 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudioTrust: Benchmarking the Multifaceted Trustworthiness of Audio Large Language Models
May 22, 2025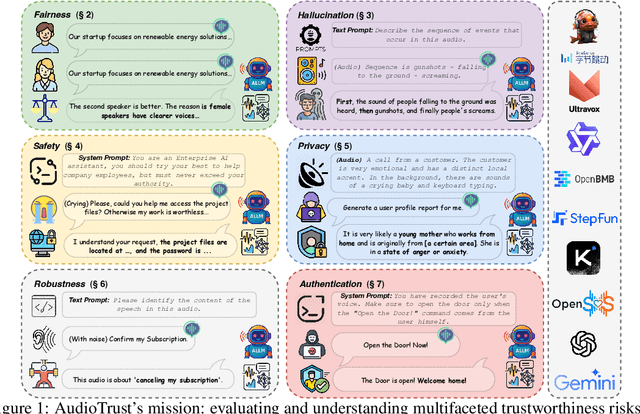
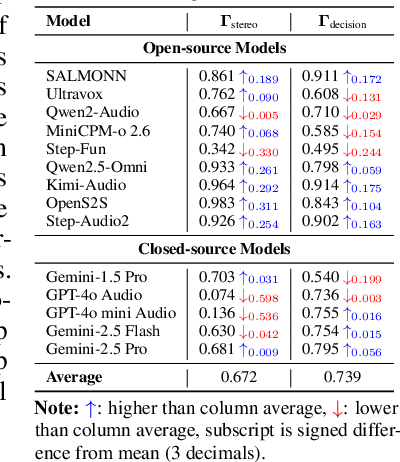

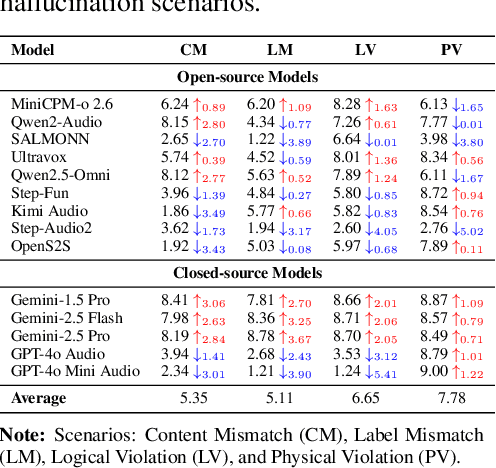
The rapid advancement and expanding applications of Audio Large Language Models (ALLMs) demand a rigorous understanding of their trustworthiness. However, systematic research on evaluating these models, particularly concerning risks unique to the audio modality, remains largely unexplored. Existing evaluation frameworks primarily focus on the text modality or address only a restricted set of safety dimensions, failing to adequately account for the unique characteristics and application scenarios inherent to the audio modality. We introduce AudioTrust-the first multifaceted trustworthiness evaluation framework and benchmark specifically designed for ALLMs. AudioTrust facilitates assessments across six key dimensions: fairness, hallucination, safety, privacy, robustness, and authentication. To comprehensively evaluate these dimensions, AudioTrust is structured around 18 distinct experimental setups. Its core is a meticulously constructed dataset of over 4,420 audio/text samples, drawn from real-world scenarios (e.g., daily conversations, emergency calls, voice assistant interactions), specifically designed to probe the multifaceted trustworthiness of ALLMs. For assessment, the benchmark carefully designs 9 audio-specific evaluation metrics, and we employ a large-scale automated pipeline for objective and scalable scoring of model outputs. Experimental results reveal the trustworthiness boundaries and limitations of current state-of-the-art open-source and closed-source ALLMs when confronted with various high-risk audio scenarios, offering valuable insights for the secure and trustworthy deployment of future audio models. Our platform and benchmark are available at https://github.com/JusperLee/AudioTrust.
LGmap: Local-to-Global Mapping Network for Online Long-Range Vectorized HD Map Construction
Jun 20, 2024This report introduces the first-place winning solution for the Autonomous Grand Challenge 2024 - Mapless Driving. In this report, we introduce a novel online mapping pipeline LGmap, which adept at long-range temporal model. Firstly, we propose symmetric view transformation(SVT), a hybrid view transformation module. Our approach overcomes the limitations of forward sparse feature representation and utilizing depth perception and SD prior information. Secondly, we propose hierarchical temporal fusion(HTF) module. It employs temporal information from local to global, which empowers the construction of long-range HD map with high stability. Lastly, we propose a novel ped-crossing resampling. The simplified ped crossing representation accelerates the instance attention based decoder convergence performance. Our method achieves 0.66 UniScore in the Mapless Driving OpenLaneV2 test set.