 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Long Sequence Modeling via State Space Augmented Transformer
Dec 15, 2022



Transformer models have achieved superior performance in various natural language processing tasks. However, the quadratic computational cost of the attention mechanism limits its practicality for long sequences. There are existing attention variants that improve the computational efficiency, but they have limited ability to effectively compute global information. In parallel to Transformer models, state space models (SSMs) are tailored for long sequences, but they are not flexible enough to capture complicated local information. We propose SPADE, short for $\underline{\textbf{S}}$tate s$\underline{\textbf{P}}$ace $\underline{\textbf{A}}$ugmente$\underline{\textbf{D}}$ Transform$\underline{\textbf{E}}$r. Specifically, we augment a SSM into the bottom layer of SPADE, and we employ efficient local attention methods for the other layers. The SSM augments global information, which complements the lack of long-range dependency issue in local attention methods. Experimental results on the Long Range Arena benchmark and language modeling tasks demonstrate the effectiveness of the proposed method. To further demonstrate the scalability of SPADE, we pre-train large encoder-decoder models and present fine-tuning results on natural language understanding and natural language generation tasks.
AdaMix: Mixture-of-Adaptations for Parameter-efficient Model Tuning
Nov 02, 2022



Standard fine-tuning of large pre-trained language models (PLMs) for downstream tasks requires updating hundreds of millions to billions of parameters, and storing a large copy of the PLM weights for every task resulting in increased cost for storing, sharing and serving the models. To address this, parameter-efficient fine-tuning (PEFT) techniques were introduced where small trainable components are injected in the PLM and updated during fine-tuning. We propose AdaMix as a general PEFT method that tunes a mixture of adaptation modules -- given the underlying PEFT method of choice -- introduced in each Transformer layer while keeping most of the PLM weights frozen. For instance, AdaMix can leverage a mixture of adapters like Houlsby or a mixture of low rank decomposition matrices like LoRA to improve downstream task performance over the corresponding PEFT methods for fully supervised and few-shot NLU and NLG tasks. Further, we design AdaMix such that it matches the same computational cost and the number of tunable parameters as the underlying PEFT method. By only tuning 0.1-0.2% of PLM parameters, we show that AdaMix outperforms SOTA parameter-efficient fine-tuning and full model fine-tuning for both NLU and NLG tasks.
AutoMoE: Neural Architecture Search for Efficient Sparsely Activated Transformers
Oct 14, 2022
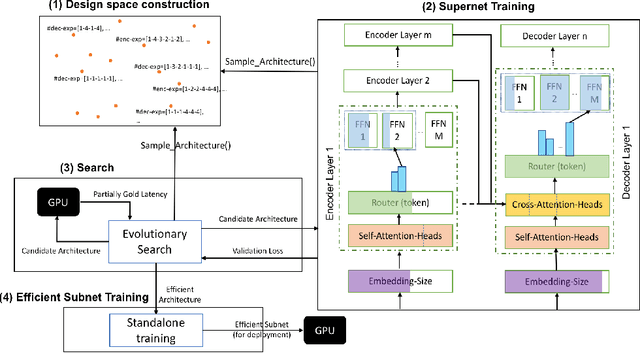


Neural architecture search (NAS) has demonstrated promising results on identifying efficient Transformer architectures which outperform manually designed ones for natural language tasks like neural machine translation (NMT). Existing NAS methods operate on a space of dense architectures, where all of the sub-architecture weights are activated for every input. Motivated by the recent advances in sparsely activated models like the Mixture-of-Experts (MoE) model, we introduce sparse architectures with conditional computation into the NAS search space. Given this expressive search space which subsumes prior densely activated architectures, we develop a new framework AutoMoE to search for efficient sparsely activated sub-Transformers. AutoMoE-generated sparse models obtain (i) 3x FLOPs reduction over manually designed dense Transformers and (ii) 23% FLOPs reduction over state-of-the-art NAS-generated dense sub-Transformers with parity in BLEU score on benchmark datasets for NMT. AutoMoE consists of three training phases: (a) Heterogeneous search space design with dense and sparsely activated Transformer modules (e.g., how many experts? where to place them? what should be their sizes?); (b) SuperNet training that jointly trains several subnetworks sampled from the large search space by weight-sharing; (c) Evolutionary search for the architecture with the optimal trade-off between task performance and computational constraint like FLOPs and latency. AutoMoE code, data and trained models are available at https://github.com/microsoft/AutoMoE.
Task-Aware Specialization for Efficient and Robust Dense Retrieval for Open-Domain Question Answering
Oct 11, 2022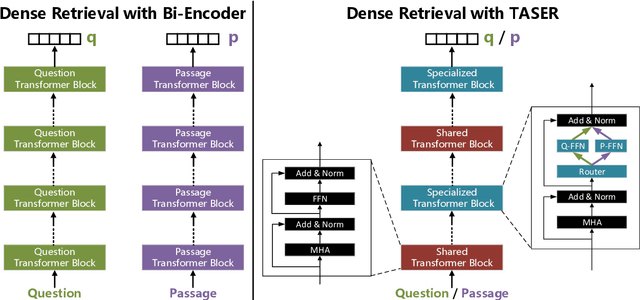
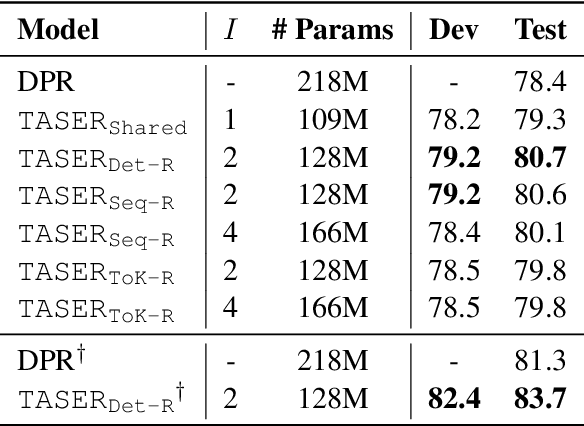
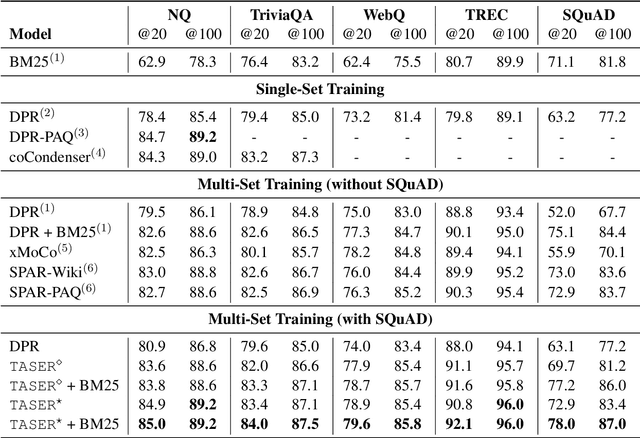
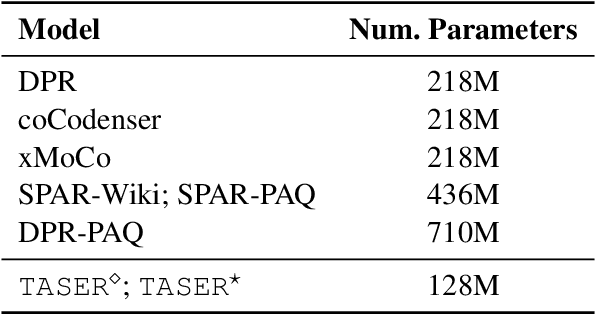
Given its effectiveness on knowledge-intensive natural language processing tasks, dense retrieval models have become increasingly popular. Specifically, the de-facto architecture for open-domain question answering uses two isomorphic encoders that are initialized from the same pretrained model but separately parameterized for questions and passages. This bi-encoder architecture is parameter-inefficient in that there is no parameter sharing between encoders. Further, recent studies show that such dense retrievers underperform BM25 in various settings. We thus propose a new architecture, Task-aware Specialization for dense Retrieval (TASER), which enables parameter sharing by interleaving shared and specialized blocks in a single encoder. Our experiments on five question answering datasets show that \ourmodel\ can achieve superior accuracy, surpassing BM25, while using about 60% of the parameters as bi-encoder dense retrievers. In out-of-domain evaluations, TASER is also empirically more robust than bi-encoder dense retrievers.
PTSEFormer: Progressive Temporal-Spatial Enhanced TransFormer Towards Video Object Detection
Sep 06, 2022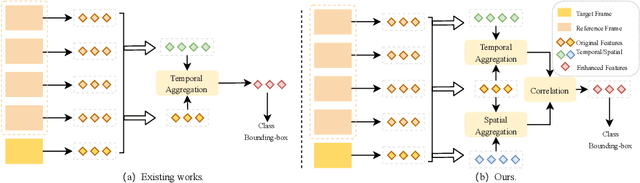
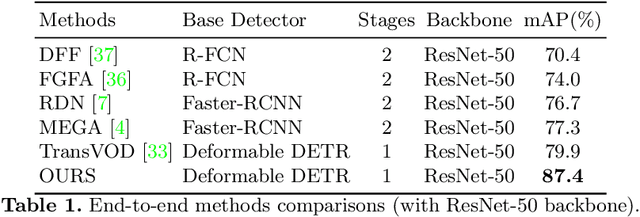
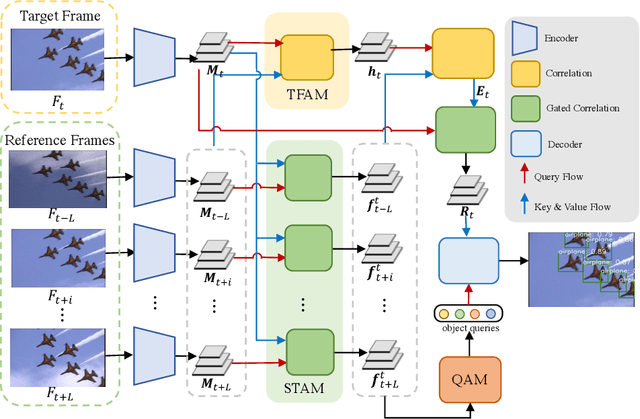
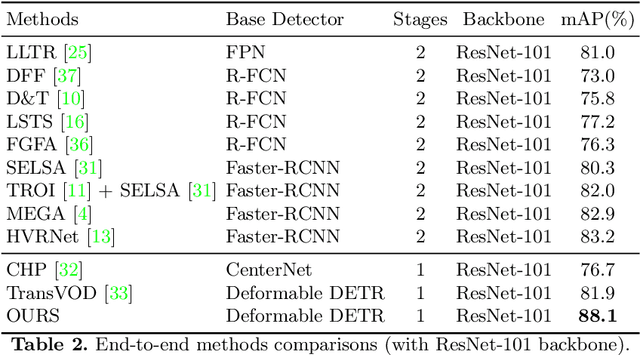
Recent years have witnessed a trend of applying context frames to boost the performance of object detection as video object detection. Existing methods usually aggregate features at one stroke to enhance the feature. These methods, however, usually lack spatial information from neighboring frames and suffer from insufficient feature aggregation. To address the issues, we perform a progressive way to introduce both temporal information and spatial information for an integrated enhancement. The temporal information is introduced by the temporal feature aggregation model (TFAM), by conducting an attention mechanism between the context frames and the target frame (i.e., the frame to be detected). Meanwhile, we employ a Spatial Transition Awareness Model (STAM) to convey the location transition information between each context frame and target frame. Built upon a transformer-based detector DETR, our PTSEFormer also follows an end-to-end fashion to avoid heavy post-processing procedures while achieving 88.1% mAP on the ImageNet VID dataset. Codes are available at https://github.com/Hon-Wong/PTSEFormer.
Deep Generative Modeling on Limited Data with Regularization by Nontransferable Pre-trained Models
Aug 30, 2022
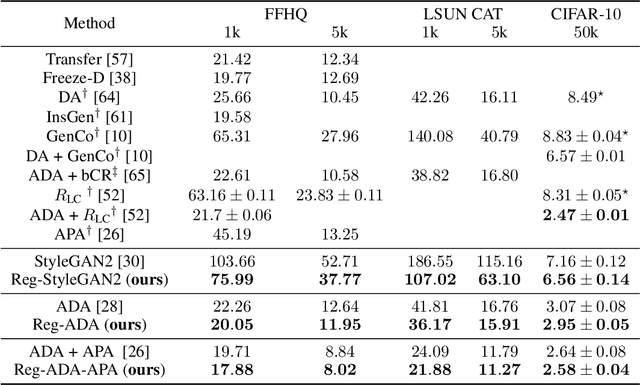
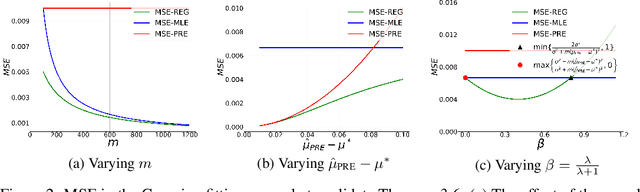

Deep generative models (DGMs) are data-eager. Essentially, it is because learning a complex model on limited data suffers from a large variance and easily overfits. Inspired by the \emph{bias-variance dilemma}, we propose \emph{regularized deep generative model} (Reg-DGM), which leverages a nontransferable pre-trained model to reduce the variance of generative modeling with limited data. Formally, Reg-DGM optimizes a weighted sum of a certain divergence between the data distribution and the DGM and the expectation of an energy function defined by the pre-trained model w.r.t. the DGM. Theoretically, we characterize the existence and uniqueness of the global minimum of Reg-DGM in the nonparametric setting and rigorously prove the statistical benefits of Reg-DGM w.r.t. the mean squared error and the expected risk in a simple yet representative Gaussian-fitting example. Empirically, it is quite flexible to specify the DGM and the pre-trained model in Reg-DGM. In particular, with a ResNet-18 classifier pre-trained on ImageNet and a data-dependent energy function, Reg-DGM consistently improves the generation performance of strong DGMs including StyleGAN2 and ADA on several benchmarks with limited data and achieves competitive results to the state-of-the-art methods.
AdaMix: Mixture-of-Adapter for Parameter-efficient Tuning of Large Language Models
May 24, 2022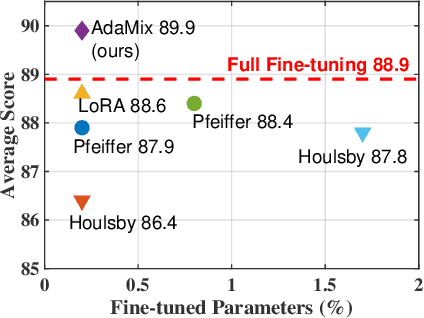
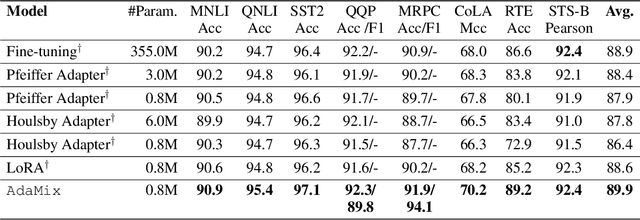
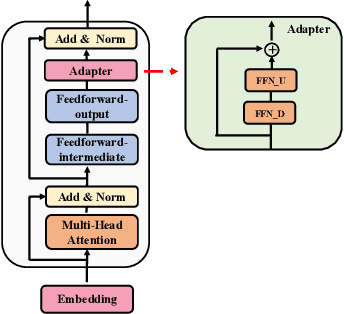
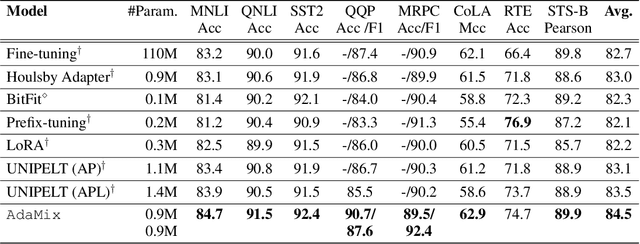
Fine-tuning large-scale pre-trained language models to downstream tasks require updating hundreds of millions of parameters. This not only increases the serving cost to store a large copy of the model weights for every task, but also exhibits instability during few-shot task adaptation. Parameter-efficient techniques have been developed that tune small trainable components (e.g., adapters) injected in the large model while keeping most of the model weights frozen. The prevalent mechanism to increase adapter capacity is to increase the bottleneck dimension which increases the adapter parameters. In this work, we introduce a new mechanism to improve adapter capacity without increasing parameters or computational cost by two key techniques. (i) We introduce multiple shared adapter components in each layer of the Transformer architecture. We leverage sparse learning via random routing to update the adapter parameters (encoder is kept frozen) resulting in the same amount of computational cost (FLOPs) as that of training a single adapter. (ii) We propose a simple merging mechanism to average the weights of multiple adapter components to collapse to a single adapter in each Transformer layer, thereby, keeping the overall parameters also the same but with significant performance improvement. We demonstrate these techniques to work well across multiple task settings including fully supervised and few-shot Natural Language Understanding tasks. By only tuning 0.23% of a pre-trained language model's parameters, our model outperforms the full model fine-tuning performance and several competing methods.
Visually-Augmented Language Modeling
May 20, 2022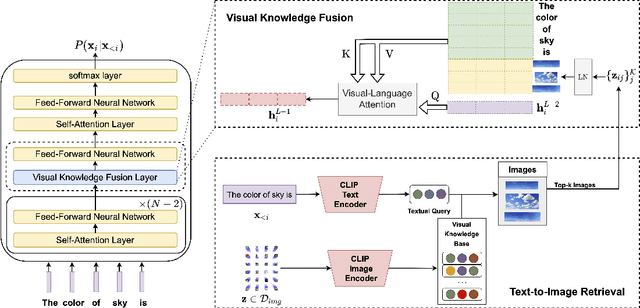

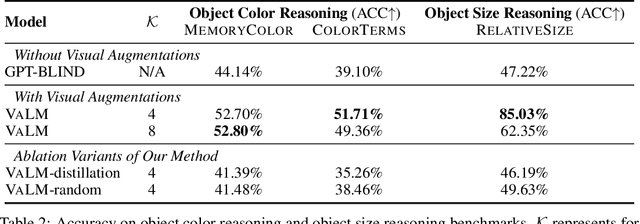
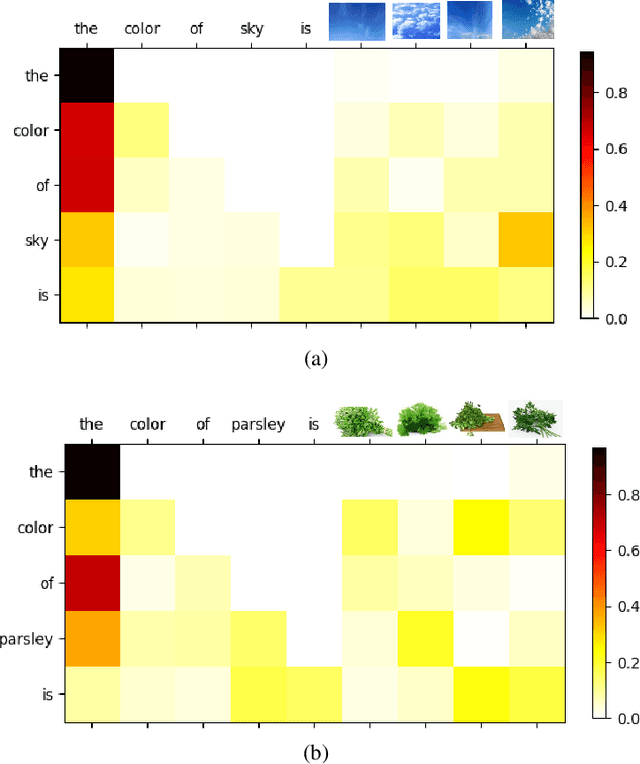
Human language is grounded on multimodal knowledge including visual knowledge like colors, sizes, and shapes. However, current large-scale pre-trained language models rely on the text-only self-supervised training with massive text data, which precludes them from utilizing relevant visual information when necessary. To address this, we propose a novel pre-training framework, named VaLM, to Visually-augment text tokens with retrieved relevant images for Language Modeling. Specifically, VaLM builds on a novel text-vision alignment method via an image retrieval module to fetch corresponding images given a textual context. With the visually-augmented context, VaLM uses a visual knowledge fusion layer to enable multimodal grounded language modeling by attending on both text context and visual knowledge in images. We evaluate the proposed model on various multimodal commonsense reasoning tasks, which require visual information to excel. VaLM outperforms the text-only baseline with substantial gains of +8.66% and +37.81% accuracy on object color and size reasoning, respectively.
METRO: Efficient Denoising Pretraining of Large Scale Autoencoding Language Models with Model Generated Signals
Apr 16, 2022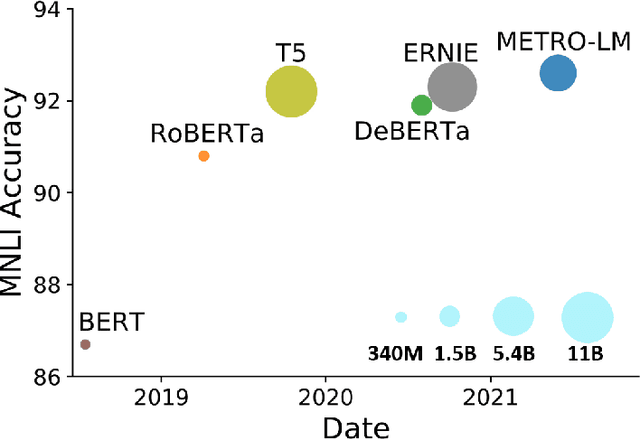
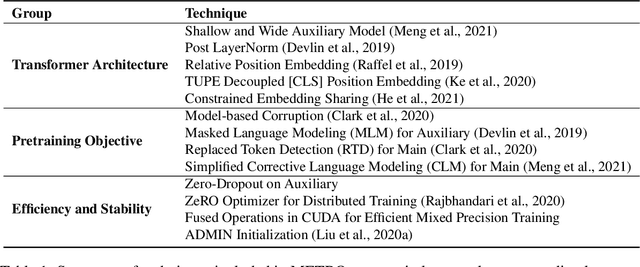
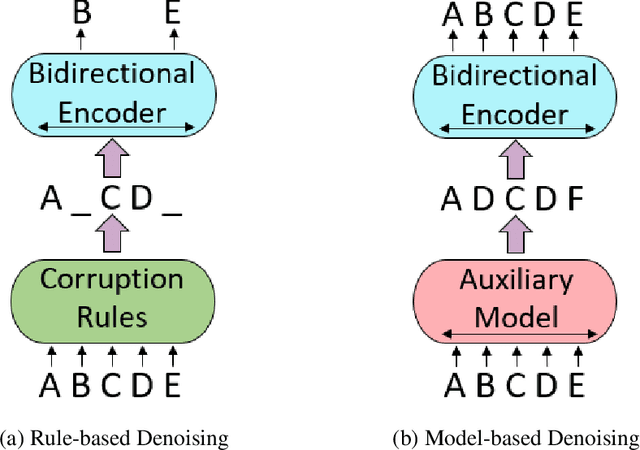
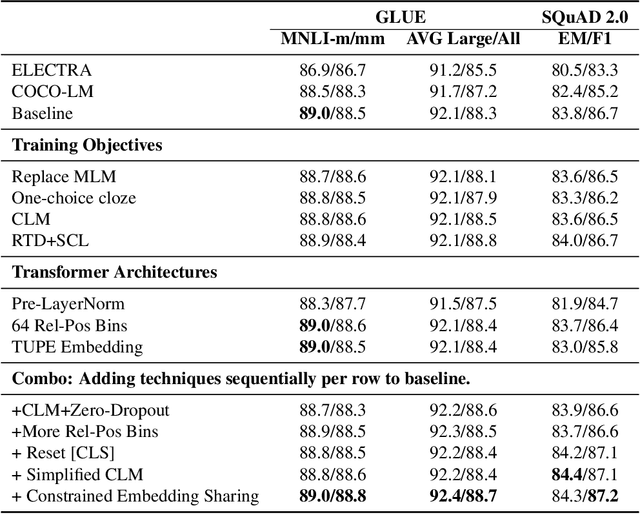
We present an efficient method of pretraining large-scale autoencoding language models using training signals generated by an auxiliary model. Originated in ELECTRA, this training strategy has demonstrated sample-efficiency to pretrain models at the scale of hundreds of millions of parameters. In this work, we conduct a comprehensive empirical study, and propose a recipe, namely "Model generated dEnoising TRaining Objective" (METRO), which incorporates some of the best modeling techniques developed recently to speed up, stabilize, and enhance pretrained language models without compromising model effectiveness. The resultant models, METRO-LM, consisting of up to 5.4 billion parameters, achieve new state-of-the-art on the GLUE, SuperGLUE, and SQuAD benchmarks. More importantly, METRO-LM are efficient in that they often outperform previous large models with significantly smaller model sizes and lower pretraining cost.
Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer
Mar 28, 2022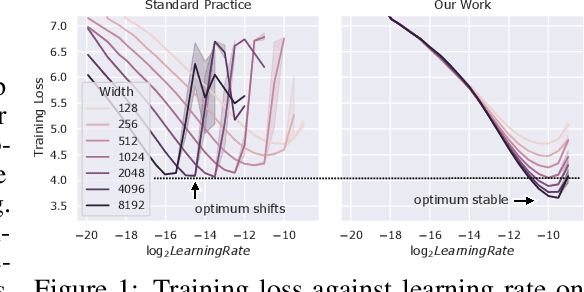

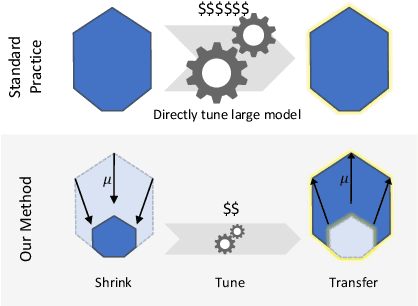

Hyperparameter (HP) tuning in deep learning is an expensive process, prohibitively so for neural networks (NNs) with billions of parameters. We show that, in the recently discovered Maximal Update Parametrization (muP), many optimal HPs remain stable even as model size changes. This leads to a new HP tuning paradigm we call muTransfer: parametrize the target model in muP, tune the HP indirectly on a smaller model, and zero-shot transfer them to the full-sized model, i.e., without directly tuning the latter at all. We verify muTransfer on Transformer and ResNet. For example, 1) by transferring pretraining HPs from a model of 13M parameters, we outperform published numbers of BERT-large (350M parameters), with a total tuning cost equivalent to pretraining BERT-large once; 2) by transferring from 40M parameters, we outperform published numbers of the 6.7B GPT-3 model, with tuning cost only 7% of total pretraining cost. A Pytorch implementation of our technique can be found at github.com/microsoft/mup and installable via `pip install mup`.