 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne for All, All for One: Learning and Transferring User Embeddings for Cross-Domain Recommendation
Nov 22, 2022Cross-domain recommendation is an important method to improve recommender system performance, especially when observations in target domains are sparse. However, most existing techniques focus on single-target or dual-target cross-domain recommendation (CDR) and are hard to be generalized to CDR with multiple target domains. In addition, the negative transfer problem is prevalent in CDR, where the recommendation performance in a target domain may not always be enhanced by knowledge learned from a source domain, especially when the source domain has sparse data. In this study, we propose CAT-ART, a multi-target CDR method that learns to improve recommendations in all participating domains through representation learning and embedding transfer. Our method consists of two parts: a self-supervised Contrastive AuToencoder (CAT) framework to generate global user embeddings based on information from all participating domains, and an Attention-based Representation Transfer (ART) framework which transfers domain-specific user embeddings from other domains to assist with target domain recommendation. CAT-ART boosts the recommendation performance in any target domain through the combined use of the learned global user representation and knowledge transferred from other domains, in addition to the original user embedding in the target domain. We conducted extensive experiments on a collected real-world CDR dataset spanning 5 domains and involving a million users. Experimental results demonstrate the superiority of the proposed method over a range of prior arts. We further conducted ablation studies to verify the effectiveness of the proposed components. Our collected dataset will be open-sourced to facilitate future research in the field of multi-domain recommender systems and user modeling.
Tenrec: A Large-scale Multipurpose Benchmark Dataset for Recommender Systems
Oct 20, 2022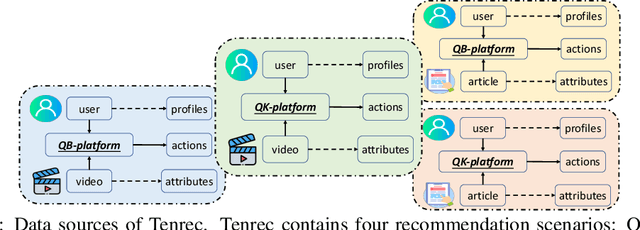
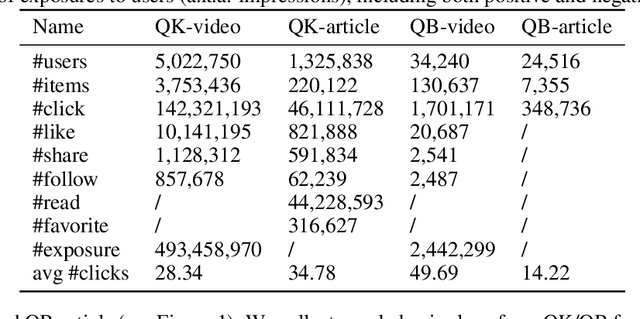
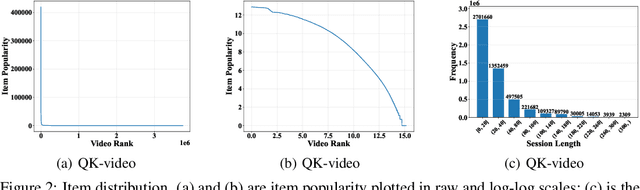

Existing benchmark datasets for recommender systems (RS) either are created at a small scale or involve very limited forms of user feedback. RS models evaluated on such datasets often lack practical values for large-scale real-world applications. In this paper, we describe Tenrec, a novel and publicly available data collection for RS that records various user feedback from four different recommendation scenarios. To be specific, Tenrec has the following five characteristics: (1) it is large-scale, containing around 5 million users and 140 million interactions; (2) it has not only positive user feedback, but also true negative feedback (vs. one-class recommendation); (3) it contains overlapped users and items across four different scenarios; (4) it contains various types of user positive feedback, in forms of clicks, likes, shares, and follows, etc; (5) it contains additional features beyond the user IDs and item IDs. We verify Tenrec on ten diverse recommendation tasks by running several classical baseline models per task. Tenrec has the potential to become a useful benchmark dataset for a majority of popular recommendation tasks.
Weakly-supervised Action Localization via Hierarchical Mining
Jun 22, 2022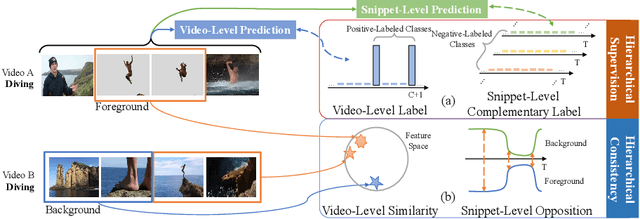
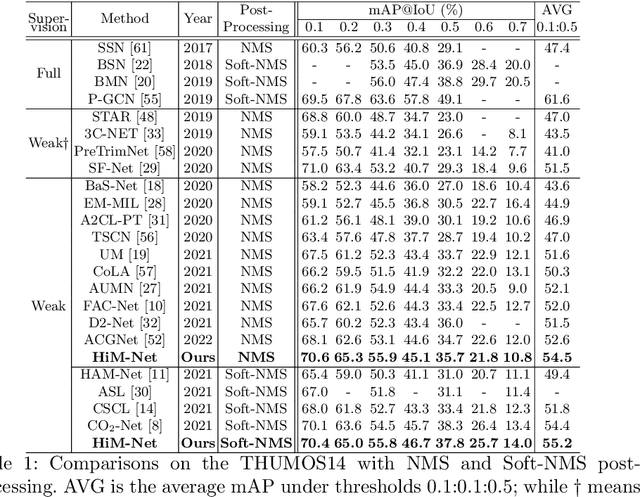
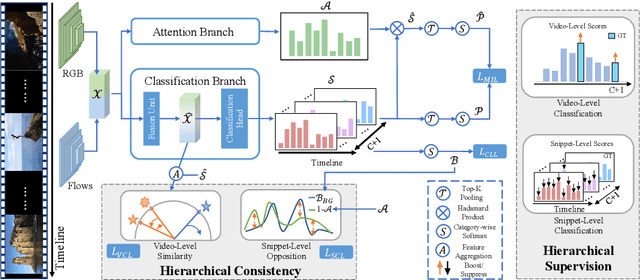
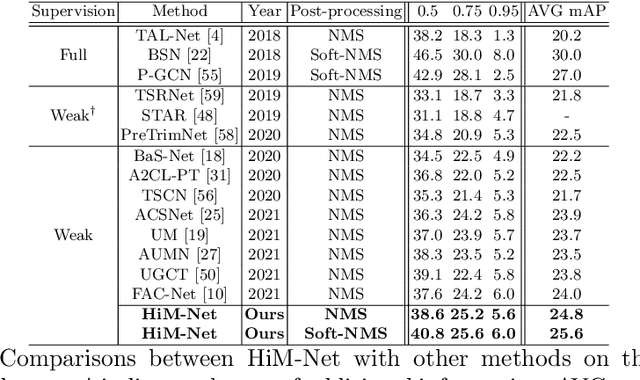
Weakly-supervised action localization aims to localize and classify action instances in the given videos temporally with only video-level categorical labels. Thus, the crucial issue of existing weakly-supervised action localization methods is the limited supervision from the weak annotations for precise predictions. In this work, we propose a hierarchical mining strategy under video-level and snippet-level manners, i.e., hierarchical supervision and hierarchical consistency mining, to maximize the usage of the given annotations and prediction-wise consistency. To this end, a Hierarchical Mining Network (HiM-Net) is proposed. Concretely, it mines hierarchical supervision for classification in two grains: one is the video-level existence for ground truth categories captured by multiple instance learning; the other is the snippet-level inexistence for each negative-labeled category from the perspective of complementary labels, which is optimized by our proposed complementary label learning. As for hierarchical consistency, HiM-Net explores video-level co-action feature similarity and snippet-level foreground-background opposition, for discriminative representation learning and consistent foreground-background separation. Specifically, prediction variance is viewed as uncertainty to select the pairs with high consensus for proposed foreground-background collaborative learning. Comprehensive experimental results show that HiM-Net outperforms existing methods on THUMOS14 and ActivityNet1.3 datasets with large margins by hierarchically mining the supervision and consistency. Code will be available on GitHub.
DeVRF: Fast Deformable Voxel Radiance Fields for Dynamic Scenes
Jun 04, 2022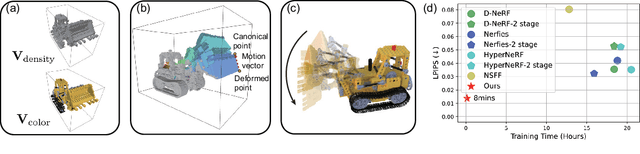
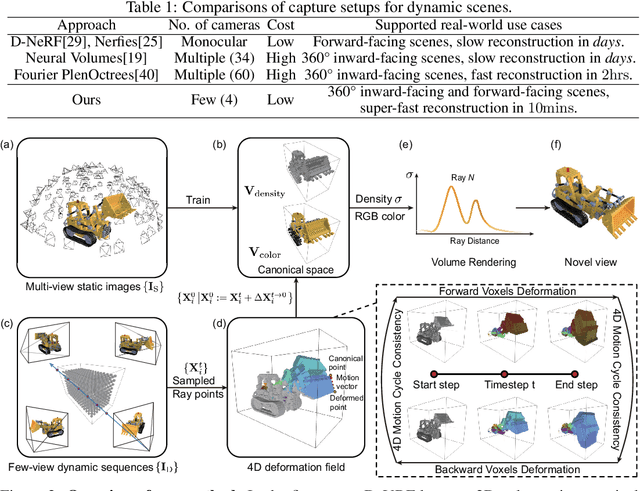
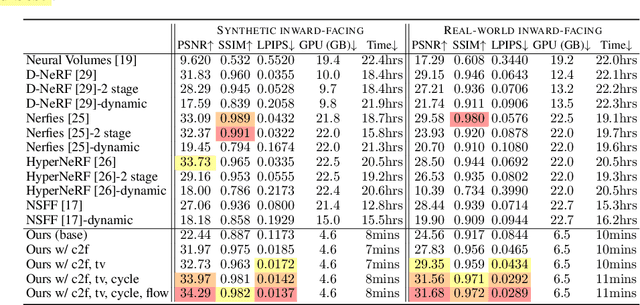

Modeling dynamic scenes is important for many applications such as virtual reality and telepresence. Despite achieving unprecedented fidelity for novel view synthesis in dynamic scenes, existing methods based on Neural Radiance Fields (NeRF) suffer from slow convergence (i.e., model training time measured in days). In this paper, we present DeVRF, a novel representation to accelerate learning dynamic radiance fields. The core of DeVRF is to model both the 3D canonical space and 4D deformation field of a dynamic, non-rigid scene with explicit and discrete voxel-based representations. However, it is quite challenging to train such a representation which has a large number of model parameters, often resulting in overfitting issues. To overcome this challenge, we devise a novel static-to-dynamic learning paradigm together with a new data capture setup that is convenient to deploy in practice. This paradigm unlocks efficient learning of deformable radiance fields via utilizing the 3D volumetric canonical space learnt from multi-view static images to ease the learning of 4D voxel deformation field with only few-view dynamic sequences. To further improve the efficiency of our DeVRF and its synthesized novel view's quality, we conduct thorough explorations and identify a set of strategies. We evaluate DeVRF on both synthetic and real-world dynamic scenes with different types of deformation. Experiments demonstrate that DeVRF achieves two orders of magnitude speedup (100x faster) with on-par high-fidelity results compared to the previous state-of-the-art approaches. The code and dataset will be released in https://github.com/showlab/DeVRF.
Masked Image Modeling with Denoising Contrast
May 19, 2022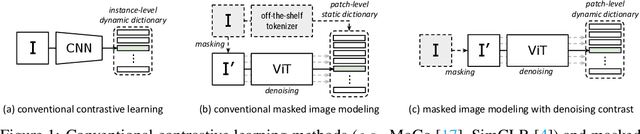
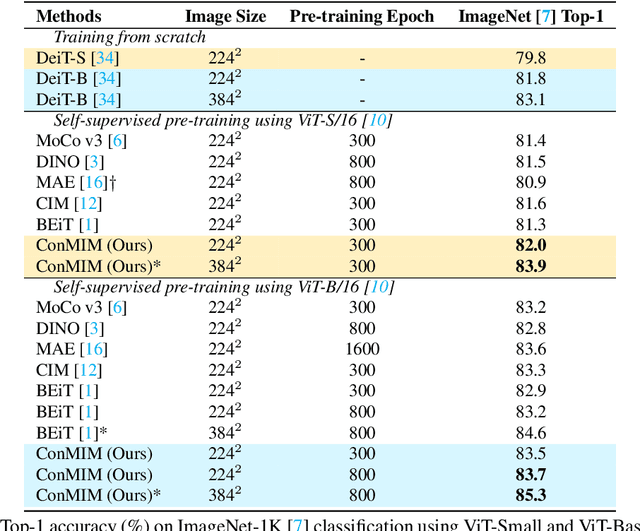
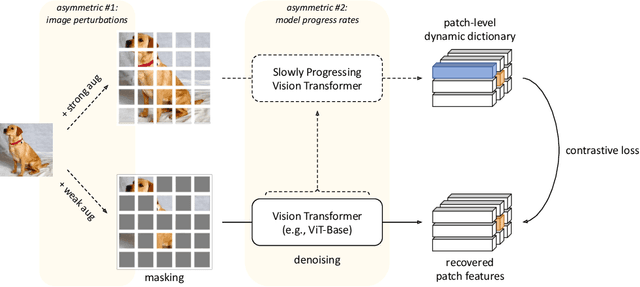

Since the development of self-supervised visual representation learning from contrastive learning to masked image modeling, there is no significant difference in essence, that is, how to design proper pretext tasks for vision dictionary look-up. Masked image modeling recently dominates this line of research with state-of-the-art performance on vision Transformers, where the core is to enhance the patch-level visual context capturing of the network via denoising auto-encoding mechanism. Rather than tailoring image tokenizers with extra training stages as in previous works, we unleash the great potential of contrastive learning on denoising auto-encoding and introduce a new pre-training method, ConMIM, to produce simple intra-image inter-patch contrastive constraints as the learning objectives for masked patch prediction. We further strengthen the denoising mechanism with asymmetric designs, including image perturbations and model progress rates, to improve the network pre-training. ConMIM-pretrained vision Transformers with various scales achieve promising results on downstream image classification, semantic segmentation, object detection, and instance segmentation tasks.
MILES: Visual BERT Pre-training with Injected Language Semantics for Video-text Retrieval
Apr 26, 2022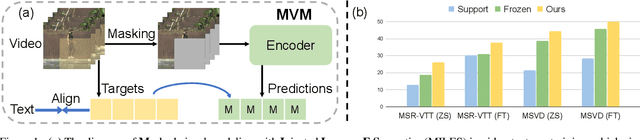
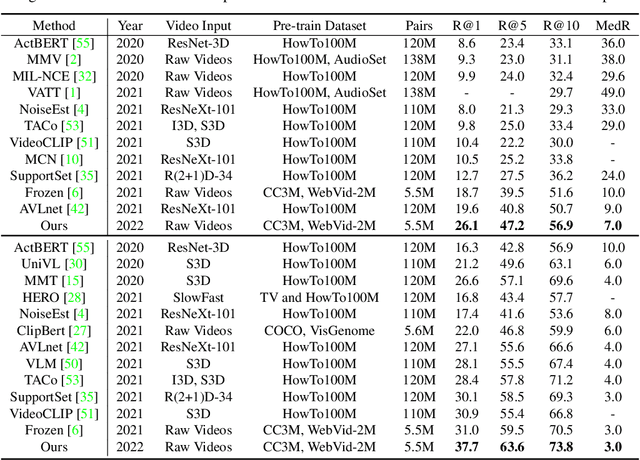
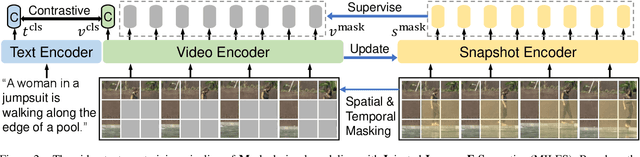
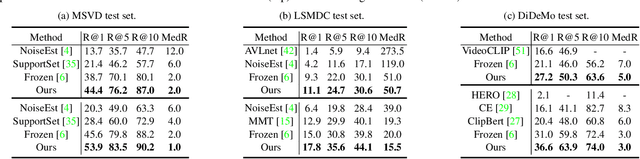
Dominant pre-training work for video-text retrieval mainly adopt the "dual-encoder" architectures to enable efficient retrieval, where two separate encoders are used to contrast global video and text representations, but ignore detailed local semantics. The recent success of image BERT pre-training with masked visual modeling that promotes the learning of local visual context, motivates a possible solution to address the above limitation. In this work, we for the first time investigate masked visual modeling in video-text pre-training with the "dual-encoder" architecture. We perform Masked visual modeling with Injected LanguagE Semantics (MILES) by employing an extra snapshot video encoder as an evolving "tokenizer" to produce reconstruction targets for masked video patch prediction. Given the corrupted video, the video encoder is trained to recover text-aligned features of the masked patches via reasoning with the visible regions along the spatial and temporal dimensions, which enhances the discriminativeness of local visual features and the fine-grained cross-modality alignment. Our method outperforms state-of-the-art methods for text-to-video retrieval on four datasets with both zero-shot and fine-tune evaluation protocols. Our approach also surpasses the baseline models significantly on zero-shot action recognition, which can be cast as video-to-text retrieval.
UMT: Unified Multi-modal Transformers for Joint Video Moment Retrieval and Highlight Detection
Mar 27, 2022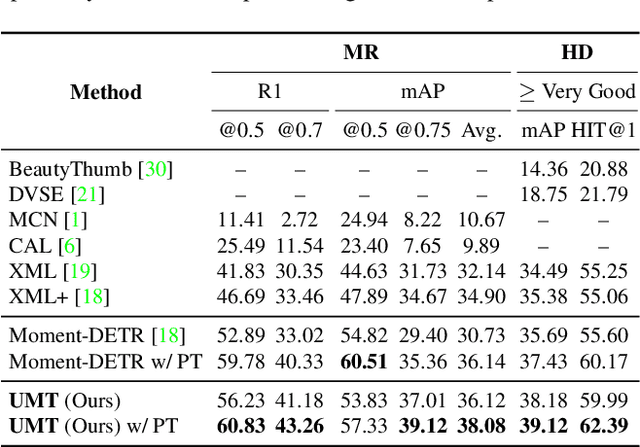
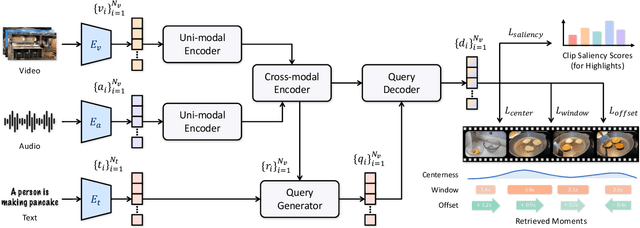
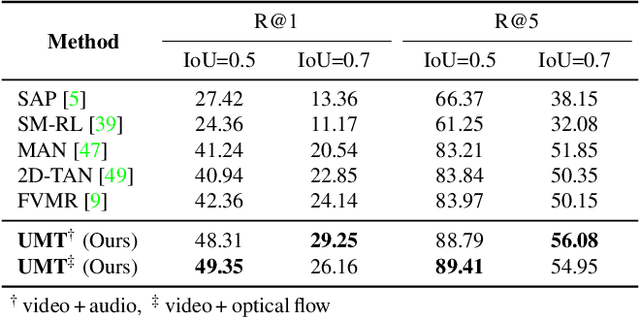
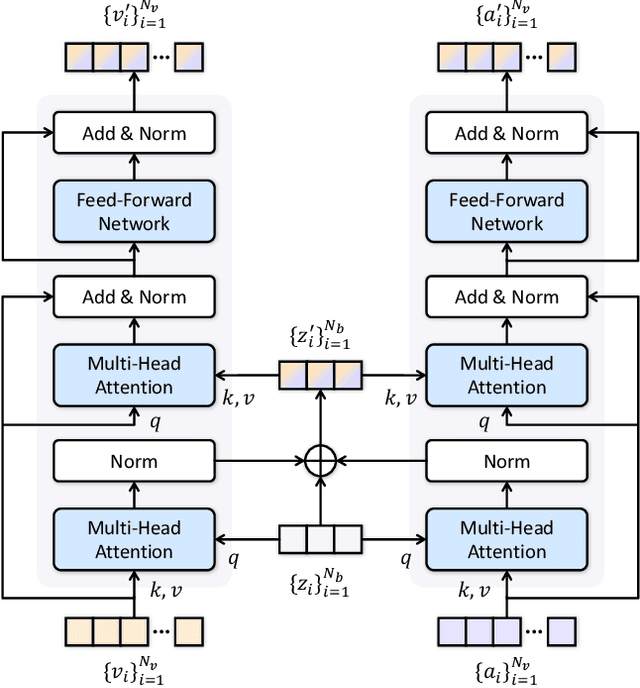
Finding relevant moments and highlights in videos according to natural language queries is a natural and highly valuable common need in the current video content explosion era. Nevertheless, jointly conducting moment retrieval and highlight detection is an emerging research topic, even though its component problems and some related tasks have already been studied for a while. In this paper, we present the first unified framework, named Unified Multi-modal Transformers (UMT), capable of realizing such joint optimization while can also be easily degenerated for solving individual problems. As far as we are aware, this is the first scheme to integrate multi-modal (visual-audio) learning for either joint optimization or the individual moment retrieval task, and tackles moment retrieval as a keypoint detection problem using a novel query generator and query decoder. Extensive comparisons with existing methods and ablation studies on QVHighlights, Charades-STA, YouTube Highlights, and TVSum datasets demonstrate the effectiveness, superiority, and flexibility of the proposed method under various settings. Source code and pre-trained models are available at https://github.com/TencentARC/UMT.
Revitalize Region Feature for Democratizing Video-Language Pre-training
Mar 19, 2022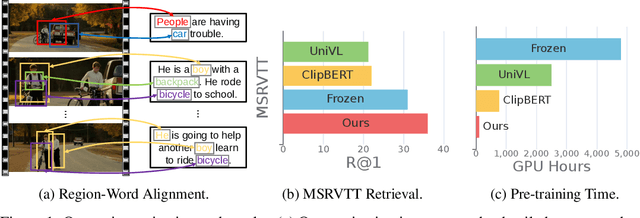
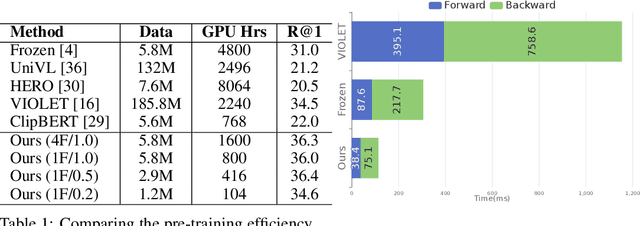
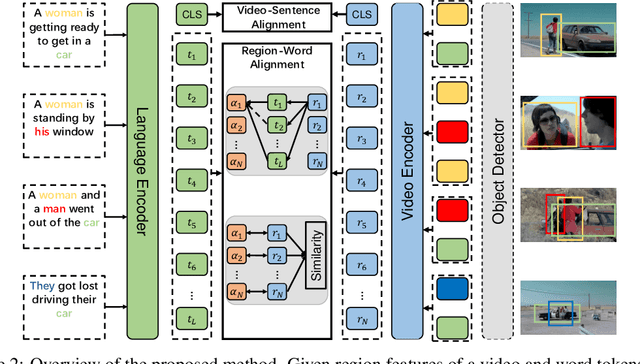

Recent dominant methods for video-language pre-training (VLP) learn transferable representations from the raw pixels in an end-to-end manner to achieve advanced performance on downstream video-language tasks. Despite the impressive results, VLP research becomes extremely expensive with the need for massive data and a long training time, preventing further explorations. In this work, we revitalize region features of sparsely sampled video clips to significantly reduce both spatial and temporal visual redundancy towards democratizing VLP research at the same time achieving state-of-the-art results. Specifically, to fully explore the potential of region features, we introduce a novel bidirectional region-word alignment regularization that properly optimizes the fine-grained relations between regions and certain words in sentences, eliminating the domain/modality disconnections between pre-extracted region features and text. Extensive results of downstream text-to-video retrieval and video question answering tasks on seven datasets demonstrate the superiority of our method on both effectiveness and efficiency, e.g., our method achieves competing results with 80\% fewer data and 85\% less pre-training time compared to the most efficient VLP method so far. The code will be available at \url{https://github.com/showlab/DemoVLP}.
All in One: Exploring Unified Video-Language Pre-training
Mar 14, 2022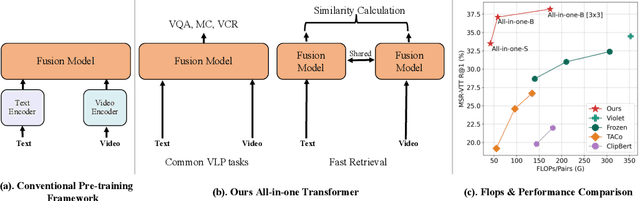
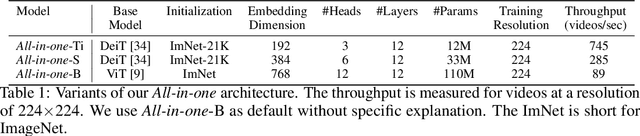
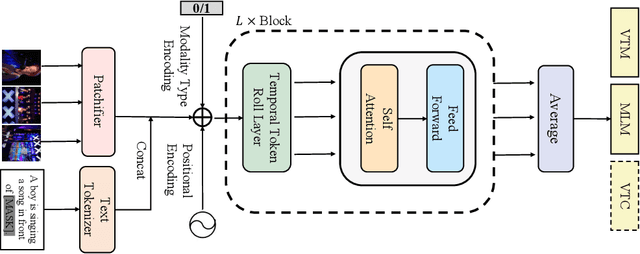
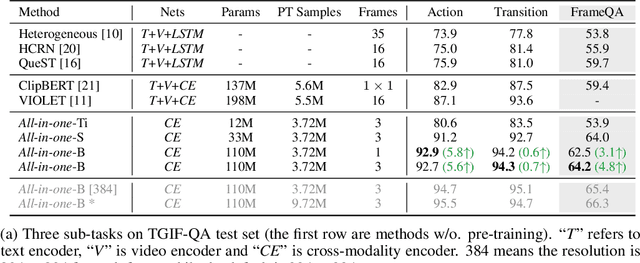
Mainstream Video-Language Pre-training models \cite{actbert,clipbert,violet} consist of three parts, a video encoder, a text encoder, and a video-text fusion Transformer. They pursue better performance via utilizing heavier unimodal encoders or multimodal fusion Transformers, resulting in increased parameters with lower efficiency in downstream tasks. In this work, we for the first time introduce an end-to-end video-language model, namely \textit{all-in-one Transformer}, that embeds raw video and textual signals into joint representations using a unified backbone architecture. We argue that the unique temporal information of video data turns out to be a key barrier hindering the design of a modality-agnostic Transformer. To overcome the challenge, we introduce a novel and effective token rolling operation to encode temporal representations from video clips in a non-parametric manner. The careful design enables the representation learning of both video-text multimodal inputs and unimodal inputs using a unified backbone model. Our pre-trained all-in-one Transformer is transferred to various downstream video-text tasks after fine-tuning, including text-video retrieval, video-question answering, multiple choice and visual commonsense reasoning. State-of-the-art performances with the minimal model FLOPs on nine datasets demonstrate the superiority of our method compared to the competitive counterparts. The code and pretrained model have been released in https://github.com/showlab/all-in-one.
BridgeFormer: Bridging Video-text Retrieval with Multiple Choice Questions
Jan 13, 2022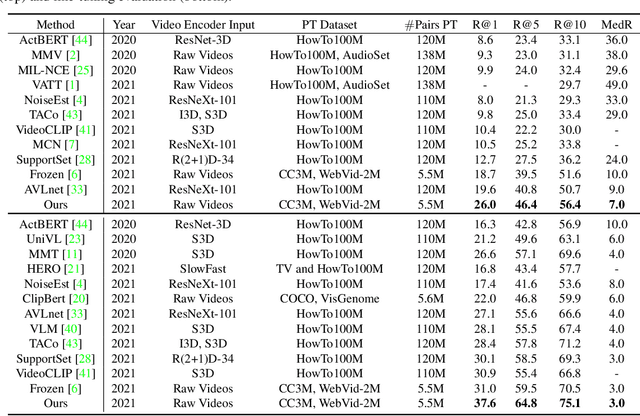
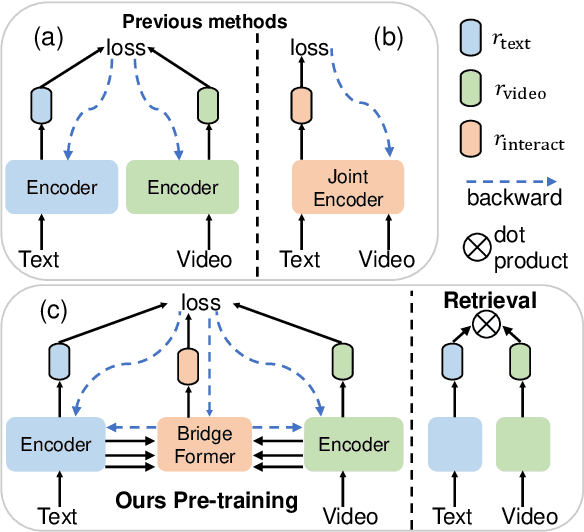
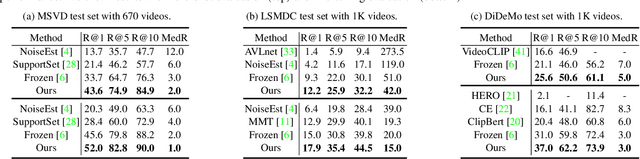
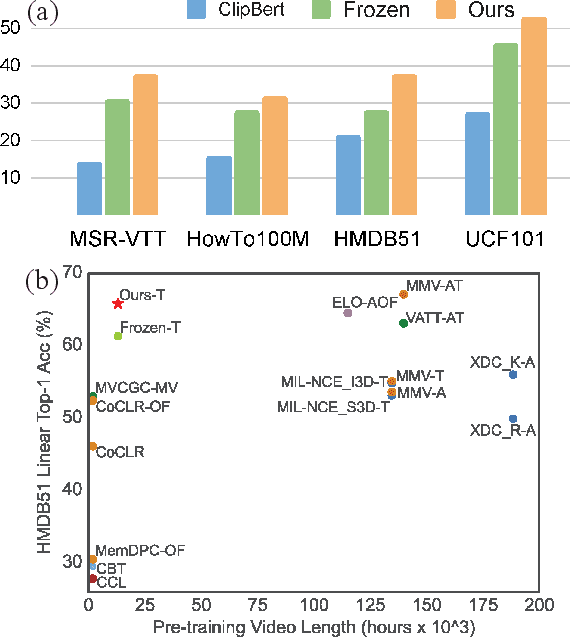
Pre-training a model to learn transferable video-text representation for retrieval has attracted a lot of attention in recent years. Previous dominant works mainly adopt two separate encoders for efficient retrieval, but ignore local associations between videos and texts. Another line of research uses a joint encoder to interact video with texts, but results in low efficiency since each text-video pair needs to be fed into the model. In this work, we enable fine-grained video-text interactions while maintaining high efficiency for retrieval via a novel pretext task, dubbed as Multiple Choice Questions (MCQ), where a parametric module BridgeFormer is trained to answer the "questions" constructed by the text features via resorting to the video features. Specifically, we exploit the rich semantics of text (i.e., nouns and verbs) to build questions, with which the video encoder can be trained to capture more regional content and temporal dynamics. In the form of questions and answers, the semantic associations between local video-text features can be properly established. BridgeFormer is able to be removed for downstream retrieval, rendering an efficient and flexible model with only two encoders. Our method outperforms state-of-the-art methods on the popular text-to-video retrieval task in five datasets with different experimental setups (i.e., zero-shot and fine-tune), including HowTo100M (one million videos). We further conduct zero-shot action recognition, which can be cast as video-to-text retrieval, and our approach also significantly surpasses its counterparts. As an additional benefit, our method achieves competitive results with much shorter pre-training videos on single-modality downstream tasks, e.g., action recognition with linear evaluation.