 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Models Ace the CFA Exams
Dec 09, 2025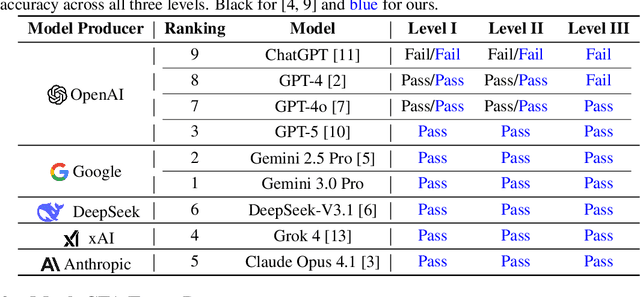
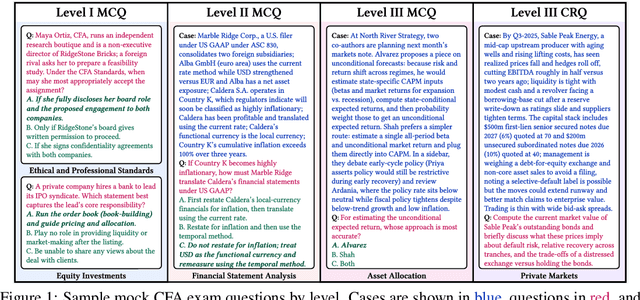
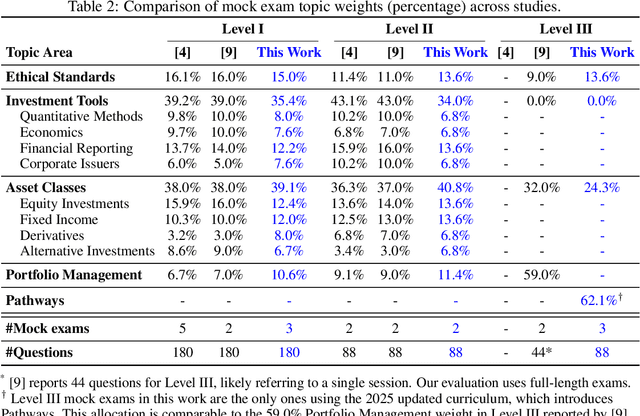
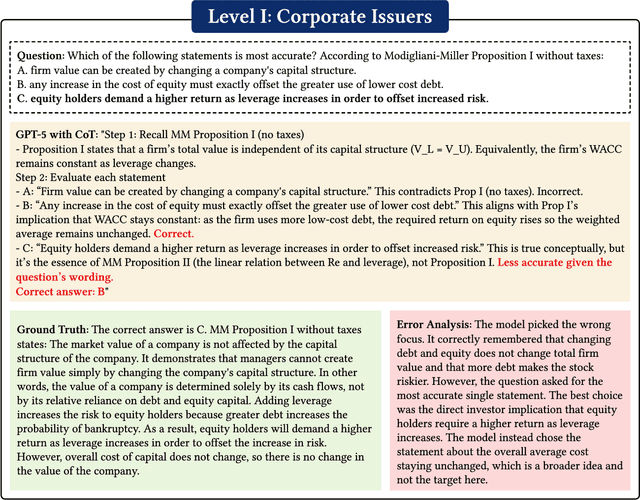
Previous research has reported that large language models (LLMs) demonstrate poor performance on the Chartered Financial Analyst (CFA) exams. However, recent reasoning models have achieved strong results on graduate-level academic and professional examinations across various disciplines. In this paper, we evaluate state-of-the-art reasoning models on a set of mock CFA exams consisting of 980 questions across three Level I exams, two Level II exams, and three Level III exams. Using the same pass/fail criteria from prior studies, we find that most models clear all three levels. The models that pass, ordered by overall performance, are Gemini 3.0 Pro, Gemini 2.5 Pro, GPT-5, Grok 4, Claude Opus 4.1, and DeepSeek-V3.1. Specifically, Gemini 3.0 Pro achieves a record score of 97.6% on Level I. Performance is also strong on Level II, led by GPT-5 at 94.3%. On Level III, Gemini 2.5 Pro attains the highest score with 86.4% on multiple-choice questions while Gemini 3.0 Pro achieves 92.0% on constructed-response questions.
Deep Reinforcement Learning for Automated Stock Trading: An Ensemble Strategy
Nov 15, 2025



Stock trading strategies play a critical role in investment. However, it is challenging to design a profitable strategy in a complex and dynamic stock market. In this paper, we propose an ensemble strategy that employs deep reinforcement schemes to learn a stock trading strategy by maximizing investment return. We train a deep reinforcement learning agent and obtain an ensemble trading strategy using three actor-critic based algorithms: Proximal Policy Optimization (PPO), Advantage Actor Critic (A2C), and Deep Deterministic Policy Gradient (DDPG). The ensemble strategy inherits and integrates the best features of the three algorithms, thereby robustly adjusting to different market situations. In order to avoid the large memory consumption in training networks with continuous action space, we employ a load-on-demand technique for processing very large data. We test our algorithms on the 30 Dow Jones stocks that have adequate liquidity. The performance of the trading agent with different reinforcement learning algorithms is evaluated and compared with both the Dow Jones Industrial Average index and the traditional min-variance portfolio allocation strategy. The proposed deep ensemble strategy is shown to outperform the three individual algorithms and two baselines in terms of the risk-adjusted return measured by the Sharpe ratio. This work is fully open-sourced at \href{https://github.com/AI4Finance-Foundation/Deep-Reinforcement-Learning-for-Automated-Stock-Trading-Ensemble-Strategy-ICAIF-2020}{GitHub}.
FinTagging: An LLM-ready Benchmark for Extracting and Structuring Financial Information
May 27, 2025We introduce FinTagging, the first full-scope, table-aware XBRL benchmark designed to evaluate the structured information extraction and semantic alignment capabilities of large language models (LLMs) in the context of XBRL-based financial reporting. Unlike prior benchmarks that oversimplify XBRL tagging as flat multi-class classification and focus solely on narrative text, FinTagging decomposes the XBRL tagging problem into two subtasks: FinNI for financial entity extraction and FinCL for taxonomy-driven concept alignment. It requires models to jointly extract facts and align them with the full 10k+ US-GAAP taxonomy across both unstructured text and structured tables, enabling realistic, fine-grained evaluation. We assess a diverse set of LLMs under zero-shot settings, systematically analyzing their performance on both subtasks and overall tagging accuracy. Our results reveal that, while LLMs demonstrate strong generalization in information extraction, they struggle with fine-grained concept alignment, particularly in disambiguating closely related taxonomy entries. These findings highlight the limitations of existing LLMs in fully automating XBRL tagging and underscore the need for improved semantic reasoning and schema-aware modeling to meet the demands of accurate financial disclosure. Code is available at our GitHub repository and data is at our Hugging Face repository.
FinLoRA: Benchmarking LoRA Methods for Fine-Tuning LLMs on Financial Datasets
May 26, 2025Low-rank adaptation (LoRA) methods show great potential for scaling pre-trained general-purpose Large Language Models (LLMs) to hundreds or thousands of use scenarios. However, their efficacy in high-stakes domains like finance is rarely explored, e.g., passing CFA exams and analyzing SEC filings. In this paper, we present the open-source FinLoRA project that benchmarks LoRA methods on both general and highly professional financial tasks. First, we curated 19 datasets covering diverse financial applications; in particular, we created four novel XBRL analysis datasets based on 150 SEC filings. Second, we evaluated five LoRA methods and five base LLMs. Finally, we provide extensive experimental results in terms of accuracy, F1, and BERTScore and report computational cost in terms of time and GPU memory during fine-tuning and inference stages. We find that LoRA methods achieved substantial performance gains of 36\% on average over base models. Our FinLoRA project provides an affordable and scalable approach to democratize financial intelligence to the general public. Datasets, LoRA adapters, code, and documentation are available at https://github.com/Open-Finance-Lab/FinLoRA
FLAG-Trader: Fusion LLM-Agent with Gradient-based Reinforcement Learning for Financial Trading
Feb 19, 2025



Large language models (LLMs) fine-tuned on multimodal financial data have demonstrated impressive reasoning capabilities in various financial tasks. However, they often struggle with multi-step, goal-oriented scenarios in interactive financial markets, such as trading, where complex agentic approaches are required to improve decision-making. To address this, we propose \textsc{FLAG-Trader}, a unified architecture integrating linguistic processing (via LLMs) with gradient-driven reinforcement learning (RL) policy optimization, in which a partially fine-tuned LLM acts as the policy network, leveraging pre-trained knowledge while adapting to the financial domain through parameter-efficient fine-tuning. Through policy gradient optimization driven by trading rewards, our framework not only enhances LLM performance in trading but also improves results on other financial-domain tasks. We present extensive empirical evidence to validate these enhancements.
Reinforcement Learning for Quantum Circuit Design: Using Matrix Representations
Jan 27, 2025Quantum computing promises advantages over classical computing. The manufacturing of quantum hardware is in the infancy stage, called the Noisy Intermediate-Scale Quantum (NISQ) era. A major challenge is automated quantum circuit design that map a quantum circuit to gates in a universal gate set. In this paper, we present a generic MDP modeling and employ Q-learning and DQN algorithms for quantum circuit design. By leveraging the power of deep reinforcement learning, we aim to provide an automatic and scalable approach over traditional hand-crafted heuristic methods.
FinLoRA: Finetuning Quantized Financial Large Language Models Using Low-Rank Adaptation
Dec 16, 2024



Finetuned large language models (LLMs) have shown remarkable performance in financial tasks, such as sentiment analysis and information retrieval. Due to privacy concerns, finetuning and deploying Financial LLMs (FinLLMs) locally are crucial for institutions. However, finetuning FinLLMs poses challenges including GPU memory constraints and long input sequences. In this paper, we employ quantized low-rank adaptation (QLoRA) to finetune FinLLMs, which leverage low-rank matrix decomposition and quantization techniques to significantly reduce computational requirements while maintaining high model performance. We also employ data and pipeline parallelism to enable local finetuning using cost-effective, widely accessible GPUs. Experiments on financial datasets demonstrate that our method achieves substantial improvements in accuracy, GPU memory usage, and time efficiency, underscoring the potential of lowrank methods for scalable and resource-efficient LLM finetuning.
Quantum-inspired Reinforcement Learning for Synthesizable Drug Design
Sep 13, 2024Synthesizable molecular design (also known as synthesizable molecular optimization) is a fundamental problem in drug discovery, and involves designing novel molecular structures to improve their properties according to drug-relevant oracle functions (i.e., objective) while ensuring synthetic feasibility. However, existing methods are mostly based on random search. To address this issue, in this paper, we introduce a novel approach using the reinforcement learning method with quantum-inspired simulated annealing policy neural network to navigate the vast discrete space of chemical structures intelligently. Specifically, we employ a deterministic REINFORCE algorithm using policy neural networks to output transitional probability to guide state transitions and local search using genetic algorithm to refine solutions to a local optimum within each iteration. Our methods are evaluated with the Practical Molecular Optimization (PMO) benchmark framework with a 10K query budget. We further showcase the competitive performance of our method by comparing it against the state-of-the-art genetic algorithms-based method.
Open-FinLLMs: Open Multimodal Large Language Models for Financial Applications
Aug 20, 2024



Large language models (LLMs) have advanced financial applications, yet they often lack sufficient financial knowledge and struggle with tasks involving multi-modal inputs like tables and time series data. To address these limitations, we introduce \textit{Open-FinLLMs}, a series of Financial LLMs. We begin with FinLLaMA, pre-trained on a 52 billion token financial corpus, incorporating text, tables, and time-series data to embed comprehensive financial knowledge. FinLLaMA is then instruction fine-tuned with 573K financial instructions, resulting in FinLLaMA-instruct, which enhances task performance. Finally, we present FinLLaVA, a multimodal LLM trained with 1.43M image-text instructions to handle complex financial data types. Extensive evaluations demonstrate FinLLaMA's superior performance over LLaMA3-8B, LLaMA3.1-8B, and BloombergGPT in both zero-shot and few-shot settings across 19 and 4 datasets, respectively. FinLLaMA-instruct outperforms GPT-4 and other Financial LLMs on 15 datasets. FinLLaVA excels in understanding tables and charts across 4 multimodal tasks. Additionally, FinLLaMA achieves impressive Sharpe Ratios in trading simulations, highlighting its robust financial application capabilities. We will continually maintain and improve our models and benchmarks to support ongoing innovation in academia and industry.
FinGPT-HPC: Efficient Pretraining and Finetuning Large Language Models for Financial Applications with High-Performance Computing
Feb 21, 2024Large language models (LLMs) are computationally intensive. The computation workload and the memory footprint grow quadratically with the dimension (layer width). Most of LLMs' parameters come from the linear layers of the transformer structure and are highly redundant. These linear layers contribute more than 80% of the computation workload and 99% of the model size. To pretrain and finetune LLMs efficiently, there are three major challenges to address: 1) reducing redundancy of the linear layers; 2) reducing GPU memory footprint; 3) improving GPU utilization when using distributed training. Prior methods, such as LoRA and QLoRA, utilized low-rank matrices and quantization to reduce the number of trainable parameters and model size, respectively. However, the resulting model still consumes a large amount of GPU memory. In this paper, we present high-performance GPU-based methods that exploit low-rank structures to pretrain and finetune LLMs for financial applications. We replace one conventional linear layer of the transformer structure with two narrower linear layers, which allows us to reduce the number of parameters by several orders of magnitude. By quantizing the parameters into low precision (8-bit and 4-bit), the memory consumption of the resulting model is further reduced. Compared with existing LLMs, our methods achieve a speedup of 1.3X and a model compression ratio of 2.64X for pretaining without accuracy drop. For finetuning, our methods achieve an average accuracy increase of 6.3% and 24.0% in general tasks and financial tasks, respectively, and GPU memory consumption ratio of 6.3X. The sizes of our models are smaller than 0.59 GB, allowing inference on a smartphone.