 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Data to Insights: Exploring Program-of-Thoughts Prompting for Chart Summarization
May 25, 2026Charts play a critical role in conveying numerical data insights through structured visual representations. However, semantic visual understanding and numerical reasoning requirements hinder the accurate description of charts, interpreting a challenging task in chart summarization. Despite recent advancements in visual language models (VLMs), approaches lack robust mechanisms for verifying statistical fact correctness and are computationally heavy. To address this gap, this paper explores a strategy of using zero-shot learning to motivate the lightweight VLMs to perform computational reasoning, via Python programs as intermediaries to derive valid summary statistics for chart understanding. Specifically, we introduce a novel chart-to-dictionary auxiliary task, offering a more flexible representation compared to traditional chart-to-table methods, making it particularly well-suited for integration with the Program-of-Thought (PoT) strategy. Experimental results demonstrate our strategy performs on par with existing chart summarization methods across semantic and factual metrics. Code is available on https://anonymous.4open.science/r/ZeroShot-PoT-C2T-5A6B.
Document-aware Positional Encoding and Linguistic-guided Encoding for Abstractive Multi-document Summarization
Sep 13, 2022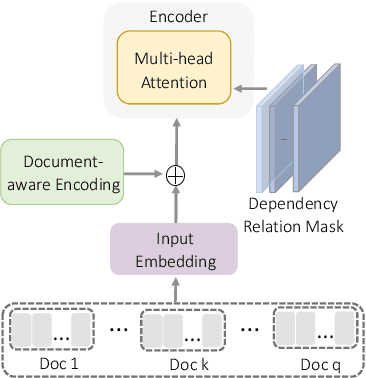
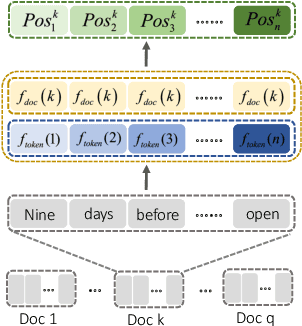
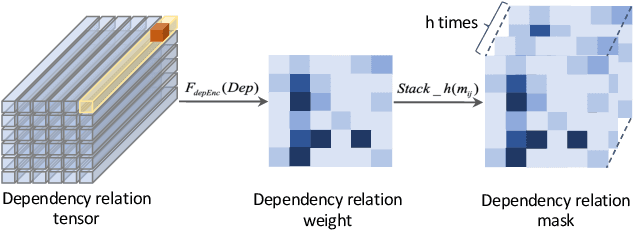
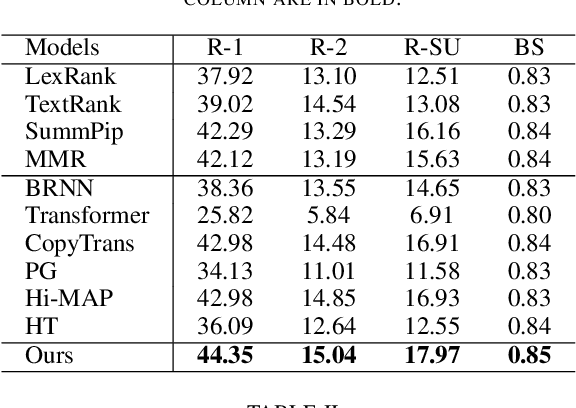
One key challenge in multi-document summarization is to capture the relations among input documents that distinguish between single document summarization (SDS) and multi-document summarization (MDS). Few existing MDS works address this issue. One effective way is to encode document positional information to assist models in capturing cross-document relations. However, existing MDS models, such as Transformer-based models, only consider token-level positional information. Moreover, these models fail to capture sentences' linguistic structure, which inevitably causes confusions in the generated summaries. Therefore, in this paper, we propose document-aware positional encoding and linguistic-guided encoding that can be fused with Transformer architecture for MDS. For document-aware positional encoding, we introduce a general protocol to guide the selection of document encoding functions. For linguistic-guided encoding, we propose to embed syntactic dependency relations into the dependency relation mask with a simple but effective non-linear encoding learner for feature learning. Extensive experiments show the proposed model can generate summaries with high quality.
Embedding Knowledge for Document Summarization: A Survey
Apr 24, 2022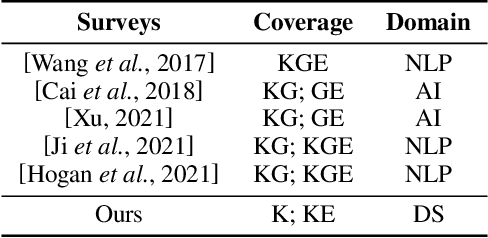
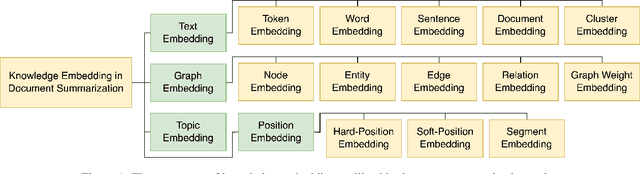
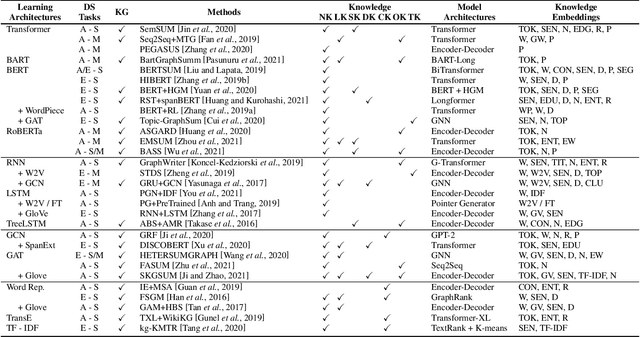
Knowledge-aware methods have boosted a range of Natural Language Processing applications over the last decades. With the gathered momentum, knowledge recently has been pumped into enormous attention in document summarization research. Previous works proved that knowledge-embedded document summarizers excel at generating superior digests, especially in terms of informativeness, coherence, and fact consistency. This paper pursues to present the first systematic survey for the state-of-the-art methodologies that embed knowledge into document summarizers. Particularly, we propose novel taxonomies to recapitulate knowledge and knowledge embeddings under the document summarization view. We further explore how embeddings are generated in learning architectures of document summarization models, especially in deep learning models. At last, we discuss the challenges of this topic and future directions.