 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptation of Embedding Models to Financial Filings via LLM Distillation
Dec 08, 2025Despite advances in generative large language models (LLMs), practical application of specialized conversational AI agents remains constrained by computation costs, latency requirements, and the need for precise domain-specific relevance measures. While existing embedding models address the first two constraints, they underperform on information retrieval in specialized domains like finance. This paper introduces a scalable pipeline that trains specialized models from an unlabeled corpus using a general purpose retrieval embedding model as foundation. Our method yields an average of 27.7% improvement in MRR$\texttt{@}$5, 44.6% improvement in mean DCG$\texttt{@}$5 across 14 financial filing types measured over 21,800 query-document pairs, and improved NDCG on 3 of 4 document classes in FinanceBench. We adapt retrieval embeddings (bi-encoder) for RAG, not LLM generators, using LLM-judged relevance to distill domain knowledge into a compact retriever. There are prior works which pair synthetically generated queries with real passages to directly fine-tune the retrieval model. Our pipeline differs from these by introducing interaction between student and teacher models that interleaves retrieval-based mining of hard positive/negative examples from the unlabeled corpus with iterative retraining of the student model's weights using these examples. Each retrieval iteration uses the refined student model to mine the corpus for progressively harder training examples for the subsequent training iteration. The methodology provides a cost-effective solution to bridging the gap between general-purpose models and specialized domains without requiring labor-intensive human annotation.
Towards Dark Jargon Interpretation in Underground Forums
Nov 05, 2020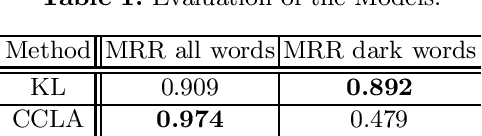
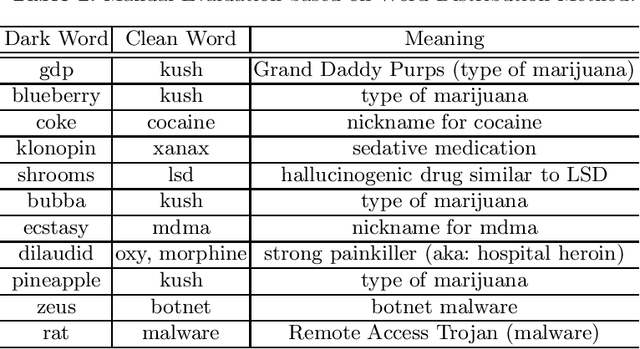
Dark jargons are benign-looking words that have hidden, sinister meanings and are used by participants of underground forums for illicit behavior. For example, the dark term "rat" is often used in lieu of "Remote Access Trojan". In this work we present a novel method towards automatically identifying and interpreting dark jargons. We formalize the problem as a mapping from dark words to "clean" words with no hidden meaning. Our method makes use of interpretable representations of dark and clean words in the form of probability distributions over a shared vocabulary. In our experiments we show our method to be effective in terms of dark jargon identification, as it outperforms another related method on simulated data. Using manual evaluation, we show that our method is able to detect dark jargons in a real-world underground forum dataset.
Identifying Compromised Accounts on Social Media Using Statistical Text Analysis
Apr 19, 2018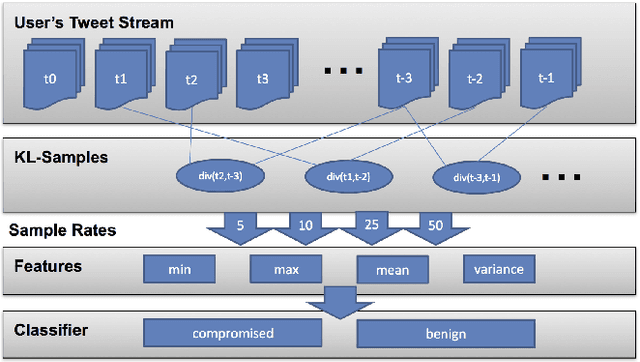
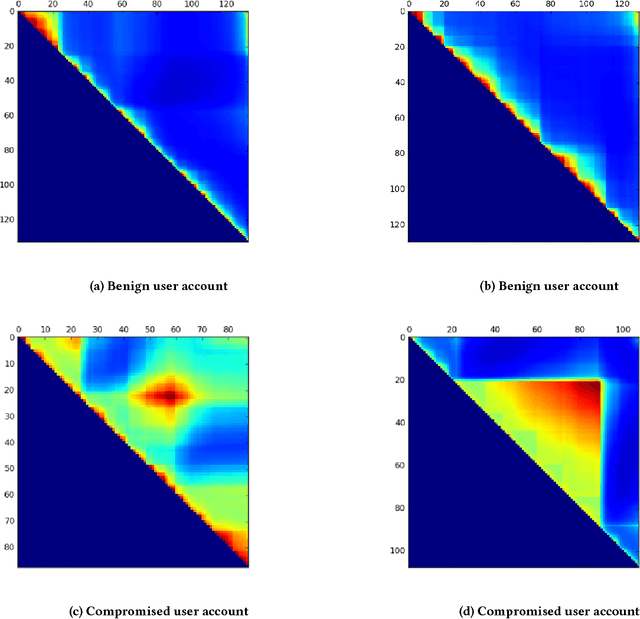
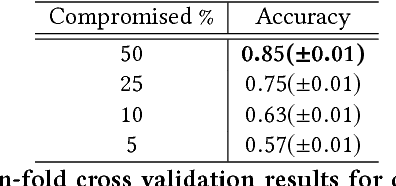
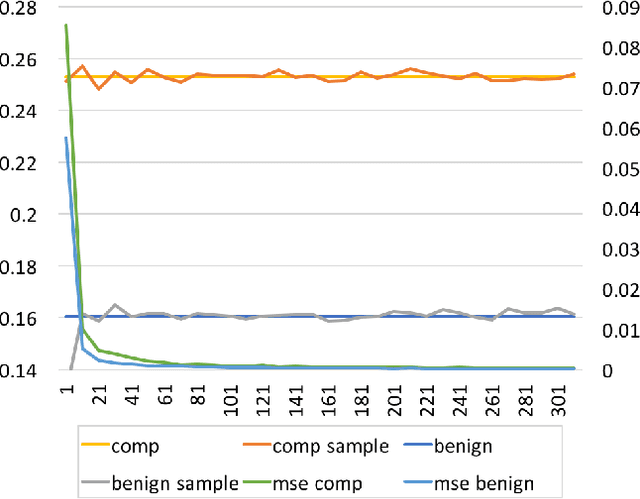
Compromised social media accounts are legitimate user accounts that have been hijacked by a third (malicious) party and can cause various kinds of damage. Early detection of such compromised accounts is very important in order to control the damage. In this work we propose a novel general framework for discovering compromised accounts by utilizing statistical text analysis. The framework is built on the observation that users will use language that is measurably different from the language that a hacker (or spammer) would use, when the account is compromised. We use the framework to develop specific algorithms based on language modeling and use the similarity of language models of users and spammers as features in a supervised learning setup to identify compromised accounts. Evaluation results on a large Twitter corpus of over 129 million tweets show promising results of the proposed approach.
KnowNER: Incremental Multilingual Knowledge in Named Entity Recognition
Sep 11, 2017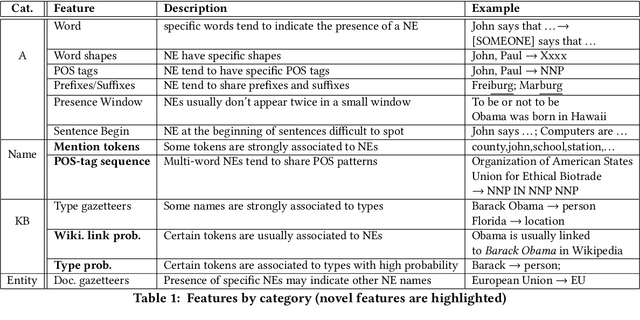
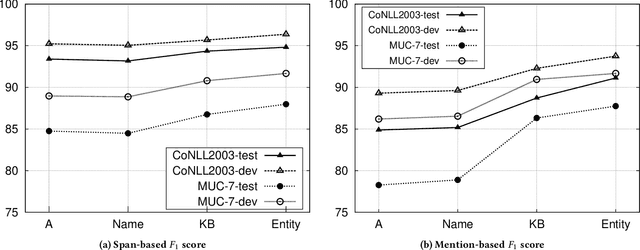
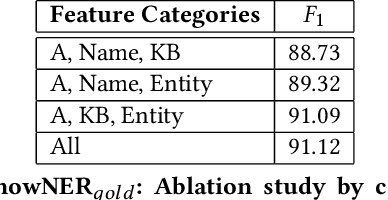
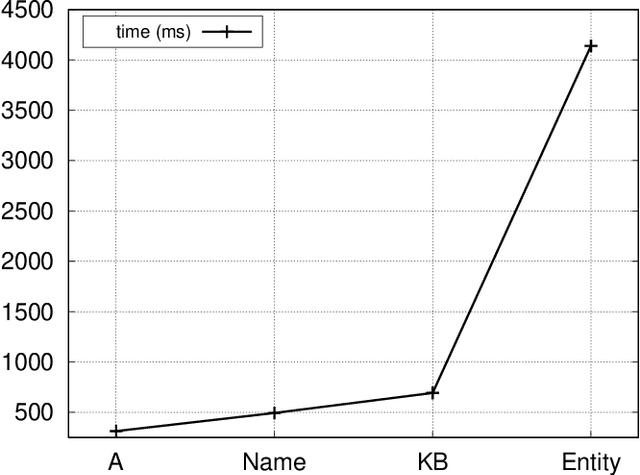
KnowNER is a multilingual Named Entity Recognition (NER) system that leverages different degrees of external knowledge. A novel modular framework divides the knowledge into four categories according to the depth of knowledge they convey. Each category consists of a set of features automatically generated from different information sources (such as a knowledge-base, a list of names or document-specific semantic annotations) and is used to train a conditional random field (CRF). Since those information sources are usually multilingual, KnowNER can be easily trained for a wide range of languages. In this paper, we show that the incorporation of deeper knowledge systematically boosts accuracy and compare KnowNER with state-of-the-art NER approaches across three languages (i.e., English, German and Spanish) performing amongst state-of-the art systems in all of them.
Knowledge Questions from Knowledge Graphs
Nov 01, 2016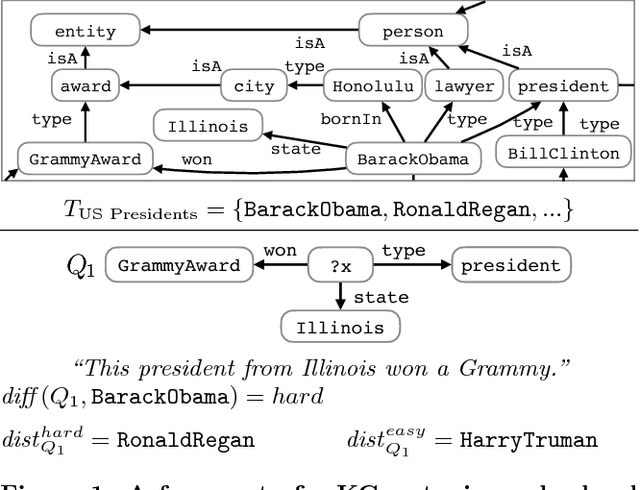
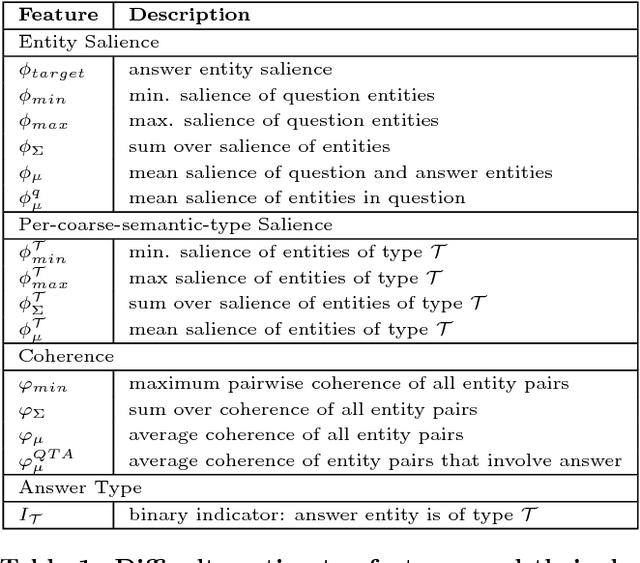
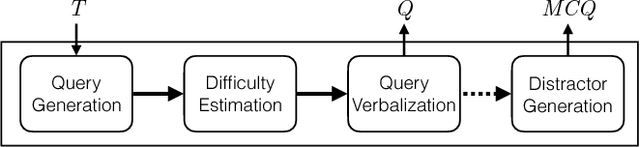
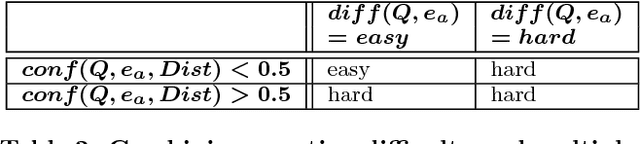
We address the novel problem of automatically generating quiz-style knowledge questions from a knowledge graph such as DBpedia. Questions of this kind have ample applications, for instance, to educate users about or to evaluate their knowledge in a specific domain. To solve the problem, we propose an end-to-end approach. The approach first selects a named entity from the knowledge graph as an answer. It then generates a structured triple-pattern query, which yields the answer as its sole result. If a multiple-choice question is desired, the approach selects alternative answer options. Finally, our approach uses a template-based method to verbalize the structured query and yield a natural language question. A key challenge is estimating how difficult the generated question is to human users. To do this, we make use of historical data from the Jeopardy! quiz show and a semantically annotated Web-scale document collection, engineer suitable features, and train a logistic regression classifier to predict question difficulty. Experiments demonstrate the viability of our overall approach.