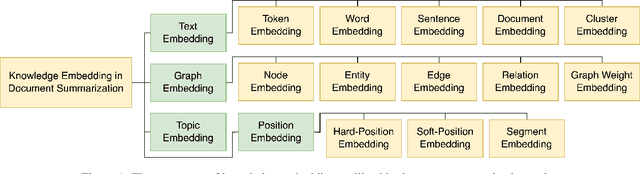
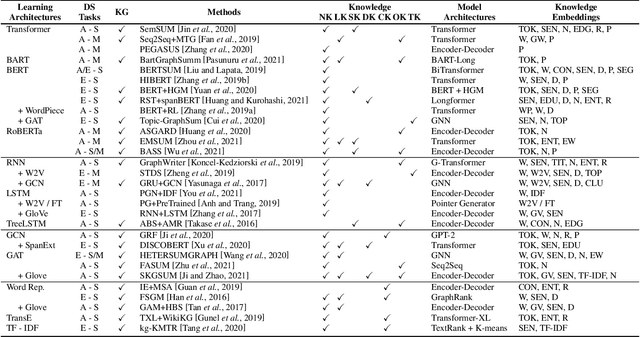
Knowledge-aware methods have boosted a range of Natural Language Processing applications over the last decades. With the gathered momentum, knowledge recently has been pumped into enormous attention in document summarization research. Previous works proved that knowledge-embedded document summarizers excel at generating superior digests, especially in terms of informativeness, coherence, and fact consistency. This paper pursues to present the first systematic survey for the state-of-the-art methodologies that embed knowledge into document summarizers. Particularly, we propose novel taxonomies to recapitulate knowledge and knowledge embeddings under the document summarization view. We further explore how embeddings are generated in learning architectures of document summarization models, especially in deep learning models. At last, we discuss the challenges of this topic and future directions.