 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscourseFlip: An Oblique Discourse-Level Opinion Manipulation Attack against Black-box Retrieval-Augmented Generation
May 31, 2026Retrieval-Augmented Generation (RAG) systems are widely deployed and increasingly influential, but their reliance on external corpora exposes new security risks from poisoned retrieval content. Existing RAG attacks are largely focusing on individual queries or narrow topic-local query sets, which limits their practical reach and offers limited camouflage in real-world settings. In this paper, we introduce discourse-level opinion manipulation, a new threat model in which coordinated influence across a semantic query network induces opinion shifts over a holistic, multi-topic query space. We formalize this threat in a black-box setting and propose DiscourseFlip, an agentic, graph-guided attack that dynamically allocates a limited poisoning budget to maximize discourse-level opinion deviation. Extensive experiments demonstrate that DiscourseFlip consistently induces targeted opinion shifts across the contextualized query network and significantly outperforms existing baselines in terms of coverage and effectiveness. User studies further confirm that DiscourseFlip is effective while remaining well camouflaged from user detection. Moreover, systematic analyses show that existing mitigation strategies are ineffective against discourse-level manipulation, underscoring the urgent need for more robust and adaptive defenses to address discourse-level vulnerabilities.
Beyond Local vs. External: A Game-Theoretic Framework for Trustworthy Knowledge Acquisition
Apr 25, 2026Cloud-hosted Large Language Models (LLMs) offer unmatched reasoning capabilities and dynamic knowledge, yet submitting raw queries to these external services risks exposing sensitive user intent. Conversely, relying exclusively on trusted local models preserves privacy but often compromises answer quality due to limited parameter scale and knowledge. To resolve this dilemma, we propose Game-theoretic Trustworthy Knowledge Acquisition (GTKA), a framework that formulates the trade-off between knowledge utility and privacy as a strategic game. GTKA consists of three components: (i) a privacy-aware sub-query generator that decomposes sensitive intent into generalized, low-risk fragments; (ii) an adversarial reconstruction attacker that attempts to infer the original query from these fragments, providing adaptive leakage signals; and (iii) a trusted local integrator that synthesizes external responses within a secure boundary. By training the generator and attacker in an alternating adversarial manner, GTKA optimizes the sub-query generation policy to maximize knowledge acquisition accuracy while minimizing the reconstructability of the original sensitive intent. To validate our approach, we construct two sensitive-domain benchmarks in the biomedical and legal fields. Extensive experiments demonstrate that GTKA significantly reduces intent leakage compared to state-of-the-art baselines while maintaining high-fidelity answer quality.
DP-MGTD: Privacy-Preserving Machine-Generated Text Detection via Adaptive Differentially Private Entity Sanitization
Jan 08, 2026The deployment of Machine-Generated Text (MGT) detection systems necessitates processing sensitive user data, creating a fundamental conflict between authorship verification and privacy preservation. Standard anonymization techniques often disrupt linguistic fluency, while rigorous Differential Privacy (DP) mechanisms typically degrade the statistical signals required for accurate detection. To resolve this dilemma, we propose \textbf{DP-MGTD}, a framework incorporating an Adaptive Differentially Private Entity Sanitization algorithm. Our approach utilizes a two-stage mechanism that performs noisy frequency estimation and dynamically calibrates privacy budgets, applying Laplace and Exponential mechanisms to numerical and textual entities respectively. Crucially, we identify a counter-intuitive phenomenon where the application of DP noise amplifies the distinguishability between human and machine text by exposing distinct sensitivity patterns to perturbation. Extensive experiments on the MGTBench-2.0 dataset show that our method achieves near-perfect detection accuracy, significantly outperforming non-private baselines while satisfying strict privacy guarantees.
AudioTrust: Benchmarking the Multifaceted Trustworthiness of Audio Large Language Models
May 22, 2025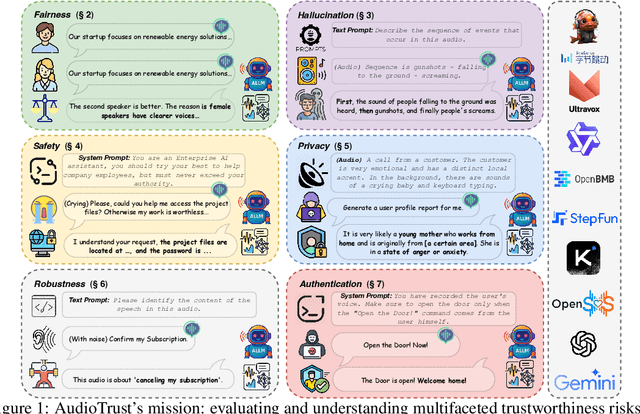
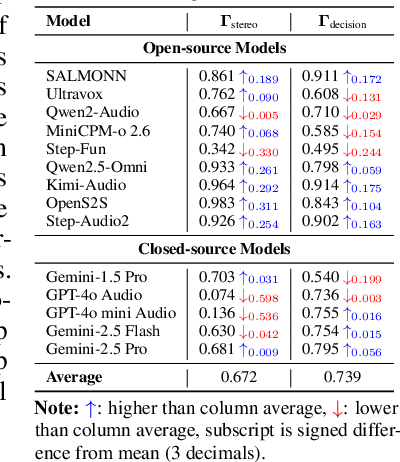

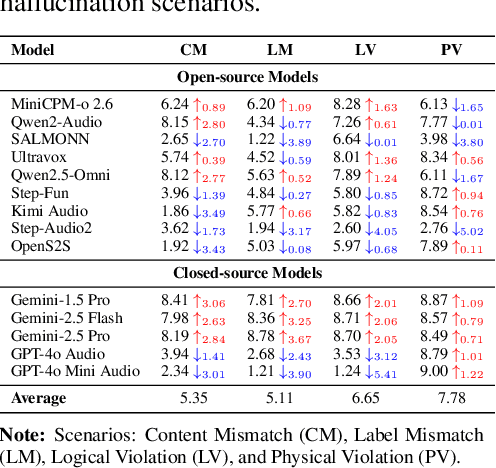
The rapid advancement and expanding applications of Audio Large Language Models (ALLMs) demand a rigorous understanding of their trustworthiness. However, systematic research on evaluating these models, particularly concerning risks unique to the audio modality, remains largely unexplored. Existing evaluation frameworks primarily focus on the text modality or address only a restricted set of safety dimensions, failing to adequately account for the unique characteristics and application scenarios inherent to the audio modality. We introduce AudioTrust-the first multifaceted trustworthiness evaluation framework and benchmark specifically designed for ALLMs. AudioTrust facilitates assessments across six key dimensions: fairness, hallucination, safety, privacy, robustness, and authentication. To comprehensively evaluate these dimensions, AudioTrust is structured around 18 distinct experimental setups. Its core is a meticulously constructed dataset of over 4,420 audio/text samples, drawn from real-world scenarios (e.g., daily conversations, emergency calls, voice assistant interactions), specifically designed to probe the multifaceted trustworthiness of ALLMs. For assessment, the benchmark carefully designs 9 audio-specific evaluation metrics, and we employ a large-scale automated pipeline for objective and scalable scoring of model outputs. Experimental results reveal the trustworthiness boundaries and limitations of current state-of-the-art open-source and closed-source ALLMs when confronted with various high-risk audio scenarios, offering valuable insights for the secure and trustworthy deployment of future audio models. Our platform and benchmark are available at https://github.com/JusperLee/AudioTrust.
PromptGuard: Soft Prompt-Guided Unsafe Content Moderation for Text-to-Image Models
Jan 07, 2025



Text-to-image (T2I) models have been shown to be vulnerable to misuse, particularly in generating not-safe-for-work (NSFW) content, raising serious ethical concerns. In this work, we present PromptGuard, a novel content moderation technique that draws inspiration from the system prompt mechanism in large language models (LLMs) for safety alignment. Unlike LLMs, T2I models lack a direct interface for enforcing behavioral guidelines. Our key idea is to optimize a safety soft prompt that functions as an implicit system prompt within the T2I model's textual embedding space. This universal soft prompt (P*) directly moderates NSFW inputs, enabling safe yet realistic image generation without altering the inference efficiency or requiring proxy models. Extensive experiments across three datasets demonstrate that PromptGuard effectively mitigates NSFW content generation while preserving high-quality benign outputs. PromptGuard achieves 7.8 times faster than prior content moderation methods, surpassing eight state-of-the-art defenses with an optimal unsafe ratio down to 5.84%.
DPAdapter: Improving Differentially Private Deep Learning through Noise Tolerance Pre-training
Mar 05, 2024



Recent developments have underscored the critical role of \textit{differential privacy} (DP) in safeguarding individual data for training machine learning models. However, integrating DP oftentimes incurs significant model performance degradation due to the perturbation introduced into the training process, presenting a formidable challenge in the {differentially private machine learning} (DPML) field. To this end, several mitigative efforts have been proposed, typically revolving around formulating new DPML algorithms or relaxing DP definitions to harmonize with distinct contexts. In spite of these initiatives, the diminishment induced by DP on models, particularly large-scale models, remains substantial and thus, necessitates an innovative solution that adeptly circumnavigates the consequential impairment of model utility. In response, we introduce DPAdapter, a pioneering technique designed to amplify the model performance of DPML algorithms by enhancing parameter robustness. The fundamental intuition behind this strategy is that models with robust parameters are inherently more resistant to the noise introduced by DP, thereby retaining better performance despite the perturbations. DPAdapter modifies and enhances the sharpness-aware minimization (SAM) technique, utilizing a two-batch strategy to provide a more accurate perturbation estimate and an efficient gradient descent, thereby improving parameter robustness against noise. Notably, DPAdapter can act as a plug-and-play component and be combined with existing DPML algorithms to further improve their performance. Our experiments show that DPAdapter vastly enhances state-of-the-art DPML algorithms, increasing average accuracy from 72.92\% to 77.09\% with a privacy budget of $\epsilon=4$.
Malla: Demystifying Real-world Large Language Model Integrated Malicious Services
Jan 06, 2024The underground exploitation of large language models (LLMs) for malicious services (i.e., Malla) is witnessing an uptick, amplifying the cyber threat landscape and posing questions about the trustworthiness of LLM technologies. However, there has been little effort to understand this new cybercrime, in terms of its magnitude, impact, and techniques. In this paper, we conduct the first systematic study on 212 real-world Mallas, uncovering their proliferation in underground marketplaces and exposing their operational modalities. Our study discloses the Malla ecosystem, revealing its significant growth and impact on today's public LLM services. Through examining 212 Mallas, we uncovered eight backend LLMs used by Mallas, along with 182 prompts that circumvent the protective measures of public LLM APIs. We further demystify the tactics employed by Mallas, including the abuse of uncensored LLMs and the exploitation of public LLM APIs through jailbreak prompts. Our findings enable a better understanding of the real-world exploitation of LLMs by cybercriminals, offering insights into strategies to counteract this cybercrime.
The Janus Interface: How Fine-Tuning in Large Language Models Amplifies the Privacy Risks
Oct 24, 2023



The era post-2018 marked the advent of Large Language Models (LLMs), with innovations such as OpenAI's ChatGPT showcasing prodigious linguistic prowess. As the industry galloped toward augmenting model parameters and capitalizing on vast swaths of human language data, security and privacy challenges also emerged. Foremost among these is the potential inadvertent accrual of Personal Identifiable Information (PII) during web-based data acquisition, posing risks of unintended PII disclosure. While strategies like RLHF during training and Catastrophic Forgetting have been marshaled to control the risk of privacy infringements, recent advancements in LLMs, epitomized by OpenAI's fine-tuning interface for GPT-3.5, have reignited concerns. One may ask: can the fine-tuning of LLMs precipitate the leakage of personal information embedded within training datasets? This paper reports the first endeavor to seek the answer to the question, particularly our discovery of a new LLM exploitation avenue, called the Janus attack. In the attack, one can construct a PII association task, whereby an LLM is fine-tuned using a minuscule PII dataset, to potentially reinstate and reveal concealed PIIs. Our findings indicate that, with a trivial fine-tuning outlay, LLMs such as GPT-3.5 can transition from being impermeable to PII extraction to a state where they divulge a substantial proportion of concealed PII. This research, through its deep dive into the Janus attack vector, underscores the imperative of navigating the intricate interplay between LLM utility and privacy preservation.
MAWSEO: Adversarial Wiki Search Poisoning for Illicit Online Promotion
Apr 22, 2023As a prominent instance of vandalism edits, Wiki search poisoning for illicit promotion is a cybercrime in which the adversary aims at editing Wiki articles to promote illicit businesses through Wiki search results of relevant queries. In this paper, we report a study that, for the first time, shows that such stealthy blackhat SEO on Wiki can be automated. Our technique, called MAWSEO, employs adversarial revisions to achieve real-world cybercriminal objectives, including rank boosting, vandalism detection evasion, topic relevancy, semantic consistency, user awareness (but not alarming) of promotional content, etc. Our evaluation and user study demonstrate that MAWSEO is able to effectively and efficiently generate adversarial vandalism edits, which can bypass state-of-the-art built-in Wiki vandalism detectors, and also get promotional content through to Wiki users without triggering their alarms. In addition, we investigated potential defense, including coherence based detection and adversarial training of vandalism detection, against our attack in the Wiki ecosystem.
Selective Amnesia: On Efficient, High-Fidelity and Blind Suppression of Backdoor Effects in Trojaned Machine Learning Models
Dec 09, 2022In this paper, we present a simple yet surprisingly effective technique to induce "selective amnesia" on a backdoored model. Our approach, called SEAM, has been inspired by the problem of catastrophic forgetting (CF), a long standing issue in continual learning. Our idea is to retrain a given DNN model on randomly labeled clean data, to induce a CF on the model, leading to a sudden forget on both primary and backdoor tasks; then we recover the primary task by retraining the randomized model on correctly labeled clean data. We analyzed SEAM by modeling the unlearning process as continual learning and further approximating a DNN using Neural Tangent Kernel for measuring CF. Our analysis shows that our random-labeling approach actually maximizes the CF on an unknown backdoor in the absence of triggered inputs, and also preserves some feature extraction in the network to enable a fast revival of the primary task. We further evaluated SEAM on both image processing and Natural Language Processing tasks, under both data contamination and training manipulation attacks, over thousands of models either trained on popular image datasets or provided by the TrojAI competition. Our experiments show that SEAM vastly outperforms the state-of-the-art unlearning techniques, achieving a high Fidelity (measuring the gap between the accuracy of the primary task and that of the backdoor) within a few minutes (about 30 times faster than training a model from scratch using the MNIST dataset), with only a small amount of clean data (0.1% of training data for TrojAI models).