 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGated Graph Attention Networks for Predicting Duration of Large Scale Power Outages Induced by Natural Disasters
Mar 14, 2026The occurrence of large-scale power outages induced by natural disasters has been on the rise in a changing climate. Such power outages often last extended durations, causing substantial financial losses and socioeconomic impacts to customers. Accurate estimation of outage duration is thus critical for enhancing the resilience of energy infrastructure under severe weather. We formulate such a task as a machine learning (ML) problem with focus on unique real-world challenges: high-order spatial dependency in the data, a moderate number of large-scale outage events, heterogeneous types of such events, and different impacts in a region within each event. To address these challenges, we develop a Bimodal Gated Graph Attention Network (BiGGAT), a graph-based neural network model, that integrates a Graph Attention Network (GAT) with a Gated Recurrent Unit (GRU) to capture the complex spatial characteristics. We evaluate the approach in a setting of inductive learning, using large-scale power outage data from six major hurricanes in the Southeastern United States. Experimental results demonstrate that BiGGAT achieves a superior performance compared to benchmark models.
Deep Reinforcement Learning for Automated Stock Trading: An Ensemble Strategy
Nov 15, 2025



Stock trading strategies play a critical role in investment. However, it is challenging to design a profitable strategy in a complex and dynamic stock market. In this paper, we propose an ensemble strategy that employs deep reinforcement schemes to learn a stock trading strategy by maximizing investment return. We train a deep reinforcement learning agent and obtain an ensemble trading strategy using three actor-critic based algorithms: Proximal Policy Optimization (PPO), Advantage Actor Critic (A2C), and Deep Deterministic Policy Gradient (DDPG). The ensemble strategy inherits and integrates the best features of the three algorithms, thereby robustly adjusting to different market situations. In order to avoid the large memory consumption in training networks with continuous action space, we employ a load-on-demand technique for processing very large data. We test our algorithms on the 30 Dow Jones stocks that have adequate liquidity. The performance of the trading agent with different reinforcement learning algorithms is evaluated and compared with both the Dow Jones Industrial Average index and the traditional min-variance portfolio allocation strategy. The proposed deep ensemble strategy is shown to outperform the three individual algorithms and two baselines in terms of the risk-adjusted return measured by the Sharpe ratio. This work is fully open-sourced at \href{https://github.com/AI4Finance-Foundation/Deep-Reinforcement-Learning-for-Automated-Stock-Trading-Ensemble-Strategy-ICAIF-2020}{GitHub}.
Distilling Large Language Models for Network Active Queue Management
Jan 28, 2025



The growing complexity of network traffic and demand for ultra-low latency communication require smarter packet traffic management. Existing Deep Learning-based queuing approaches struggle with dynamic network scenarios and demand high engineering effort. We propose AQM-LLM, distilling Large Language Models (LLMs) with few-shot learning, contextual understanding, and pattern recognition to improve Active Queue Management (AQM) [RFC 9330] with minimal manual effort. We consider a specific case where AQM is Low Latency, Low Loss, and Scalable Throughput (L4S) and our design of AQM-LLM builds on speculative decoding and reinforcement-based distilling of LLM by tackling congestion prevention in the L4S architecture using Explicit Congestion Notification (ECN) [RFC 9331] and periodic packet dropping. We develop a new open-source experimental platform by executing L4S-AQM on FreeBSD-14, providing interoperable modules to support LLM integration and facilitate IETF recognition through wider testing. Our extensive evaluations show L4S-LLM enhances queue management, prevents congestion, reduces latency, and boosts network performance, showcasing LLMs' adaptability and efficiency in uplifting AQM systems.
* 11 pages
FinGPT-HPC: Efficient Pretraining and Finetuning Large Language Models for Financial Applications with High-Performance Computing
Feb 21, 2024Large language models (LLMs) are computationally intensive. The computation workload and the memory footprint grow quadratically with the dimension (layer width). Most of LLMs' parameters come from the linear layers of the transformer structure and are highly redundant. These linear layers contribute more than 80% of the computation workload and 99% of the model size. To pretrain and finetune LLMs efficiently, there are three major challenges to address: 1) reducing redundancy of the linear layers; 2) reducing GPU memory footprint; 3) improving GPU utilization when using distributed training. Prior methods, such as LoRA and QLoRA, utilized low-rank matrices and quantization to reduce the number of trainable parameters and model size, respectively. However, the resulting model still consumes a large amount of GPU memory. In this paper, we present high-performance GPU-based methods that exploit low-rank structures to pretrain and finetune LLMs for financial applications. We replace one conventional linear layer of the transformer structure with two narrower linear layers, which allows us to reduce the number of parameters by several orders of magnitude. By quantizing the parameters into low precision (8-bit and 4-bit), the memory consumption of the resulting model is further reduced. Compared with existing LLMs, our methods achieve a speedup of 1.3X and a model compression ratio of 2.64X for pretaining without accuracy drop. For finetuning, our methods achieve an average accuracy increase of 6.3% and 24.0% in general tasks and financial tasks, respectively, and GPU memory consumption ratio of 6.3X. The sizes of our models are smaller than 0.59 GB, allowing inference on a smartphone.
Deep Reinforcement Learning for Traffic Light Control in Intelligent Transportation Systems
Feb 04, 2023Smart traffic lights in intelligent transportation systems (ITSs) are envisioned to greatly increase traffic efficiency and reduce congestion. Deep reinforcement learning (DRL) is a promising approach to adaptively control traffic lights based on the real-time traffic situation in a road network. However, conventional methods may suffer from poor scalability. In this paper, we investigate deep reinforcement learning to control traffic lights, and both theoretical analysis and numerical experiments show that the intelligent behavior ``greenwave" (i.e., a vehicle will see a progressive cascade of green lights, and not have to brake at any intersection) emerges naturally a grid road network, which is proved to be the optimal policy in an avenue with multiple cross streets. As a first step, we use two DRL algorithms for the traffic light control problems in two scenarios. In a single road intersection, we verify that the deep Q-network (DQN) algorithm delivers a thresholding policy; and in a grid road network, we adopt the deep deterministic policy gradient (DDPG) algorithm. Secondly, numerical experiments show that the DQN algorithm delivers the optimal control, and the DDPG algorithm with passive observations has the capability to produce on its own a high-level intelligent behavior in a grid road network, namely, the ``greenwave" policy emerges. We also verify the ``greenwave" patterns in a $5 \times 10$ grid road network. Thirdly, the ``greenwave" patterns demonstrate that DRL algorithms produce favorable solutions since the ``greenwave" policy shown in experiment results is proved to be optimal in a specified traffic model (an avenue with multiple cross streets). The delivered policies both in a single road intersection and a grid road network demonstrate the scalability of DRL algorithms.
* 17 pages
Fair and Efficient Distributed Edge Learning with Hybrid Multipath TCP
Nov 03, 2022



The bottleneck of distributed edge learning (DEL) over wireless has shifted from computing to communication, primarily the aggregation-averaging (Agg-Avg) process of DEL. The existing transmission control protocol (TCP)-based data networking schemes for DEL are application-agnostic and fail to deliver adjustments according to application layer requirements. As a result, they introduce massive excess time and undesired issues such as unfairness and stragglers. Other prior mitigation solutions have significant limitations as they balance data flow rates from workers across paths but often incur imbalanced backlogs when the paths exhibit variance, causing stragglers. To facilitate a more productive DEL, we develop a hybrid multipath TCP (MPTCP) by combining model-based and deep reinforcement learning (DRL) based MPTCP for DEL that strives to realize quicker iteration of DEL and better fairness (by ameliorating stragglers). Hybrid MPTCP essentially integrates two radical TCP developments: i) successful existing model-based MPTCP control strategies and ii) advanced emerging DRL-based techniques, and introduces a novel hybrid MPTCP data transport for easing the communication of the Agg-Avg process. Extensive emulation results demonstrate that the proposed hybrid MPTCP can overcome excess time consumption and ameliorate the application layer unfairness of DEL effectively without injecting additional inconstancy and stragglers.
Regenerative Particle Thompson Sampling
Mar 15, 2022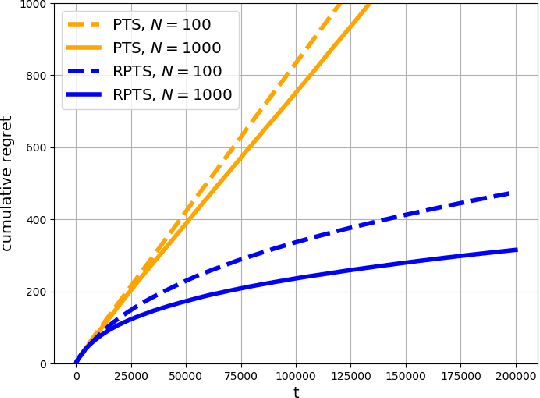

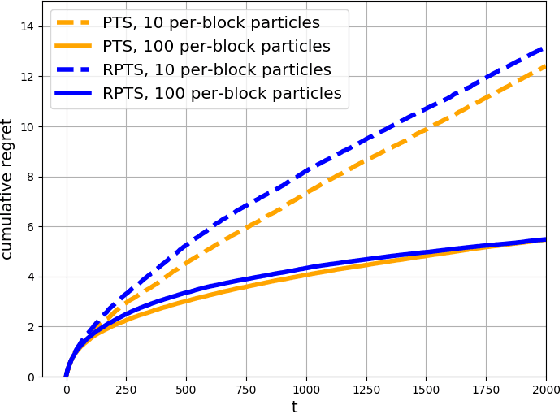
This paper proposes regenerative particle Thompson sampling (RPTS), a flexible variation of Thompson sampling. Thompson sampling itself is a Bayesian heuristic for solving stochastic bandit problems, but it is hard to implement in practice due to the intractability of maintaining a continuous posterior distribution. Particle Thompson sampling (PTS) is an approximation of Thompson sampling obtained by simply replacing the continuous distribution by a discrete distribution supported at a set of weighted static particles. We observe that in PTS, the weights of all but a few fit particles converge to zero. RPTS is based on the heuristic: delete the decaying unfit particles and regenerate new particles in the vicinity of fit surviving particles. Empirical evidence shows uniform improvement from PTS to RPTS and flexibility and efficacy of RPTS across a set of representative bandit problems, including an application to 5G network slicing.
ElegantRL-Podracer: Scalable and Elastic Library for Cloud-Native Deep Reinforcement Learning
Dec 11, 2021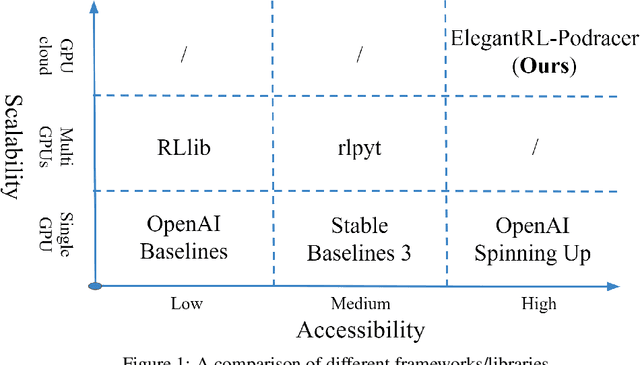
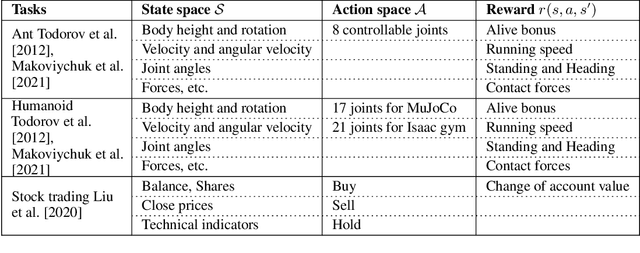
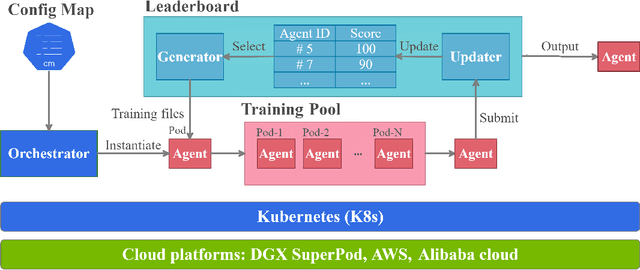

Deep reinforcement learning (DRL) has revolutionized learning and actuation in applications such as game playing and robotic control. The cost of data collection, i.e., generating transitions from agent-environment interactions, remains a major challenge for wider DRL adoption in complex real-world problems. Following a cloud-native paradigm to train DRL agents on a GPU cloud platform is a promising solution. In this paper, we present a scalable and elastic library ElegantRL-podracer for cloud-native deep reinforcement learning, which efficiently supports millions of GPU cores to carry out massively parallel training at multiple levels. At a high-level, ElegantRL-podracer employs a tournament-based ensemble scheme to orchestrate the training process on hundreds or even thousands of GPUs, scheduling the interactions between a leaderboard and a training pool with hundreds of pods. At a low-level, each pod simulates agent-environment interactions in parallel by fully utilizing nearly 7,000 GPU CUDA cores in a single GPU. Our ElegantRL-podracer library features high scalability, elasticity and accessibility by following the development principles of containerization, microservices and MLOps. Using an NVIDIA DGX SuperPOD cloud, we conduct extensive experiments on various tasks in locomotion and stock trading and show that ElegantRL-podracer substantially outperforms RLlib. Our codes are available on GitHub.
* 9 pages, 7 figures
Emerging Trends in Federated Learning: From Model Fusion to Federated X Learning
Feb 25, 2021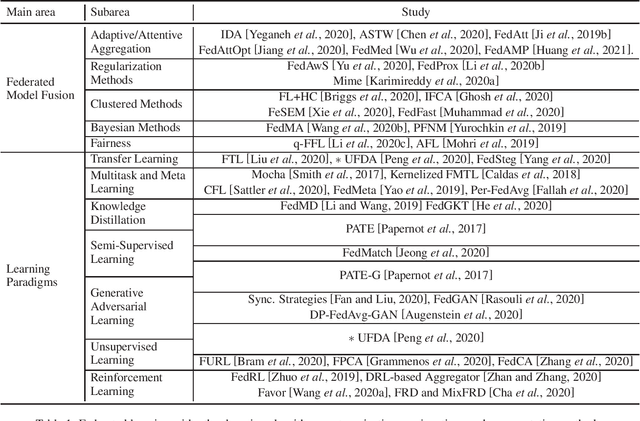
Federated learning is a new learning paradigm that decouples data collection and model training via multi-party computation and model aggregation. As a flexible learning setting, federated learning has the potential to integrate with other learning frameworks. We conduct a focused survey of federated learning in conjunction with other learning algorithms. Specifically, we explore various learning algorithms to improve the vanilla federated averaging algorithm and review model fusion methods such as adaptive aggregation, regularization, clustered methods, and Bayesian methods. Following the emerging trends, we also discuss federated learning in the intersection with other learning paradigms, termed as federated x learning, where x includes multitask learning, meta-learning, transfer learning, unsupervised learning, and reinforcement learning. This survey reviews the state of the art, challenges, and future directions.
Privacy-preserving Decentralized Aggregation for Federated Learning
Dec 28, 2020
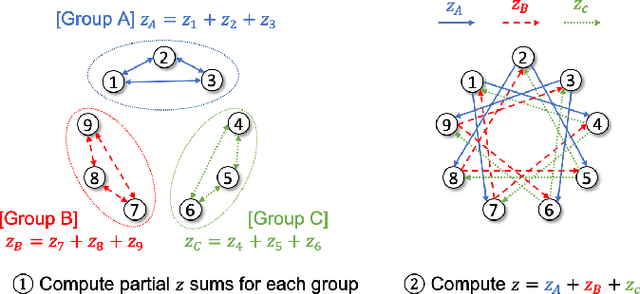
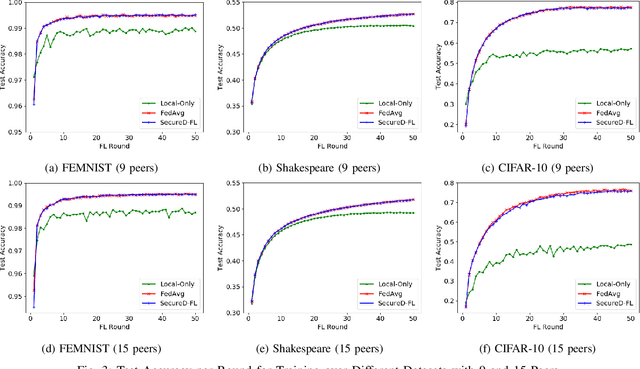
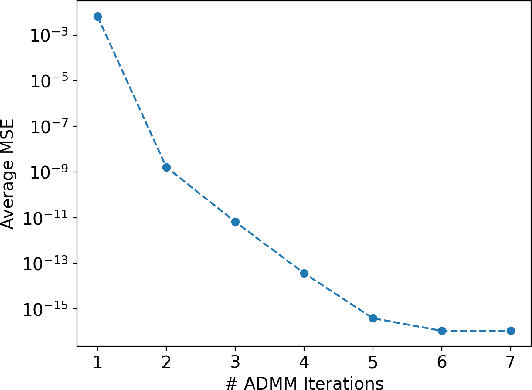
Federated learning is a promising framework for learning over decentralized data spanning multiple regions. This approach avoids expensive central training data aggregation cost and can improve privacy because distributed sites do not have to reveal privacy-sensitive data. In this paper, we develop a privacy-preserving decentralized aggregation protocol for federated learning. We formulate the distributed aggregation protocol with the Alternating Direction Method of Multiplier (ADMM) and examine its privacy weakness. Unlike prior work that use Differential Privacy or homomorphic encryption for privacy, we develop a protocol that controls communication among participants in each round of aggregation to minimize privacy leakage. We establish its privacy guarantee against an honest-but-curious adversary. We also propose an efficient algorithm to construct such a communication pattern, inspired by combinatorial block design theory. Our secure aggregation protocol based on this novel group communication pattern design leads to an efficient algorithm for federated training with privacy guarantees. We evaluate our federated training algorithm on image classification and next-word prediction applications over benchmark datasets with 9 and 15 distributed sites. Evaluation results show that our algorithm performs comparably to the standard centralized federated learning method while preserving privacy; the degradation in test accuracy is only up to 0.73%.