 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrainable Projected Gradient Method for Robust Fine-tuning
Mar 28, 2023Recent studies on transfer learning have shown that selectively fine-tuning a subset of layers or customizing different learning rates for each layer can greatly improve robustness to out-of-distribution (OOD) data and retain generalization capability in the pre-trained models. However, most of these methods employ manually crafted heuristics or expensive hyper-parameter searches, which prevent them from scaling up to large datasets and neural networks. To solve this problem, we propose Trainable Projected Gradient Method (TPGM) to automatically learn the constraint imposed for each layer for a fine-grained fine-tuning regularization. This is motivated by formulating fine-tuning as a bi-level constrained optimization problem. Specifically, TPGM maintains a set of projection radii, i.e., distance constraints between the fine-tuned model and the pre-trained model, for each layer, and enforces them through weight projections. To learn the constraints, we propose a bi-level optimization to automatically learn the best set of projection radii in an end-to-end manner. Theoretically, we show that the bi-level optimization formulation could explain the regularization capability of TPGM. Empirically, with little hyper-parameter search cost, TPGM outperforms existing fine-tuning methods in OOD performance while matching the best in-distribution (ID) performance. For example, when fine-tuned on DomainNet-Real and ImageNet, compared to vanilla fine-tuning, TPGM shows $22\%$ and $10\%$ relative OOD improvement respectively on their sketch counterparts. Code is available at \url{https://github.com/PotatoTian/TPGM}.
* Accepted to CVPR2023
Mask3D: Pre-training 2D Vision Transformers by Learning Masked 3D Priors
Feb 28, 2023



Current popular backbones in computer vision, such as Vision Transformers (ViT) and ResNets are trained to perceive the world from 2D images. However, to more effectively understand 3D structural priors in 2D backbones, we propose Mask3D to leverage existing large-scale RGB-D data in a self-supervised pre-training to embed these 3D priors into 2D learned feature representations. In contrast to traditional 3D contrastive learning paradigms requiring 3D reconstructions or multi-view correspondences, our approach is simple: we formulate a pre-text reconstruction task by masking RGB and depth patches in individual RGB-D frames. We demonstrate the Mask3D is particularly effective in embedding 3D priors into the powerful 2D ViT backbone, enabling improved representation learning for various scene understanding tasks, such as semantic segmentation, instance segmentation and object detection. Experiments show that Mask3D notably outperforms existing self-supervised 3D pre-training approaches on ScanNet, NYUv2, and Cityscapes image understanding tasks, with an improvement of +6.5% mIoU against the state-of-the-art Pri3D on ScanNet image semantic segmentation.
Pruning Compact ConvNets for Efficient Inference
Jan 11, 2023Neural network pruning is frequently used to compress over-parameterized networks by large amounts, while incurring only marginal drops in generalization performance. However, the impact of pruning on networks that have been highly optimized for efficient inference has not received the same level of attention. In this paper, we analyze the effect of pruning for computer vision, and study state-of-the-art ConvNets, such as the FBNetV3 family of models. We show that model pruning approaches can be used to further optimize networks trained through NAS (Neural Architecture Search). The resulting family of pruned models can consistently obtain better performance than existing FBNetV3 models at the same level of computation, and thus provide state-of-the-art results when trading off between computational complexity and generalization performance on the ImageNet benchmark. In addition to better generalization performance, we also demonstrate that when limited computation resources are available, pruning FBNetV3 models incur only a fraction of GPU-hours involved in running a full-scale NAS.
Castling-ViT: Compressing Self-Attention via Switching Towards Linear-Angular Attention During Vision Transformer Inference
Nov 18, 2022



Vision Transformers (ViTs) have shown impressive performance but still require a high computation cost as compared to convolutional neural networks (CNNs), due to the global similarity measurements and thus a quadratic complexity with the input tokens. Existing efficient ViTs adopt local attention (e.g., Swin) or linear attention (e.g., Performer), which sacrifice ViTs' capabilities of capturing either global or local context. In this work, we ask an important research question: Can ViTs learn both global and local context while being more efficient during inference? To this end, we propose a framework called Castling-ViT, which trains ViTs using both linear-angular attention and masked softmax-based quadratic attention, but then switches to having only linear angular attention during ViT inference. Our Castling-ViT leverages angular kernels to measure the similarities between queries and keys via spectral angles. And we further simplify it with two techniques: (1) a novel linear-angular attention mechanism: we decompose the angular kernels into linear terms and high-order residuals, and only keep the linear terms; and (2) we adopt two parameterized modules to approximate high-order residuals: a depthwise convolution and an auxiliary masked softmax attention to help learn both global and local information, where the masks for softmax attention are regularized to gradually become zeros and thus incur no overhead during ViT inference. Extensive experiments and ablation studies on three tasks consistently validate the effectiveness of the proposed Castling-ViT, e.g., achieving up to a 1.8% higher accuracy or 40% MACs reduction on ImageNet classification and 1.2 higher mAP on COCO detection under comparable FLOPs, as compared to ViTs with vanilla softmax-based attentions.
3D-Aware Encoding for Style-based Neural Radiance Fields
Nov 12, 2022



We tackle the task of NeRF inversion for style-based neural radiance fields, (e.g., StyleNeRF). In the task, we aim to learn an inversion function to project an input image to the latent space of a NeRF generator and then synthesize novel views of the original image based on the latent code. Compared with GAN inversion for 2D generative models, NeRF inversion not only needs to 1) preserve the identity of the input image, but also 2) ensure 3D consistency in generated novel views. This requires the latent code obtained from the single-view image to be invariant across multiple views. To address this new challenge, we propose a two-stage encoder for style-based NeRF inversion. In the first stage, we introduce a base encoder that converts the input image to a latent code. To ensure the latent code is view-invariant and is able to synthesize 3D consistent novel view images, we utilize identity contrastive learning to train the base encoder. Second, to better preserve the identity of the input image, we introduce a refining encoder to refine the latent code and add finer details to the output image. Importantly note that the novelty of this model lies in the design of its first-stage encoder which produces the closest latent code lying on the latent manifold and thus the refinement in the second stage would be close to the NeRF manifold. Through extensive experiments, we demonstrate that our proposed two-stage encoder qualitatively and quantitatively exhibits superiority over the existing encoders for inversion in both image reconstruction and novel-view rendering.
Token Merging: Your ViT But Faster
Oct 17, 2022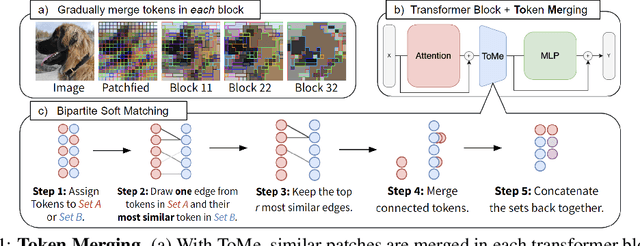
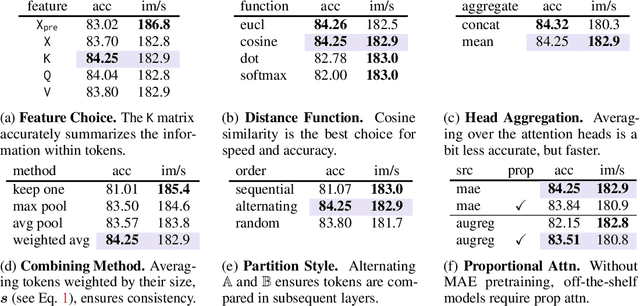
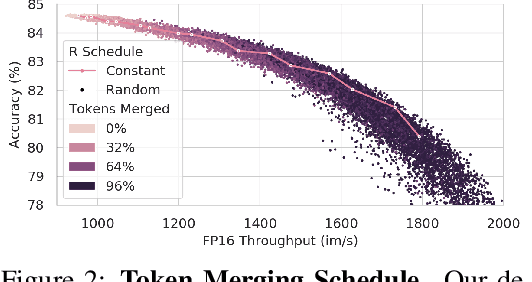

We introduce Token Merging (ToMe), a simple method to increase the throughput of existing ViT models without needing to train. ToMe gradually combines similar tokens in a transformer using a general and light-weight matching algorithm that is as fast as pruning while being more accurate. Off-the-shelf, ToMe can 2x the throughput of state-of-the-art ViT-L @ 512 and ViT-H @ 518 models on images and 2.2x the throughput of ViT-L on video with only a 0.2-0.3% accuracy drop in each case. ToMe can also easily be applied during training, improving in practice training speed up to 2x for MAE fine-tuning on video. Training with ToMe further minimizes accuracy drop, leading to 2x the throughput of ViT-B on audio for only a 0.4% mAP drop. Qualitatively, we find that ToMe merges object parts into one token, even over multiple frames of video. Overall, ToMe's accuracy and speed are competitive with state-of-the-art on images, video, and audio.
Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP
Oct 09, 2022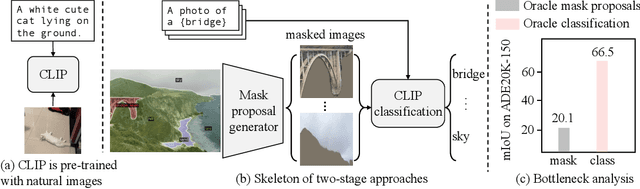
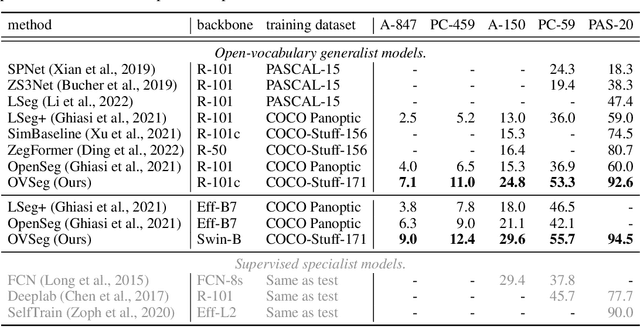
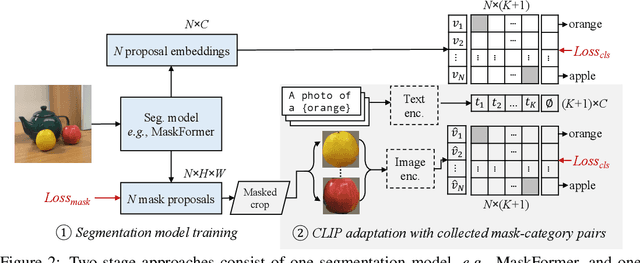
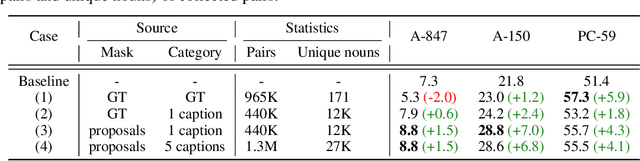
Open-vocabulary semantic segmentation aims to segment an image into semantic regions according to text descriptions, which may not have been seen during training. Recent two-stage methods first generate class-agnostic mask proposals and then leverage pre-trained vision-language models, e.g., CLIP, to classify masked regions. We identify the performance bottleneck of this paradigm to be the pre-trained CLIP model, since it does not perform well on masked images. To address this, we propose to finetune CLIP on a collection of masked image regions and their corresponding text descriptions. We collect training data by mining an existing image-caption dataset (e.g., COCO Captions), using CLIP to match masked image regions to nouns in the image captions. Compared with the more precise and manually annotated segmentation labels with fixed classes (e.g., COCO-Stuff), we find our noisy but diverse dataset can better retain CLIP's generalization ability. Along with finetuning the entire model, we utilize the "blank" areas in masked images using a method we dub mask prompt tuning. Experiments demonstrate mask prompt tuning brings significant improvement without modifying any weights of CLIP, and it can further improve a fully finetuned model. In particular, when trained on COCO and evaluated on ADE20K-150, our best model achieves 29.6% mIoU, which is +8.5% higher than the previous state-of-the-art. For the first time, open-vocabulary generalist models match the performance of supervised specialist models in 2017 without dataset-specific adaptations.
Hydra Attention: Efficient Attention with Many Heads
Sep 15, 2022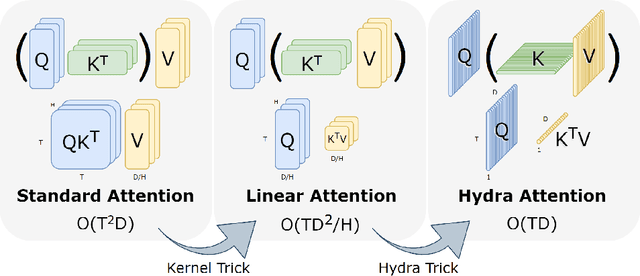

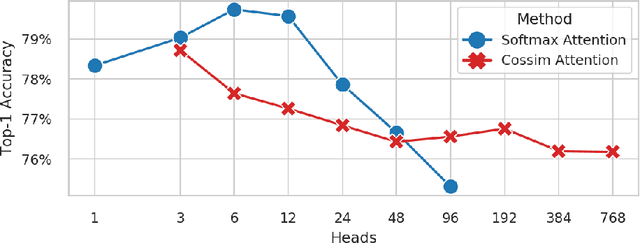
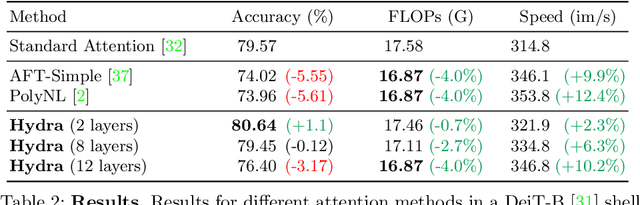
While transformers have begun to dominate many tasks in vision, applying them to large images is still computationally difficult. A large reason for this is that self-attention scales quadratically with the number of tokens, which in turn, scales quadratically with the image size. On larger images (e.g., 1080p), over 60% of the total computation in the network is spent solely on creating and applying attention matrices. We take a step toward solving this issue by introducing Hydra Attention, an extremely efficient attention operation for Vision Transformers (ViTs). Paradoxically, this efficiency comes from taking multi-head attention to its extreme: by using as many attention heads as there are features, Hydra Attention is computationally linear in both tokens and features with no hidden constants, making it significantly faster than standard self-attention in an off-the-shelf ViT-B/16 by a factor of the token count. Moreover, Hydra Attention retains high accuracy on ImageNet and, in some cases, actually improves it.
Open-Set Semi-Supervised Object Detection
Aug 29, 2022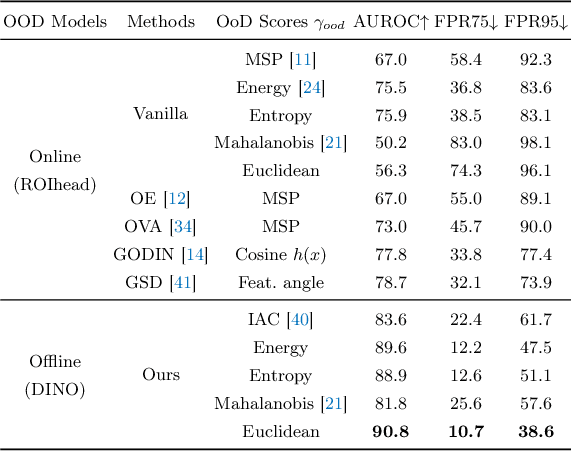



Recent developments for Semi-Supervised Object Detection (SSOD) have shown the promise of leveraging unlabeled data to improve an object detector. However, thus far these methods have assumed that the unlabeled data does not contain out-of-distribution (OOD) classes, which is unrealistic with larger-scale unlabeled datasets. In this paper, we consider a more practical yet challenging problem, Open-Set Semi-Supervised Object Detection (OSSOD). We first find the existing SSOD method obtains a lower performance gain in open-set conditions, and this is caused by the semantic expansion, where the distracting OOD objects are mispredicted as in-distribution pseudo-labels for the semi-supervised training. To address this problem, we consider online and offline OOD detection modules, which are integrated with SSOD methods. With the extensive studies, we found that leveraging an offline OOD detector based on a self-supervised vision transformer performs favorably against online OOD detectors due to its robustness to the interference of pseudo-labeling. In the experiment, our proposed framework effectively addresses the semantic expansion issue and shows consistent improvements on many OSSOD benchmarks, including large-scale COCO-OpenImages. We also verify the effectiveness of our framework under different OSSOD conditions, including varying numbers of in-distribution classes, different degrees of supervision, and different combinations of unlabeled sets.
NASRec: Weight Sharing Neural Architecture Search for Recommender Systems
Jul 14, 2022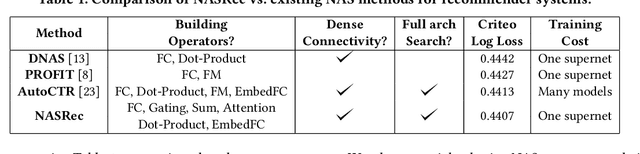
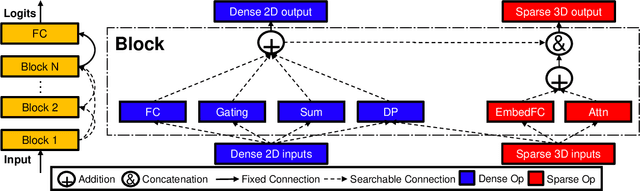
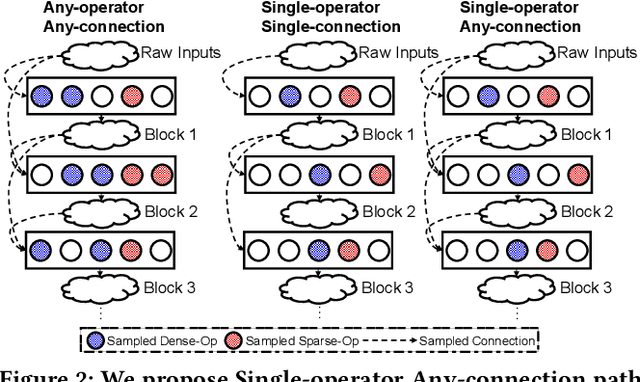

The rise of deep neural networks provides an important driver in optimizing recommender systems. However, the success of recommender systems lies in delicate architecture fabrication, and thus calls for Neural Architecture Search (NAS) to further improve its modeling. We propose NASRec, a paradigm that trains a single supernet and efficiently produces abundant models/sub-architectures by weight sharing. To overcome the data multi-modality and architecture heterogeneity challenges in recommendation domain, NASRec establishes a large supernet (i.e., search space) to search the full architectures, with the supernet incorporating versatile operator choices and dense connectivity minimizing human prior for flexibility. The scale and heterogeneity in NASRec impose challenges in search, such as training inefficiency, operator-imbalance, and degraded rank correlation. We tackle these challenges by proposing single-operator any-connection sampling, operator-balancing interaction modules, and post-training fine-tuning. Our results on three Click-Through Rates (CTR) prediction benchmarks show that NASRec can outperform both manually designed models and existing NAS methods, achieving state-of-the-art performance.