 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePSM-SQL: Progressive Schema Learning with Multi-granularity Semantics for Text-to-SQL
Feb 07, 2025



It is challenging to convert natural language (NL) questions into executable structured query language (SQL) queries for text-to-SQL tasks due to the vast number of database schemas with redundancy, which interferes with semantic learning, and the domain shift between NL and SQL. Existing works for schema linking focus on the table level and perform it once, ignoring the multi-granularity semantics and chainable cyclicity of schemas. In this paper, we propose a progressive schema linking with multi-granularity semantics (PSM-SQL) framework to reduce the redundant database schemas for text-to-SQL. Using the multi-granularity schema linking (MSL) module, PSM-SQL learns the schema semantics at the column, table, and database levels. More specifically, a triplet loss is used at the column level to learn embeddings, while fine-tuning LLMs is employed at the database level for schema reasoning. MSL employs classifier and similarity scores to model schema interactions for schema linking at the table level. In particular, PSM-SQL adopts a chain loop strategy to reduce the task difficulty of schema linking by continuously reducing the number of redundant schemas. Experiments conducted on text-to-SQL datasets show that the proposed PSM-SQL is 1-3 percentage points higher than the existing methods.
Solid-SQL: Enhanced Schema-linking based In-context Learning for Robust Text-to-SQL
Dec 17, 2024

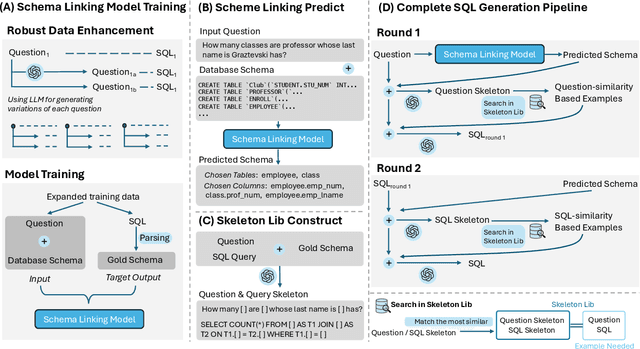

Recently, large language models (LLMs) have significantly improved the performance of text-to-SQL systems. Nevertheless, many state-of-the-art (SOTA) approaches have overlooked the critical aspect of system robustness. Our experiments reveal that while LLM-driven methods excel on standard datasets, their accuracy is notably compromised when faced with adversarial perturbations. To address this challenge, we propose a robust text-to-SQL solution, called Solid-SQL, designed to integrate with various LLMs. We focus on the pre-processing stage, training a robust schema-linking model enhanced by LLM-based data augmentation. Additionally, we design a two-round, structural similarity-based example retrieval strategy for in-context learning. Our method achieves SOTA SQL execution accuracy levels of 82.1% and 58.9% on the general Spider and Bird benchmarks, respectively. Furthermore, experimental results show that Solid-SQL delivers an average improvement of 11.6% compared to baselines on the perturbed Spider-Syn, Spider-Realistic, and Dr. Spider benchmarks.
L^2CL: Embarrassingly Simple Layer-to-Layer Contrastive Learning for Graph Collaborative Filtering
Jul 19, 2024



Graph neural networks (GNNs) have recently emerged as an effective approach to model neighborhood signals in collaborative filtering. Towards this research line, graph contrastive learning (GCL) demonstrates robust capabilities to address the supervision label shortage issue through generating massive self-supervised signals. Despite its effectiveness, GCL for recommendation suffers seriously from two main challenges: i) GCL relies on graph augmentation to generate semantically different views for contrasting, which could potentially disrupt key information and introduce unwanted noise; ii) current works for GCL primarily focus on contrasting representations using sophisticated networks architecture (usually deep) to capture high-order interactions, which leads to increased computational complexity and suboptimal training efficiency. To this end, we propose L2CL, a principled Layer-to-Layer Contrastive Learning framework that contrasts representations from different layers. By aligning the semantic similarities between different layers, L2CL enables the learning of complex structural relationships and gets rid of the noise perturbation in stochastic data augmentation. Surprisingly, we find that L2CL, using only one-hop contrastive learning paradigm, is able to capture intrinsic semantic structures and improve the quality of node representation, leading to a simple yet effective architecture. We also provide theoretical guarantees for L2CL in minimizing task-irrelevant information. Extensive experiments on five real-world datasets demonstrate the superiority of our model over various state-of-the-art collaborative filtering methods. Our code is available at https://github.com/downeykking/L2CL.
CTRL: Continuous-Time Representation Learning on Temporal Heterogeneous Information Network
May 11, 2024


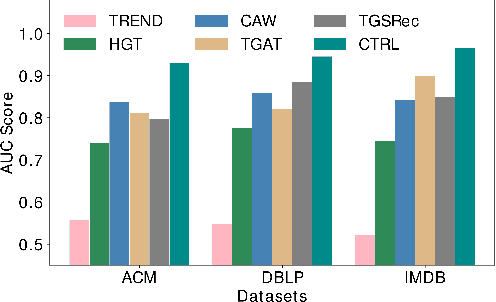
Inductive representation learning on temporal heterogeneous graphs is crucial for scalable deep learning on heterogeneous information networks (HINs) which are time-varying, such as citation networks. However, most existing approaches are not inductive and thus cannot handle new nodes or edges. Moreover, previous temporal graph embedding methods are often trained with the temporal link prediction task to simulate the link formation process of temporal graphs, while ignoring the evolution of high-order topological structures on temporal graphs. To fill these gaps, we propose a Continuous-Time Representation Learning (CTRL) model on temporal HINs. To preserve heterogeneous node features and temporal structures, CTRL integrates three parts in a single layer, they are 1) a \emph{heterogeneous attention} unit that measures the semantic correlation between nodes, 2) a \emph{edge-based Hawkes process} to capture temporal influence between heterogeneous nodes, and 3) \emph{dynamic centrality} that indicates the dynamic importance of a node. We train the CTRL model with a future event (a subgraph) prediction task to capture the evolution of the high-order network structure. Extensive experiments have been conducted on three benchmark datasets. The results demonstrate that our model significantly boosts performance and outperforms various state-of-the-art approaches. Ablation studies are conducted to demonstrate the effectiveness of the model design.
Decomposition for Enhancing Attention: Improving LLM-based Text-to-SQL through Workflow Paradigm
Feb 16, 2024



In-context learning of large-language models (LLMs) has achieved remarkable success in the field of natural language processing, while extensive case studies reveal that the single-step chain-of-thought prompting approach faces challenges such as attention diffusion and inadequate performance in complex tasks like text-to-SQL. To improve the contextual learning capabilities of LLMs in text-to-SQL, a workflow paradigm method is proposed, aiming to enhance the attention and problem-solving scope of LLMs through decomposition. Specifically, the information determination module for eliminating redundant information and the brand-new prompt structure based on problem classification greatly enhance the model's attention. Additionally, the inclusion of self-correcting and active learning modules greatly expands the problem-solving scope of LLMs, hence improving the upper limit of LLM-based approaches. Extensive experiments conducted on three datasets demonstrate that our approach outperforms other methods by a significant margin. About 2-3 percentage point improvements compared to the existing baseline on the Spider Dev and Spider-Realistic datasets and new SOTA results on the Spider Test dataset are achieved. Our code is available on GitHub: \url{https://github.com/FlyingFeather/DEA-SQL}.
OlaGPT: Empowering LLMs With Human-like Problem-Solving Abilities
May 23, 2023



In most current research, large language models (LLMs) are able to perform reasoning tasks by generating chains of thought through the guidance of specific prompts. However, there still exists a significant discrepancy between their capability in solving complex reasoning problems and that of humans. At present, most approaches focus on chains of thought (COT) and tool use, without considering the adoption and application of human cognitive frameworks. It is well-known that when confronting complex reasoning challenges, humans typically employ various cognitive abilities, and necessitate interaction with all aspects of tools, knowledge, and the external environment information to accomplish intricate tasks. This paper introduces a novel intelligent framework, referred to as OlaGPT. OlaGPT carefully studied a cognitive architecture framework, and propose to simulate certain aspects of human cognition. The framework involves approximating different cognitive modules, including attention, memory, reasoning, learning, and corresponding scheduling and decision-making mechanisms. Inspired by the active learning mechanism of human beings, it proposes a learning unit to record previous mistakes and expert opinions, and dynamically refer to them to strengthen their ability to solve similar problems. The paper also outlines common effective reasoning frameworks for human problem-solving and designs Chain-of-Thought (COT) templates accordingly. A comprehensive decision-making mechanism is also proposed to maximize model accuracy. The efficacy of OlaGPT has been stringently evaluated on multiple reasoning datasets, and the experimental outcomes reveal that OlaGPT surpasses state-of-the-art benchmarks, demonstrating its superior performance. Our implementation of OlaGPT is available on GitHub: \url{https://github.com/oladata-team/OlaGPT}.
One for All, All for One: Learning and Transferring User Embeddings for Cross-Domain Recommendation
Nov 22, 2022Cross-domain recommendation is an important method to improve recommender system performance, especially when observations in target domains are sparse. However, most existing techniques focus on single-target or dual-target cross-domain recommendation (CDR) and are hard to be generalized to CDR with multiple target domains. In addition, the negative transfer problem is prevalent in CDR, where the recommendation performance in a target domain may not always be enhanced by knowledge learned from a source domain, especially when the source domain has sparse data. In this study, we propose CAT-ART, a multi-target CDR method that learns to improve recommendations in all participating domains through representation learning and embedding transfer. Our method consists of two parts: a self-supervised Contrastive AuToencoder (CAT) framework to generate global user embeddings based on information from all participating domains, and an Attention-based Representation Transfer (ART) framework which transfers domain-specific user embeddings from other domains to assist with target domain recommendation. CAT-ART boosts the recommendation performance in any target domain through the combined use of the learned global user representation and knowledge transferred from other domains, in addition to the original user embedding in the target domain. We conducted extensive experiments on a collected real-world CDR dataset spanning 5 domains and involving a million users. Experimental results demonstrate the superiority of the proposed method over a range of prior arts. We further conducted ablation studies to verify the effectiveness of the proposed components. Our collected dataset will be open-sourced to facilitate future research in the field of multi-domain recommender systems and user modeling.