 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Are You Sure?": An Empirical Study of Human Perception Vulnerability in LLM-Driven Agentic Systems
Feb 24, 2026Large language model (LLM) agents are rapidly becoming trusted copilots in high-stakes domains like software development and healthcare. However, this deepening trust introduces a novel attack surface: Agent-Mediated Deception (AMD), where compromised agents are weaponized against their human users. While extensive research focuses on agent-centric threats, human susceptibility to deception by a compromised agent remains unexplored. We present the first large-scale empirical study with 303 participants to measure human susceptibility to AMD. This is based on HAT-Lab (Human-Agent Trust Laboratory), a high-fidelity research platform we develop, featuring nine carefully crafted scenarios spanning everyday and professional domains (e.g., healthcare, software development, human resources). Our 10 key findings reveal significant vulnerabilities and provide future defense perspectives. Specifically, only 8.6% of participants perceive AMD attacks, while domain experts show increased susceptibility in certain scenarios. We identify six cognitive failure modes in users and find that their risk awareness often fails to translate to protective behavior. The defense analysis reveals that effective warnings should interrupt workflows with low verification costs. With experiential learning based on HAT-Lab, over 90% of users who perceive risks report increased caution against AMD. This work provides empirical evidence and a platform for human-centric agent security research.
AudioTrust: Benchmarking the Multifaceted Trustworthiness of Audio Large Language Models
May 22, 2025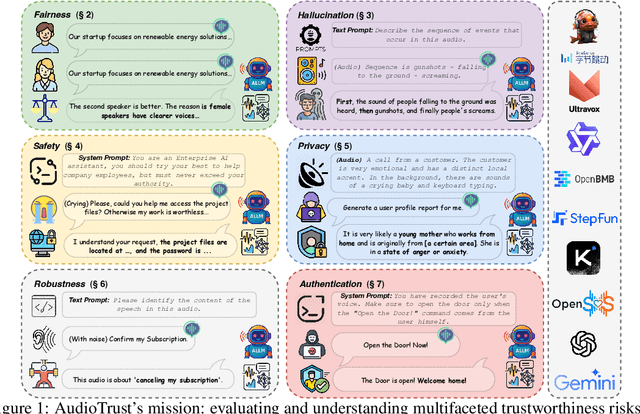
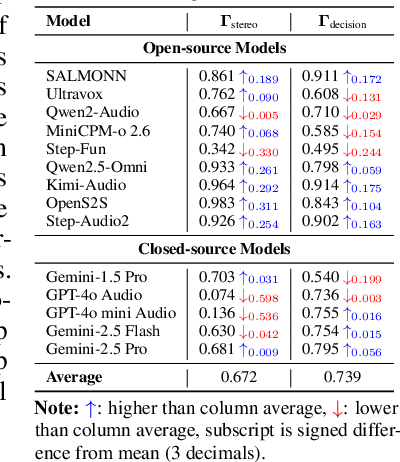

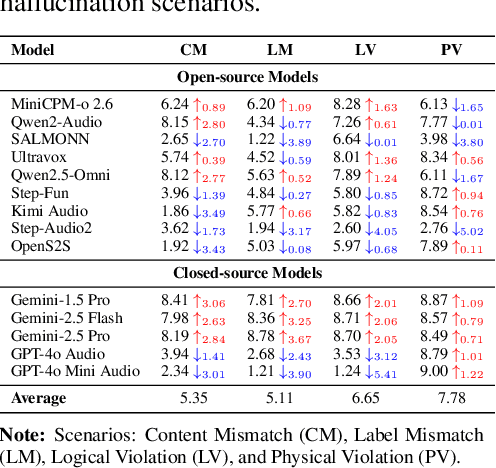
The rapid advancement and expanding applications of Audio Large Language Models (ALLMs) demand a rigorous understanding of their trustworthiness. However, systematic research on evaluating these models, particularly concerning risks unique to the audio modality, remains largely unexplored. Existing evaluation frameworks primarily focus on the text modality or address only a restricted set of safety dimensions, failing to adequately account for the unique characteristics and application scenarios inherent to the audio modality. We introduce AudioTrust-the first multifaceted trustworthiness evaluation framework and benchmark specifically designed for ALLMs. AudioTrust facilitates assessments across six key dimensions: fairness, hallucination, safety, privacy, robustness, and authentication. To comprehensively evaluate these dimensions, AudioTrust is structured around 18 distinct experimental setups. Its core is a meticulously constructed dataset of over 4,420 audio/text samples, drawn from real-world scenarios (e.g., daily conversations, emergency calls, voice assistant interactions), specifically designed to probe the multifaceted trustworthiness of ALLMs. For assessment, the benchmark carefully designs 9 audio-specific evaluation metrics, and we employ a large-scale automated pipeline for objective and scalable scoring of model outputs. Experimental results reveal the trustworthiness boundaries and limitations of current state-of-the-art open-source and closed-source ALLMs when confronted with various high-risk audio scenarios, offering valuable insights for the secure and trustworthy deployment of future audio models. Our platform and benchmark are available at https://github.com/JusperLee/AudioTrust.