 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Generation from Single Semantic Label Map
Mar 11, 2019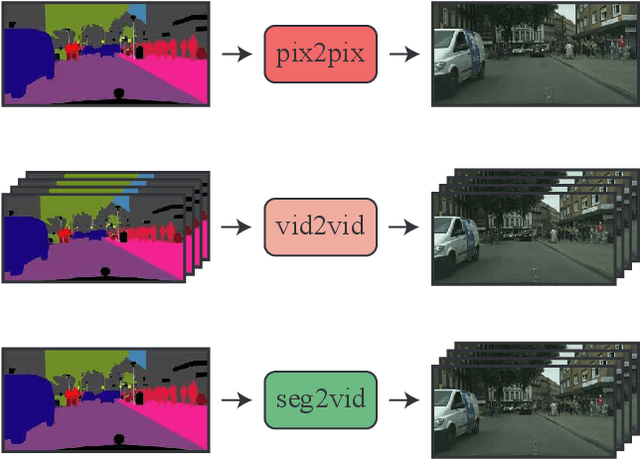

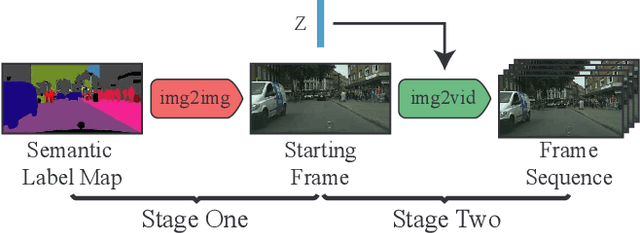

This paper proposes the novel task of video generation conditioned on a SINGLE semantic label map, which provides a good balance between flexibility and quality in the generation process. Different from typical end-to-end approaches, which model both scene content and dynamics in a single step, we propose to decompose this difficult task into two sub-problems. As current image generation methods do better than video generation in terms of detail, we synthesize high quality content by only generating the first frame. Then we animate the scene based on its semantic meaning to obtain the temporally coherent video, giving us excellent results overall. We employ a cVAE for predicting optical flow as a beneficial intermediate step to generate a video sequence conditioned on the initial single frame. A semantic label map is integrated into the flow prediction module to achieve major improvements in the image-to-video generation process. Extensive experiments on the Cityscapes dataset show that our method outperforms all competing methods.
Group-wise Correlation Stereo Network
Mar 10, 2019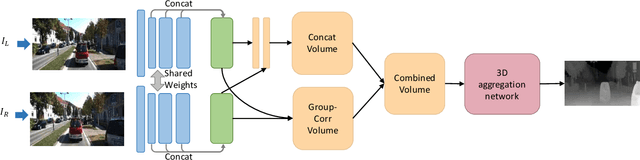
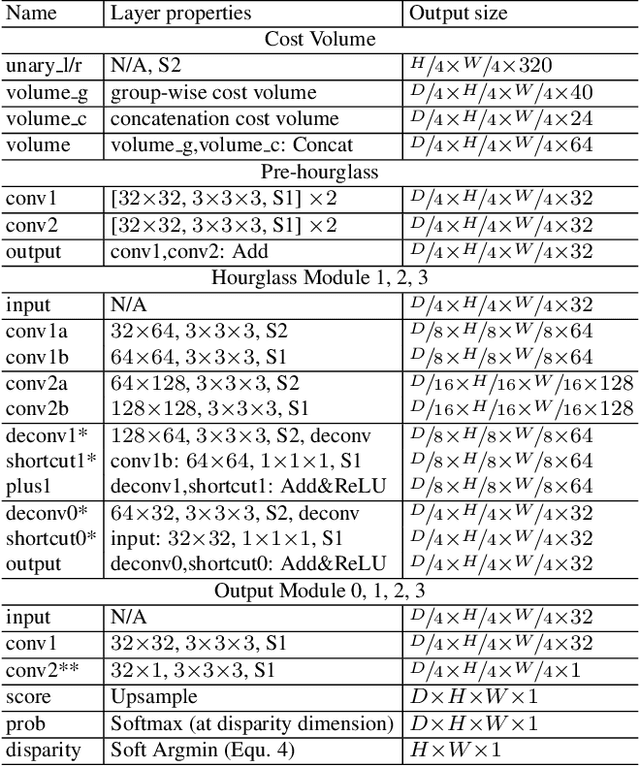

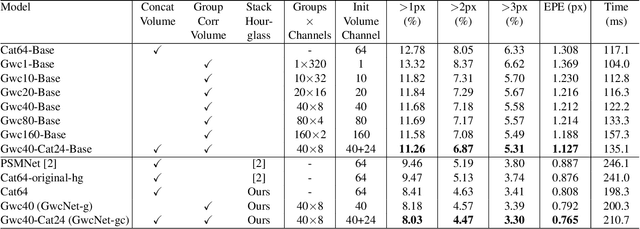
Stereo matching estimates the disparity between a rectified image pair, which is of great importance to depth sensing, autonomous driving, and other related tasks. Previous works built cost volumes with cross-correlation or concatenation of left and right features across all disparity levels, and then a 2D or 3D convolutional neural network is utilized to regress the disparity maps. In this paper, we propose to construct the cost volume by group-wise correlation. The left features and the right features are divided into groups along the channel dimension, and correlation maps are computed among each group to obtain multiple matching cost proposals, which are then packed into a cost volume. Group-wise correlation provides efficient representations for measuring feature similarities and will not lose too much information like full correlation. It also preserves better performance when reducing parameters compared with previous methods. The 3D stacked hourglass network proposed in previous works is improved to boost the performance and decrease the inference computational cost. Experiment results show that our method outperforms previous methods on Scene Flow, KITTI 2012, and KITTI 2015 datasets. The code is available at https://github.com/xy-guo/GwcNet
SSN: Learning Sparse Switchable Normalization via SparsestMax
Mar 09, 2019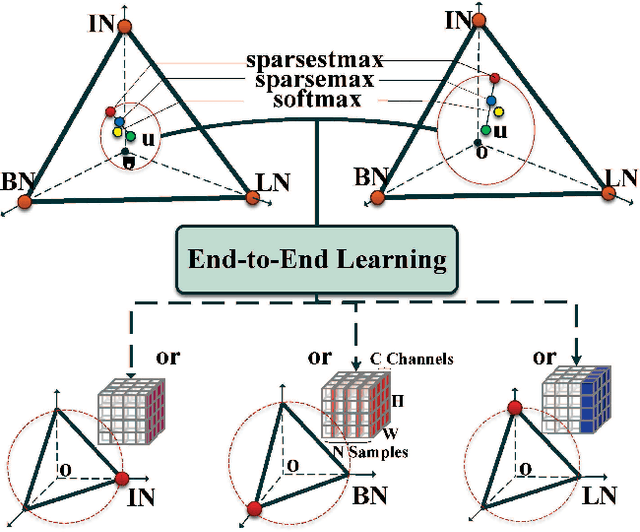
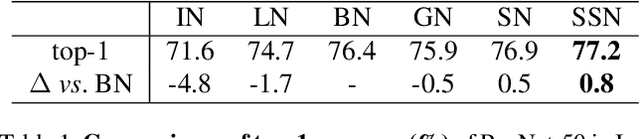
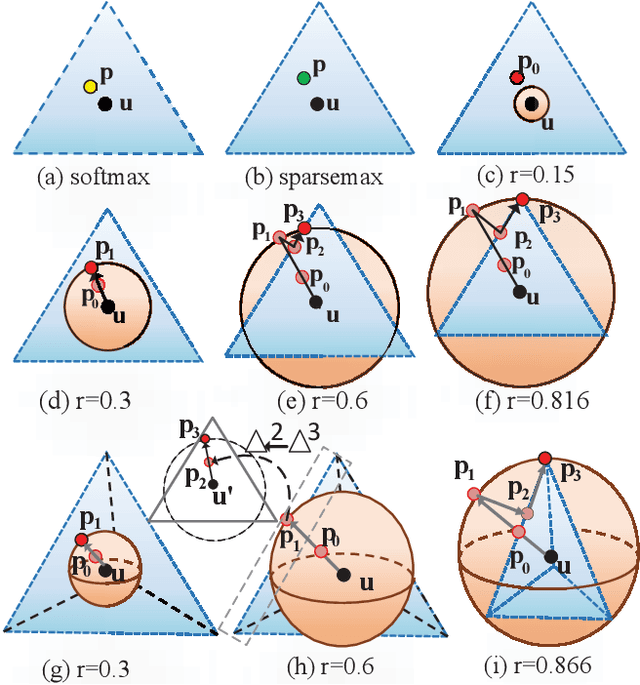
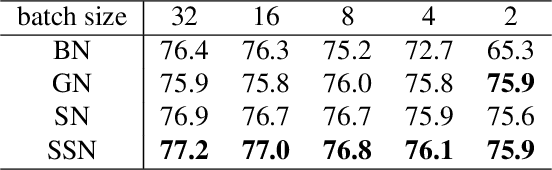
Normalization methods improve both optimization and generalization of ConvNets. To further boost performance, the recently-proposed switchable normalization (SN) provides a new perspective for deep learning: it learns to select different normalizers for different convolution layers of a ConvNet. However, SN uses softmax function to learn importance ratios to combine normalizers, leading to redundant computations compared to a single normalizer. This work addresses this issue by presenting Sparse Switchable Normalization (SSN) where the importance ratios are constrained to be sparse. Unlike $\ell_1$ and $\ell_0$ constraints that impose difficulties in optimization, we turn this constrained optimization problem into feed-forward computation by proposing SparsestMax, which is a sparse version of softmax. SSN has several appealing properties. (1) It inherits all benefits from SN such as applicability in various tasks and robustness to a wide range of batch sizes. (2) It is guaranteed to select only one normalizer for each normalization layer, avoiding redundant computations. (3) SSN can be transferred to various tasks in an end-to-end manner. Extensive experiments show that SSN outperforms its counterparts on various challenging benchmarks such as ImageNet, Cityscapes, ADE20K, and Kinetics.
Unsupervised Cross-spectral Stereo Matching by Learning to Synthesize
Mar 04, 2019



Unsupervised cross-spectral stereo matching aims at recovering disparity given cross-spectral image pairs without any supervision in the form of ground truth disparity or depth. The estimated depth provides additional information complementary to individual semantic features, which can be helpful for other vision tasks such as tracking, recognition and detection. However, there are large appearance variations between images from different spectral bands, which is a challenge for cross-spectral stereo matching. Existing deep unsupervised stereo matching methods are sensitive to the appearance variations and do not perform well on cross-spectral data. We propose a novel unsupervised cross-spectral stereo matching framework based on image-to-image translation. First, a style adaptation network transforms images across different spectral bands by cycle consistency and adversarial learning, during which appearance variations are minimized. Then, a stereo matching network is trained with image pairs from the same spectra using view reconstruction loss. At last, the estimated disparity is utilized to supervise the spectral-translation network in an end-to-end way. Moreover, a novel style adaptation network F-cycleGAN is proposed to improve the robustness of spectral translation. Our method can tackle appearance variations and enhance the robustness of unsupervised cross-spectral stereo matching. Experimental results show that our method achieves good performance without using depth supervision or explicit semantic information.
Unsupervised Bi-directional Flow-based Video Generation from one Snapshot
Mar 03, 2019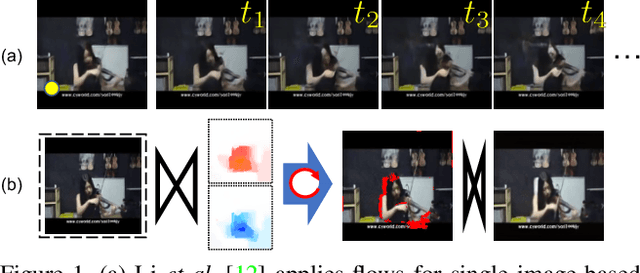
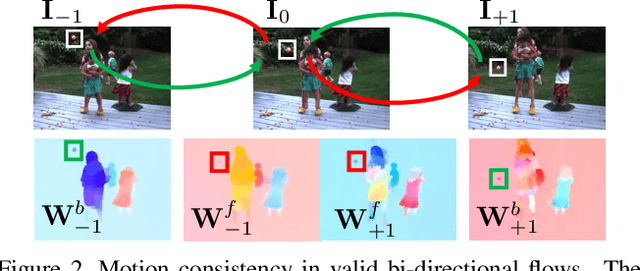
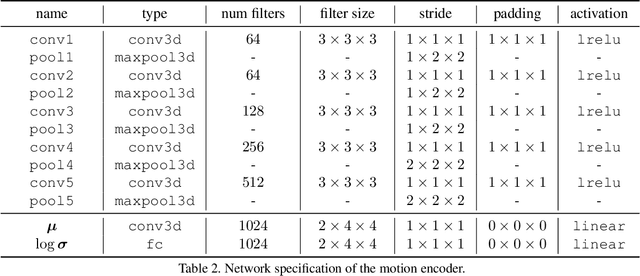
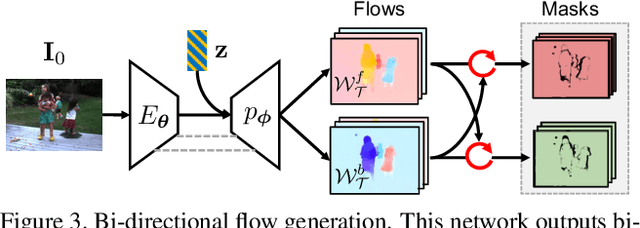
Imagining multiple consecutive frames given one single snapshot is challenging, since it is difficult to simultaneously predict diverse motions from a single image and faithfully generate novel frames without visual distortions. In this work, we leverage an unsupervised variational model to learn rich motion patterns in the form of long-term bi-directional flow fields, and apply the predicted flows to generate high-quality video sequences. In contrast to the state-of-the-art approach, our method does not require external flow supervisions for learning. This is achieved through a novel module that performs bi-directional flows prediction from a single image. In addition, with the bi-directional flow consistency check, our method can handle occlusion and warping artifacts in a principled manner. Our method can be trained end-to-end based on arbitrarily sampled natural video clips, and it is able to capture multi-modal motion uncertainty and synthesizes photo-realistic novel sequences. Quantitative and qualitative evaluations over synthetic and real-world datasets demonstrate the effectiveness of the proposed approach over the state-of-the-art methods.
DeepFashion2: A Versatile Benchmark for Detection, Pose Estimation, Segmentation and Re-Identification of Clothing Images
Jan 23, 2019
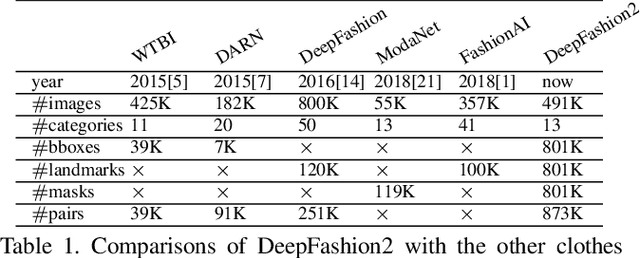


Understanding fashion images has been advanced by benchmarks with rich annotations such as DeepFashion, whose labels include clothing categories, landmarks, and consumer-commercial image pairs. However, DeepFashion has nonnegligible issues such as single clothing-item per image, sparse landmarks (4~8 only), and no per-pixel masks, making it had significant gap from real-world scenarios. We fill in the gap by presenting DeepFashion2 to address these issues. It is a versatile benchmark of four tasks including clothes detection, pose estimation, segmentation, and retrieval. It has 801K clothing items where each item has rich annotations such as style, scale, viewpoint, occlusion, bounding box, dense landmarks and masks. There are also 873K Commercial-Consumer clothes pairs. A strong baseline is proposed, called Match R-CNN, which builds upon Mask R-CNN to solve the above four tasks in an end-to-end manner. Extensive evaluations are conducted with different criterions in DeepFashion2.
Dynamic Fusion with Intra- and Inter- Modality Attention Flow for Visual Question Answering
Dec 13, 2018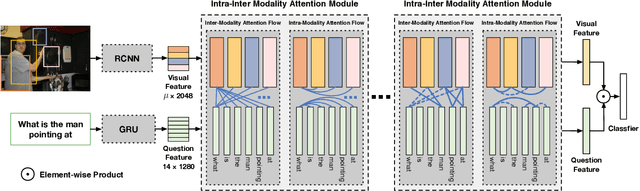

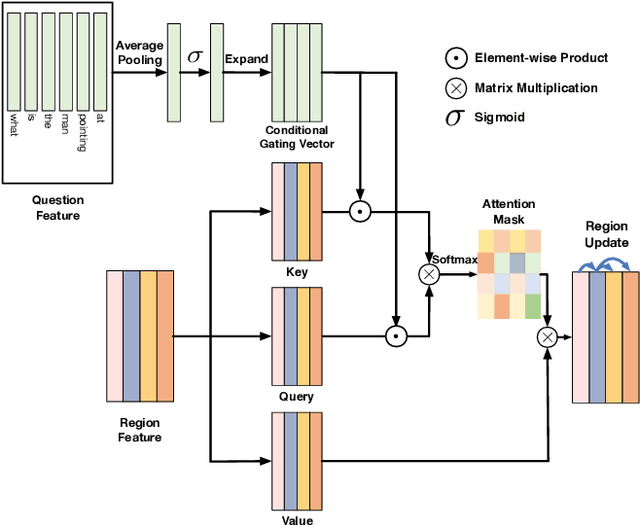
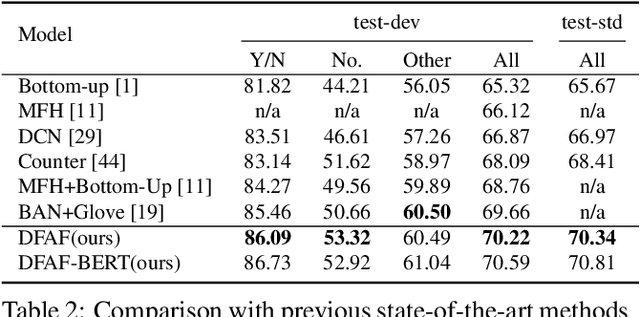
Learning effective fusion of multi-modality features is at the heart of visual question answering. We propose a novel method of dynamically fusing multi-modal features with intra- and inter-modality information flow, which alternatively pass dynamic information between and across the visual and language modalities. It can robustly capture the high-level interactions between language and vision domains, thus significantly improves the performance of visual question answering. We also show that the proposed dynamic intra-modality attention flow conditioned on the other modality can dynamically modulate the intra-modality attention of the target modality, which is vital for multimodality feature fusion. Experimental evaluations on the VQA 2.0 dataset show that the proposed method achieves state-of-the-art VQA performance. Extensive ablation studies are carried out for the comprehensive analysis of the proposed method.
PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud
Dec 11, 2018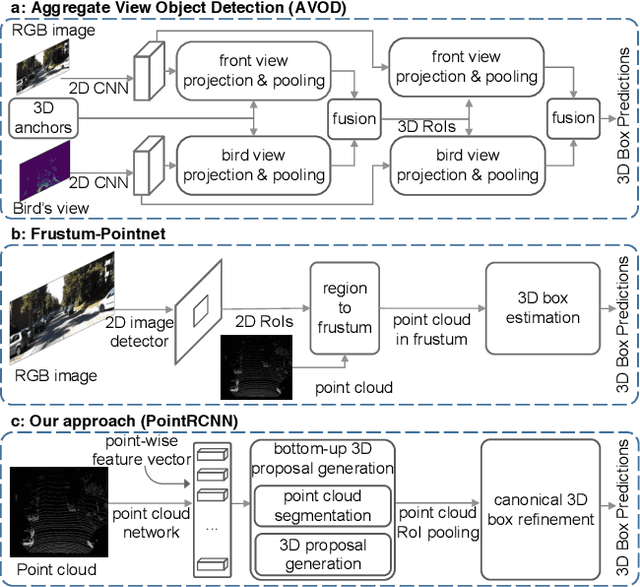
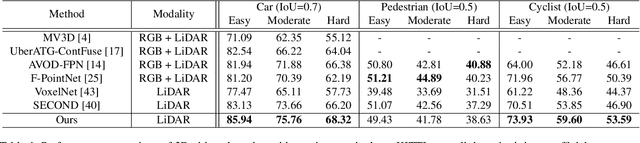
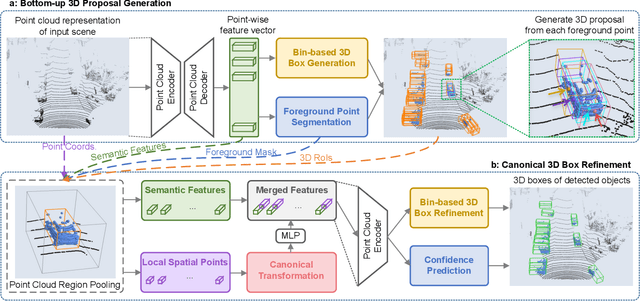
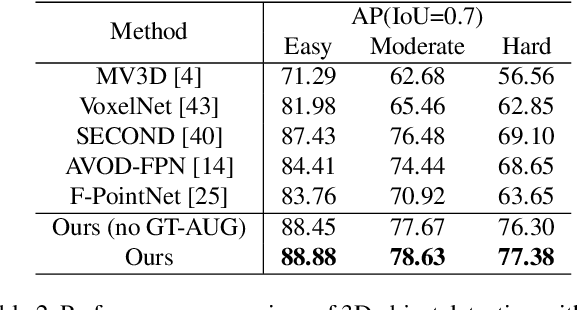
In this paper, we propose PointRCNN for 3D object detection from raw point cloud. The whole framework is composed of two stages: stage-1 for the bottom-up 3D proposal generation and stage-2 for refining proposals in the canonical coordinates to obtain the final detection results. Instead of generating proposals from RGB image or projecting point cloud to bird's view or voxels as previous methods do, our stage-1 sub-network directly generates a small number of high-quality 3D proposals from point cloud in a bottom-up manner via segmenting the point cloud of whole scene into foreground points and background. The stage-2 sub-network transforms the pooled points of each proposal to canonical coordinates to learn better local spatial features, which is combined with global semantic features of each point learned in stage-1 for accurate box refinement and confidence prediction. Extensive experiments on the 3D detection benchmark of KITTI dataset show that our proposed architecture outperforms state-of-the-art methods with remarkable margins by using only point cloud as input.
Gradient Harmonized Single-stage Detector
Nov 13, 2018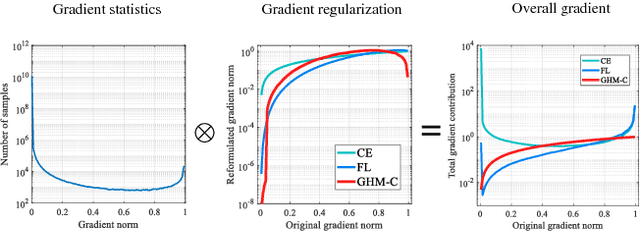
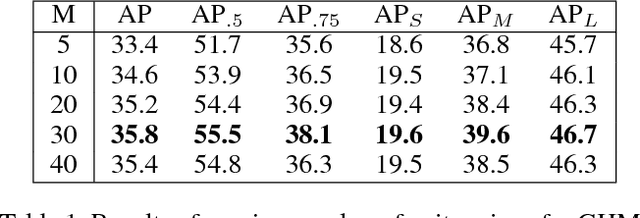
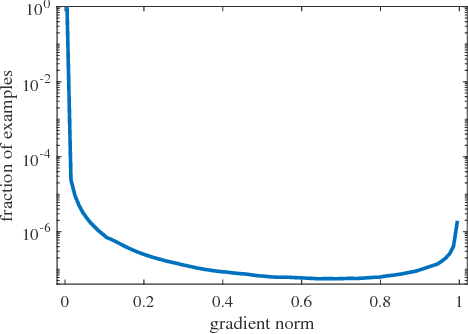
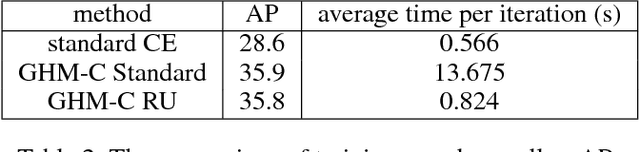
Despite the great success of two-stage detectors, single-stage detector is still a more elegant and efficient way, yet suffers from the two well-known disharmonies during training, i.e. the huge difference in quantity between positive and negative examples as well as between easy and hard examples. In this work, we first point out that the essential effect of the two disharmonies can be summarized in term of the gradient. Further, we propose a novel gradient harmonizing mechanism (GHM) to be a hedging for the disharmonies. The philosophy behind GHM can be easily embedded into both classification loss function like cross-entropy (CE) and regression loss function like smooth-$L_1$ ($SL_1$) loss. To this end, two novel loss functions called GHM-C and GHM-R are designed to balancing the gradient flow for anchor classification and bounding box refinement, respectively. Ablation study on MS COCO demonstrates that without laborious hyper-parameter tuning, both GHM-C and GHM-R can bring substantial improvement for single-stage detector. Without any whistles and bells, our model achieves 41.6 mAP on COCO test-dev set which surpasses the state-of-the-art method, Focal Loss (FL) + $SL_1$, by 0.8.
Learnable Histogram: Statistical Context Features for Deep Neural Networks
Oct 15, 2018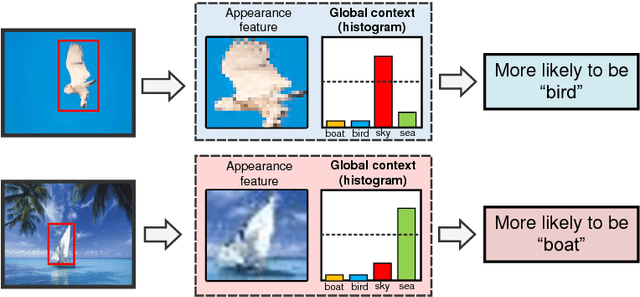
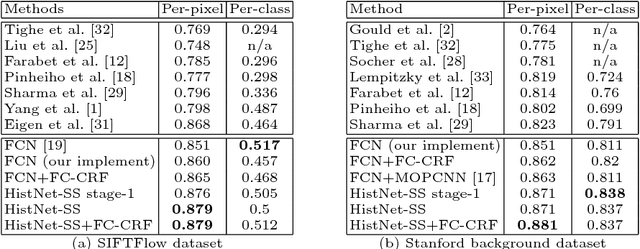
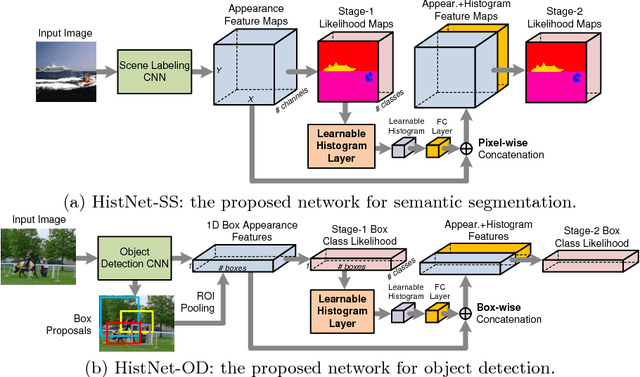
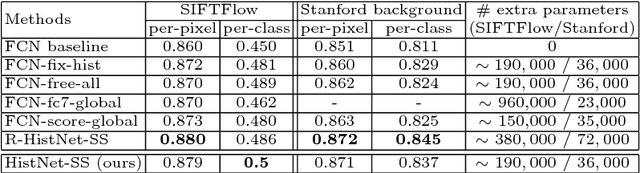
Statistical features, such as histogram, Bag-of-Words (BoW) and Fisher Vector, were commonly used with hand-crafted features in conventional classification methods, but attract less attention since the popularity of deep learning methods. In this paper, we propose a learnable histogram layer, which learns histogram features within deep neural networks in end-to-end training. Such a layer is able to back-propagate (BP) errors, learn optimal bin centers and bin widths, and be jointly optimized with other layers in deep networks during training. Two vision problems, semantic segmentation and object detection, are explored by integrating the learnable histogram layer into deep networks, which show that the proposed layer could be well generalized to different applications. In-depth investigations are conducted to provide insights on the newly introduced layer.