 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOASIS: Harnessing Diffusion Adversarial Network for Ocean Salinity Imputation using Sparse Drifter Trajectories
Aug 29, 2025Ocean salinity plays a vital role in circulation, climate, and marine ecosystems, yet its measurement is often sparse, irregular, and noisy, especially in drifter-based datasets. Traditional approaches, such as remote sensing and optimal interpolation, rely on linearity and stationarity, and are limited by cloud cover, sensor drift, and low satellite revisit rates. While machine learning models offer flexibility, they often fail under severe sparsity and lack principled ways to incorporate physical covariates without specialized sensors. In this paper, we introduce the OceAn Salinity Imputation System (OASIS), a novel diffusion adversarial framework designed to address these challenges.
Topology-aware Neural Flux Prediction Guided by Physics
Jun 06, 2025Graph Neural Networks (GNNs) often struggle in preserving high-frequency components of nodal signals when dealing with directed graphs. Such components are crucial for modeling flow dynamics, without which a traditional GNN tends to treat a graph with forward and reverse topologies equal.To make GNNs sensitive to those high-frequency components thereby being capable to capture detailed topological differences, this paper proposes a novel framework that combines 1) explicit difference matrices that model directional gradients and 2) implicit physical constraints that enforce messages passing within GNNs to be consistent with natural laws. Evaluations on two real-world directed graph data, namely, water flux network and urban traffic flow network, demonstrate the effectiveness of our proposal.
TransFair: Transferring Fairness from Ocular Disease Classification to Progression Prediction
Dec 03, 2024



The use of artificial intelligence (AI) in automated disease classification significantly reduces healthcare costs and improves the accessibility of services. However, this transformation has given rise to concerns about the fairness of AI, which disproportionately affects certain groups, particularly patients from underprivileged populations. Recently, a number of methods and large-scale datasets have been proposed to address group performance disparities. Although these methods have shown effectiveness in disease classification tasks, they may fall short in ensuring fair prediction of disease progression, mainly because of limited longitudinal data with diverse demographics available for training a robust and equitable prediction model. In this paper, we introduce TransFair to enhance demographic fairness in progression prediction for ocular diseases. TransFair aims to transfer a fairness-enhanced disease classification model to the task of progression prediction with fairness preserved. Specifically, we train a fair EfficientNet, termed FairEN, equipped with a fairness-aware attention mechanism using extensive data for ocular disease classification. Subsequently, this fair classification model is adapted to a fair progression prediction model through knowledge distillation, which aims to minimize the latent feature distances between the classification and progression prediction models. We evaluate FairEN and TransFair for fairness-enhanced ocular disease classification and progression prediction using both two-dimensional (2D) and 3D retinal images. Extensive experiments and comparisons with models with and without considering fairness learning show that TransFair effectively enhances demographic equity in predicting ocular disease progression.
LLMGeo: Benchmarking Large Language Models on Image Geolocation In-the-wild
May 30, 2024



Image geolocation is a critical task in various image-understanding applications. However, existing methods often fail when analyzing challenging, in-the-wild images. Inspired by the exceptional background knowledge of multimodal language models, we systematically evaluate their geolocation capabilities using a novel image dataset and a comprehensive evaluation framework. We first collect images from various countries via Google Street View. Then, we conduct training-free and training-based evaluations on closed-source and open-source multi-modal language models. we conduct both training-free and training-based evaluations on closed-source and open-source multimodal language models. Our findings indicate that closed-source models demonstrate superior geolocation abilities, while open-source models can achieve comparable performance through fine-tuning.
ATNPA: A Unified View of Oversmoothing Alleviation in Graph Neural Networks
May 02, 2024Oversmoothing is a commonly observed challenge in graph neural network (GNN) learning, where, as layers increase, embedding features learned from GNNs quickly become similar/indistinguishable, making them incapable of differentiating network proximity. A GNN with shallow layer architectures can only learn short-term relation or localized structure information, limiting its power of learning long-term connection, evidenced by their inferior learning performance on heterophilous graphs. Tackling oversmoothing is crucial to harness deep-layer architectures for GNNs. To date, many methods have been proposed to alleviate oversmoothing. The vast difference behind their design principles, combined with graph complications, make it difficult to understand and even compare their difference in tackling the oversmoothing. In this paper, we propose ATNPA, a unified view with five key steps: Augmentation, Transformation, Normalization, Propagation, and Aggregation, to summarize GNN oversmoothing alleviation approaches. We first outline three themes to tackle oversmoothing, and then separate all methods into six categories, followed by detailed reviews of representative methods, including their relation to the ATNPA, and discussion about their niche, strength, and weakness. The review not only draws in-depth understanding of existing methods in the field, but also shows a clear road map for future study.
Graph Learning under Distribution Shifts: A Comprehensive Survey on Domain Adaptation, Out-of-distribution, and Continual Learning
Mar 07, 2024



Graph learning plays a pivotal role and has gained significant attention in various application scenarios, from social network analysis to recommendation systems, for its effectiveness in modeling complex data relations represented by graph structural data. In reality, the real-world graph data typically show dynamics over time, with changing node attributes and edge structure, leading to the severe graph data distribution shift issue. This issue is compounded by the diverse and complex nature of distribution shifts, which can significantly impact the performance of graph learning methods in degraded generalization and adaptation capabilities, posing a substantial challenge to their effectiveness. In this survey, we provide a comprehensive review and summary of the latest approaches, strategies, and insights that address distribution shifts within the context of graph learning. Concretely, according to the observability of distributions in the inference stage and the availability of sufficient supervision information in the training stage, we categorize existing graph learning methods into several essential scenarios, including graph domain adaptation learning, graph out-of-distribution learning, and graph continual learning. For each scenario, a detailed taxonomy is proposed, with specific descriptions and discussions of existing progress made in distribution-shifted graph learning. Additionally, we discuss the potential applications and future directions for graph learning under distribution shifts with a systematic analysis of the current state in this field. The survey is positioned to provide general guidance for the development of effective graph learning algorithms in handling graph distribution shifts, and to stimulate future research and advancements in this area.
Counting Manatee Aggregations using Deep Neural Networks and Anisotropic Gaussian Kernel
Nov 04, 2023Manatees are aquatic mammals with voracious appetites. They rely on sea grass as the main food source, and often spend up to eight hours a day grazing. They move slow and frequently stay in group (i.e. aggregations) in shallow water to search for food, making them vulnerable to environment change and other risks. Accurate counting manatee aggregations within a region is not only biologically meaningful in observing their habit, but also crucial for designing safety rules for human boaters, divers, etc., as well as scheduling nursing, intervention, and other plans. In this paper, we propose a deep learning based crowd counting approach to automatically count number of manatees within a region, by using low quality images as input. Because manatees have unique shape and they often stay in shallow water in groups, water surface reflection, occlusion, camouflage etc. making it difficult to accurately count manatee numbers. To address the challenges, we propose to use Anisotropic Gaussian Kernel (AGK), with tunable rotation and variances, to ensure that density functions can maximally capture shapes of individual manatees in different aggregations. After that, we apply AGK kernel to different types of deep neural networks primarily designed for crowd counting, including VGG, SANet, Congested Scene Recognition network (CSRNet), MARUNet etc. to learn manatee densities and calculate number of manatees in the scene. By using generic low quality images extracted from surveillance videos, our experiment results and comparison show that AGK kernel based manatee counting achieves minimum Mean Absolute Error (MAE) and Root Mean Square Error (RMSE). The proposed method works particularly well for counting manatee aggregations in environments with complex background.
Structure-free Graph Condensation: From Large-scale Graphs to Condensed Graph-free Data
Jun 05, 2023



Graph condensation, which reduces the size of a large-scale graph by synthesizing a small-scale condensed graph as its substitution, has immediate benefits for various graph learning tasks. However, existing graph condensation methods rely on the joint optimization of nodes and structures in the condensed graph, and overlook critical issues in effectiveness and generalization ability. In this paper, we advocate a new Structure-Free Graph Condensation paradigm, named SFGC, to distill a large-scale graph into a small-scale graph node set without explicit graph structures, i.e., graph-free data. Our idea is to implicitly encode topology structure information into the node attributes in the synthesized graph-free data, whose topology is reduced to an identity matrix. Specifically, SFGC contains two collaborative components: (1) a training trajectory meta-matching scheme for effectively synthesizing small-scale graph-free data; (2) a graph neural feature score metric for dynamically evaluating the quality of the condensed data. Through training trajectory meta-matching, SFGC aligns the long-term GNN learning behaviors between the large-scale graph and the condensed small-scale graph-free data, ensuring comprehensive and compact transfer of informative knowledge to the graph-free data. Afterward, the underlying condensed graph-free data would be dynamically evaluated with the graph neural feature score, which is a closed-form metric for ensuring the excellent expressiveness of the condensed graph-free data. Extensive experiments verify the superiority of SFGC across different condensation ratios.
Local Contrastive Feature learning for Tabular Data
Nov 19, 2022Contrastive self-supervised learning has been successfully used in many domains, such as images, texts, graphs, etc., to learn features without requiring label information. In this paper, we propose a new local contrastive feature learning (LoCL) framework, and our theme is to learn local patterns/features from tabular data. In order to create a niche for local learning, we use feature correlations to create a maximum-spanning tree, and break the tree into feature subsets, with strongly correlated features being assigned next to each other. Convolutional learning of the features is used to learn latent feature space, regulated by contrastive and reconstruction losses. Experiments on public tabular datasets show the effectiveness of the proposed method versus state-of-the-art baseline methods.
Deep Forest with Hashing Screening and Window Screening
Jul 25, 2022
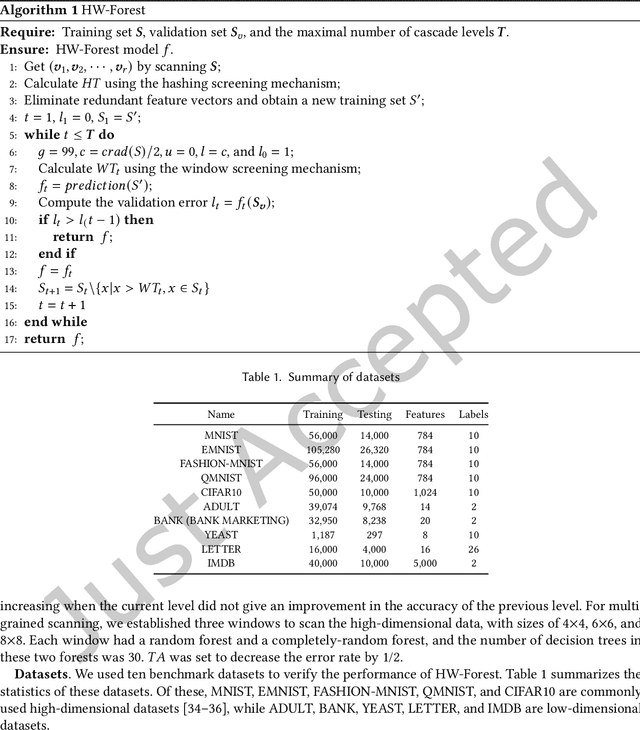
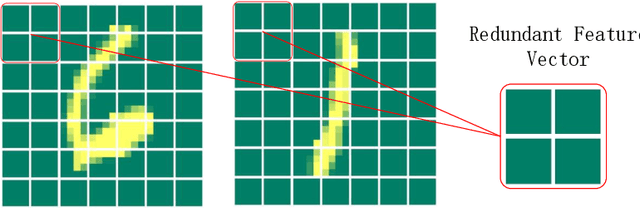
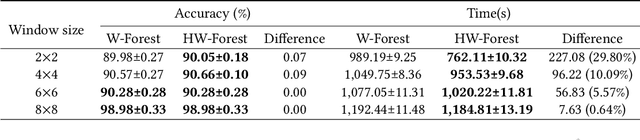
As a novel deep learning model, gcForest has been widely used in various applications. However, the current multi-grained scanning of gcForest produces many redundant feature vectors, and this increases the time cost of the model. To screen out redundant feature vectors, we introduce a hashing screening mechanism for multi-grained scanning and propose a model called HW-Forest which adopts two strategies, hashing screening and window screening. HW-Forest employs perceptual hashing algorithm to calculate the similarity between feature vectors in hashing screening strategy, which is used to remove the redundant feature vectors produced by multi-grained scanning and can significantly decrease the time cost and memory consumption. Furthermore, we adopt a self-adaptive instance screening strategy to improve the performance of our approach, called window screening, which can achieve higher accuracy without hyperparameter tuning on different datasets. Our experimental results show that HW-Forest has higher accuracy than other models, and the time cost is also reduced.