 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Video Retrieval by Adaptive Margin
Mar 09, 2023Video retrieval is becoming increasingly important owing to the rapid emergence of videos on the Internet. The dominant paradigm for video retrieval learns video-text representations by pushing the distance between the similarity of positive pairs and that of negative pairs apart from a fixed margin. However, negative pairs used for training are sampled randomly, which indicates that the semantics between negative pairs may be related or even equivalent, while most methods still enforce dissimilar representations to decrease their similarity. This phenomenon leads to inaccurate supervision and poor performance in learning video-text representations. While most video retrieval methods overlook that phenomenon, we propose an adaptive margin changed with the distance between positive and negative pairs to solve the aforementioned issue. First, we design the calculation framework of the adaptive margin, including the method of distance measurement and the function between the distance and the margin. Then, we explore a novel implementation called "Cross-Modal Generalized Self-Distillation" (CMGSD), which can be built on the top of most video retrieval models with few modifications. Notably, CMGSD adds few computational overheads at train time and adds no computational overhead at test time. Experimental results on three widely used datasets demonstrate that the proposed method can yield significantly better performance than the corresponding backbone model, and it outperforms state-of-the-art methods by a large margin.
StereoDistill: Pick the Cream from LiDAR for Distilling Stereo-based 3D Object Detection
Jan 07, 2023In this paper, we propose a cross-modal distillation method named StereoDistill to narrow the gap between the stereo and LiDAR-based approaches via distilling the stereo detectors from the superior LiDAR model at the response level, which is usually overlooked in 3D object detection distillation. The key designs of StereoDistill are: the X-component Guided Distillation~(XGD) for regression and the Cross-anchor Logit Distillation~(CLD) for classification. In XGD, instead of empirically adopting a threshold to select the high-quality teacher predictions as soft targets, we decompose the predicted 3D box into sub-components and retain the corresponding part for distillation if the teacher component pilot is consistent with ground truth to largely boost the number of positive predictions and alleviate the mimicking difficulty of the student model. For CLD, we aggregate the probability distribution of all anchors at the same position to encourage the highest probability anchor rather than individually distill the distribution at the anchor level. Finally, our StereoDistill achieves state-of-the-art results for stereo-based 3D detection on the KITTI test benchmark and extensive experiments on KITTI and Argoverse Dataset validate the effectiveness.
Repainting and Imitating Learning for Lane Detection
Oct 11, 2022

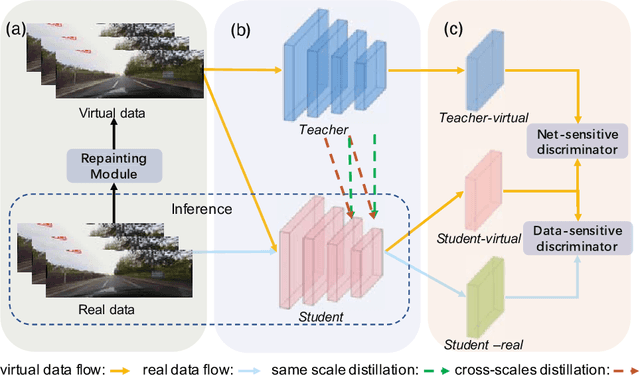
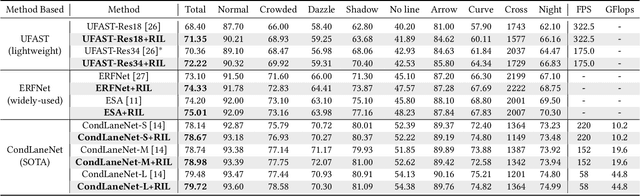
Current lane detection methods are struggling with the invisibility lane issue caused by heavy shadows, severe road mark degradation, and serious vehicle occlusion. As a result, discriminative lane features can be barely learned by the network despite elaborate designs due to the inherent invisibility of lanes in the wild. In this paper, we target at finding an enhanced feature space where the lane features are distinctive while maintaining a similar distribution of lanes in the wild. To achieve this, we propose a novel Repainting and Imitating Learning (RIL) framework containing a pair of teacher and student without any extra data or extra laborious labeling. Specifically, in the repainting step, an enhanced ideal virtual lane dataset is built in which only the lane regions are repainted while non-lane regions are kept unchanged, maintaining the similar distribution of lanes in the wild. The teacher model learns enhanced discriminative representation based on the virtual data and serves as the guidance for a student model to imitate. In the imitating learning step, through the scale-fusing distillation module, the student network is encouraged to generate features that mimic the teacher model both on the same scale and cross scales. Furthermore, the coupled adversarial module builds the bridge to connect not only teacher and student models but also virtual and real data, adjusting the imitating learning process dynamically. Note that our method introduces no extra time cost during inference and can be plug-and-play in various cutting-edge lane detection networks. Experimental results prove the effectiveness of the RIL framework both on CULane and TuSimple for four modern lane detection methods. The code and model will be available soon.
Detaching and Boosting: Dual Engine for Scale-Invariant Self-Supervised Monocular Depth Estimation
Oct 08, 2022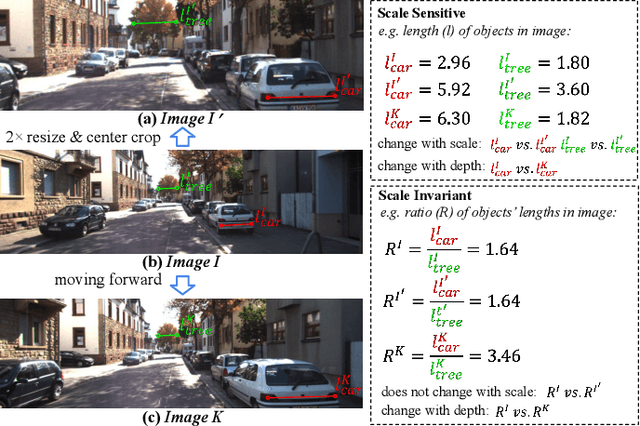
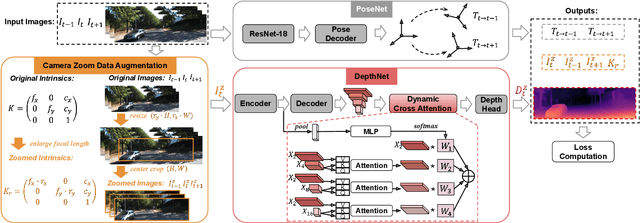
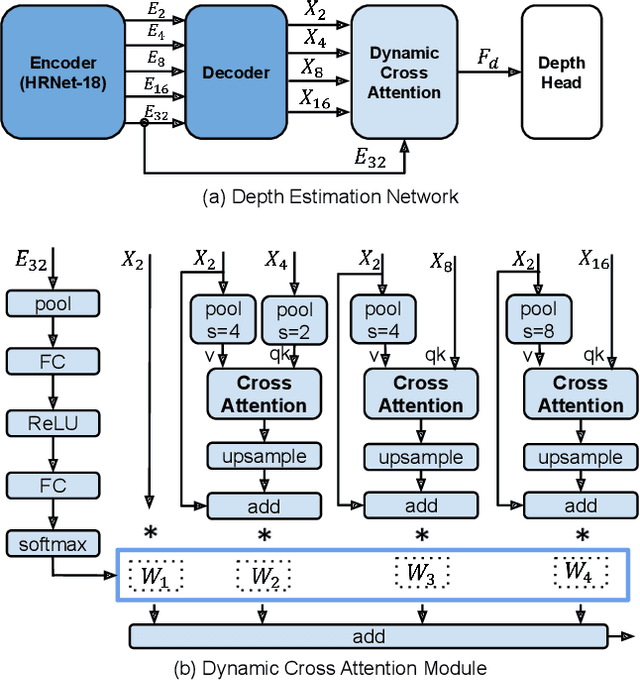
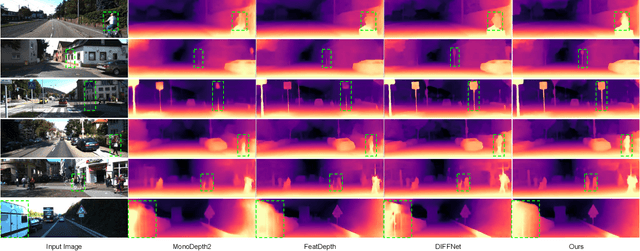
Monocular depth estimation (MDE) in the self-supervised scenario has emerged as a promising method as it refrains from the requirement of ground truth depth. Despite continuous efforts, MDE is still sensitive to scale changes especially when all the training samples are from one single camera. Meanwhile, it deteriorates further since camera movement results in heavy coupling between the predicted depth and the scale change. In this paper, we present a scale-invariant approach for self-supervised MDE, in which scale-sensitive features (SSFs) are detached away while scale-invariant features (SIFs) are boosted further. To be specific, a simple but effective data augmentation by imitating the camera zooming process is proposed to detach SSFs, making the model robust to scale changes. Besides, a dynamic cross-attention module is designed to boost SIFs by fusing multi-scale cross-attention features adaptively. Extensive experiments on the KITTI dataset demonstrate that the detaching and boosting strategies are mutually complementary in MDE and our approach achieves new State-of-The-Art performance against existing works from 0.097 to 0.090 w.r.t absolute relative error. The code will be made public soon.
SoccerNet 2022 Challenges Results
Oct 05, 2022
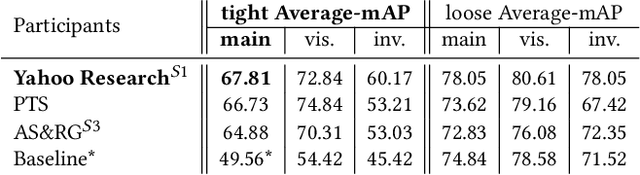
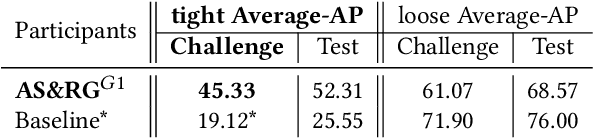
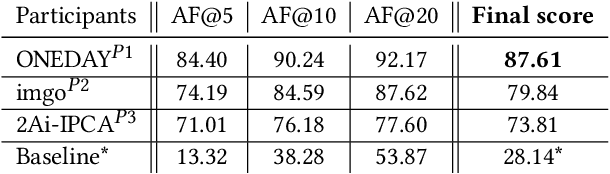
The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
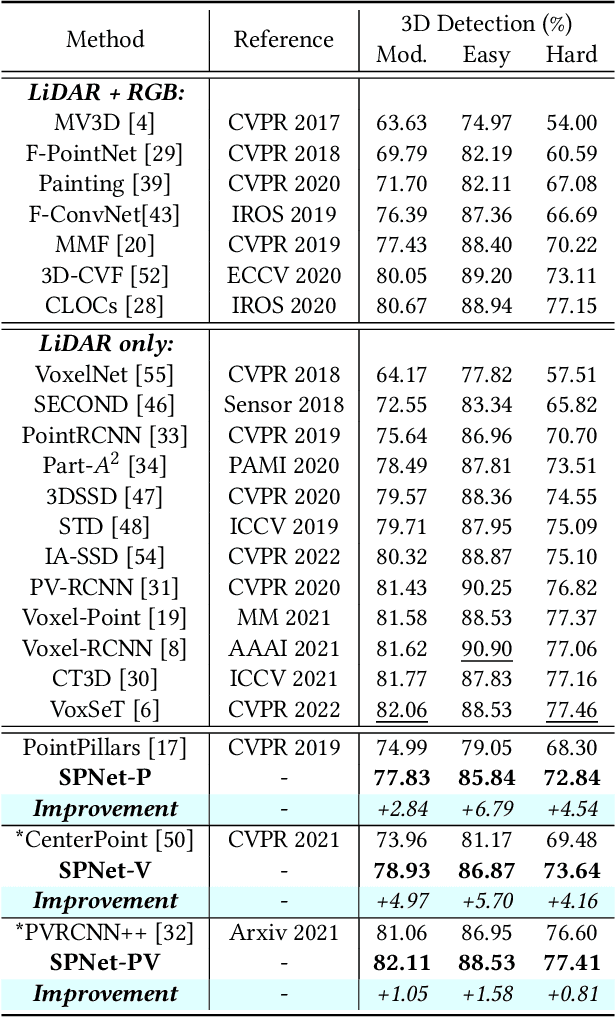
Spatial Pruned Sparse Convolution for Efficient 3D Object Detection
Sep 28, 2022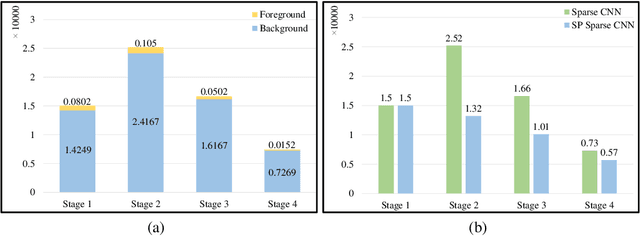
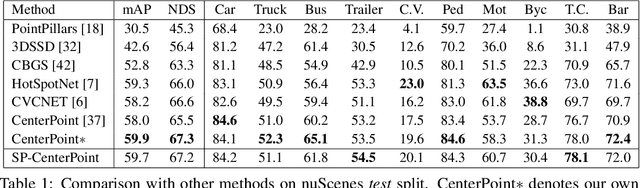
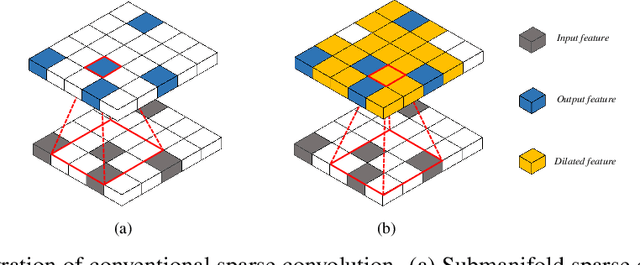

3D scenes are dominated by a large number of background points, which is redundant for the detection task that mainly needs to focus on foreground objects. In this paper, we analyze major components of existing sparse 3D CNNs and find that 3D CNNs ignore the redundancy of data and further amplify it in the down-sampling process, which brings a huge amount of extra and unnecessary computational overhead. Inspired by this, we propose a new convolution operator named spatial pruned sparse convolution (SPS-Conv), which includes two variants, spatial pruned submanifold sparse convolution (SPSS-Conv) and spatial pruned regular sparse convolution (SPRS-Conv), both of which are based on the idea of dynamically determining crucial areas for redundancy reduction. We validate that the magnitude can serve as important cues to determine crucial areas which get rid of the extra computations of learning-based methods. The proposed modules can easily be incorporated into existing sparse 3D CNNs without extra architectural modifications. Extensive experiments on the KITTI, Waymo and nuScenes datasets demonstrate that our method can achieve more than 50% reduction in GFLOPs without compromising the performance.
AGO-Net: Association-Guided 3D Point Cloud Object Detection Network
Aug 24, 2022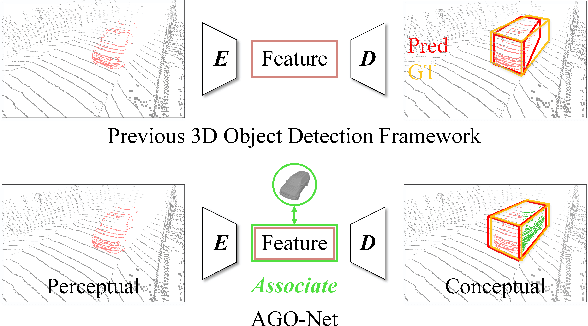
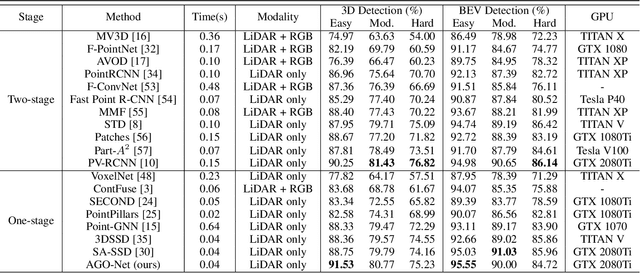
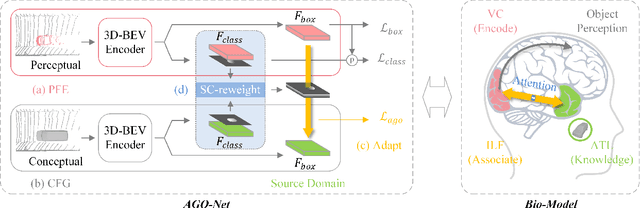
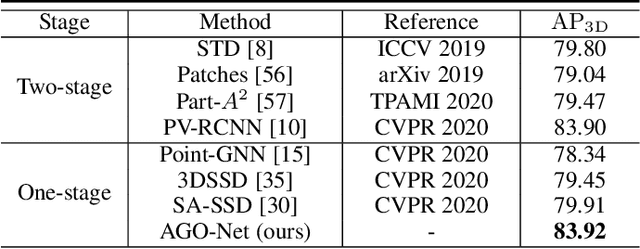
The human brain can effortlessly recognize and localize objects, whereas current 3D object detection methods based on LiDAR point clouds still report inferior performance for detecting occluded and distant objects: the point cloud appearance varies greatly due to occlusion, and has inherent variance in point densities along the distance to sensors. Therefore, designing feature representations robust to such point clouds is critical. Inspired by human associative recognition, we propose a novel 3D detection framework that associates intact features for objects via domain adaptation. We bridge the gap between the perceptual domain, where features are derived from real scenes with sub-optimal representations, and the conceptual domain, where features are extracted from augmented scenes that consist of non-occlusion objects with rich detailed information. A feasible method is investigated to construct conceptual scenes without external datasets. We further introduce an attention-based re-weighting module that adaptively strengthens the feature adaptation of more informative regions. The network's feature enhancement ability is exploited without introducing extra cost during inference, which is plug-and-play in various 3D detection frameworks. We achieve new state-of-the-art performance on the KITTI 3D detection benchmark in both accuracy and speed. Experiments on nuScenes and Waymo datasets also validate the versatility of our method.
Paint and Distill: Boosting 3D Object Detection with Semantic Passing Network
Jul 12, 2022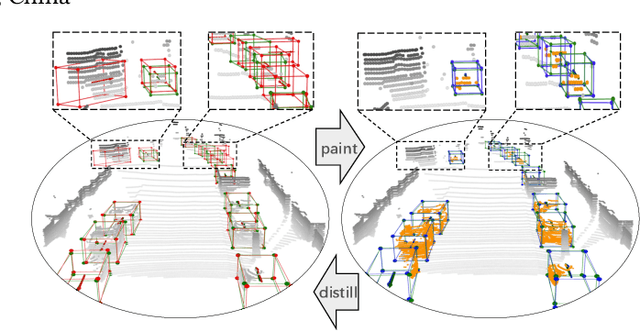
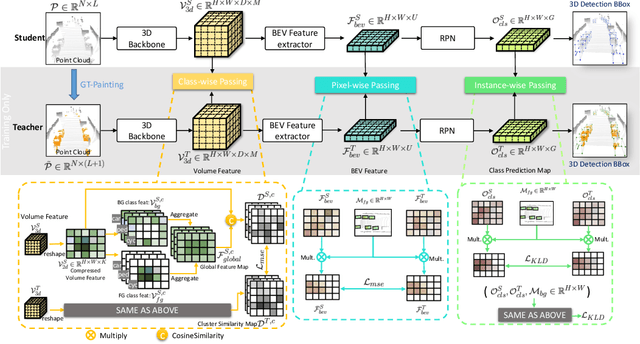
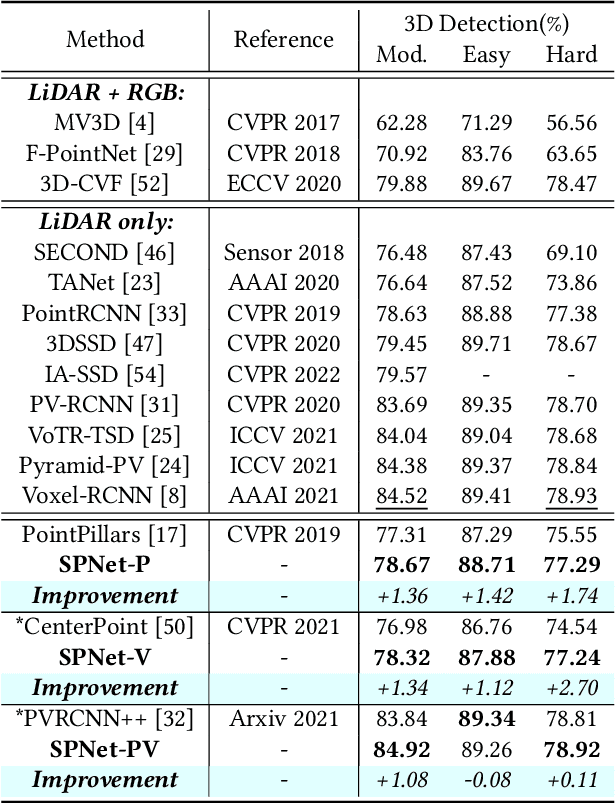
3D object detection task from lidar or camera sensors is essential for autonomous driving. Pioneer attempts at multi-modality fusion complement the sparse lidar point clouds with rich semantic texture information from images at the cost of extra network designs and overhead. In this work, we propose a novel semantic passing framework, named SPNet, to boost the performance of existing lidar-based 3D detection models with the guidance of rich context painting, with no extra computation cost during inference. Our key design is to first exploit the potential instructive semantic knowledge within the ground-truth labels by training a semantic-painted teacher model and then guide the pure-lidar network to learn the semantic-painted representation via knowledge passing modules at different granularities: class-wise passing, pixel-wise passing and instance-wise passing. Experimental results show that the proposed SPNet can seamlessly cooperate with most existing 3D detection frameworks with 1~5% AP gain and even achieve new state-of-the-art 3D detection performance on the KITTI test benchmark. Code is available at: https://github.com/jb892/SPNet.
Neural Deformable Voxel Grid for Fast Optimization of Dynamic View Synthesis
Jun 15, 2022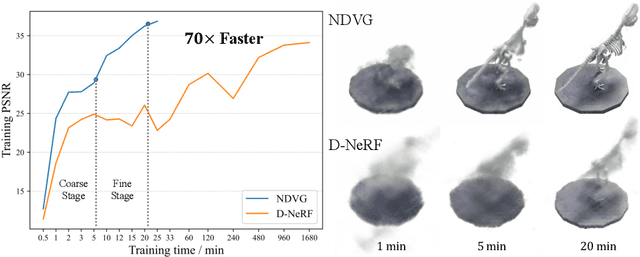
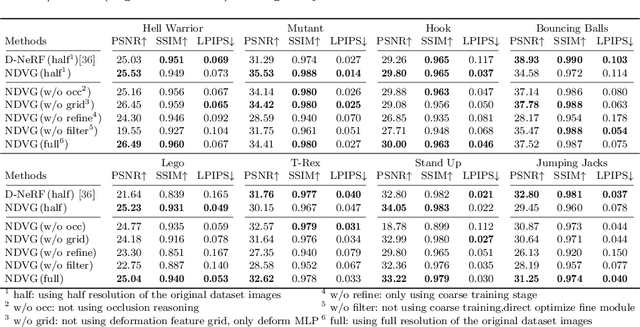
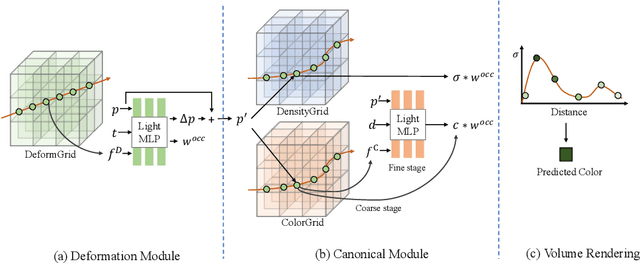

Recently, Neural Radiance Fields (NeRF) is revolutionizing the task of novel view synthesis (NVS) for its superior performance. However, NeRF and its variants generally require a lengthy per-scene training procedure, where a multi-layer perceptron (MLP) is fitted to the captured images. To remedy the challenge, the voxel-grid representation has been proposed to significantly speed up the training. However, these existing methods can only deal with static scenes. How to develop an efficient and accurate dynamic view synthesis method remains an open problem. Extending the methods for static scenes to dynamic scenes is not straightforward as both the scene geometry and appearance change over time. In this paper, built on top of the recent advances in voxel-grid optimization, we propose a fast deformable radiance field method to handle dynamic scenes. Our method consists of two modules. The first module adopts a deformation grid to store 3D dynamic features, and a light-weight MLP for decoding the deformation that maps a 3D point in observation space to the canonical space using the interpolated features. The second module contains a density and a color grid to model the geometry and density of the scene. The occlusion is explicitly modeled to further improve the rendering quality. Experimental results show that our method achieves comparable performance to D-NeRF using only 20 minutes for training, which is more than 70x faster than D-NeRF, clearly demonstrating the efficiency of our proposed method.
A Simple Structure For Building A Robust Model
Apr 25, 2022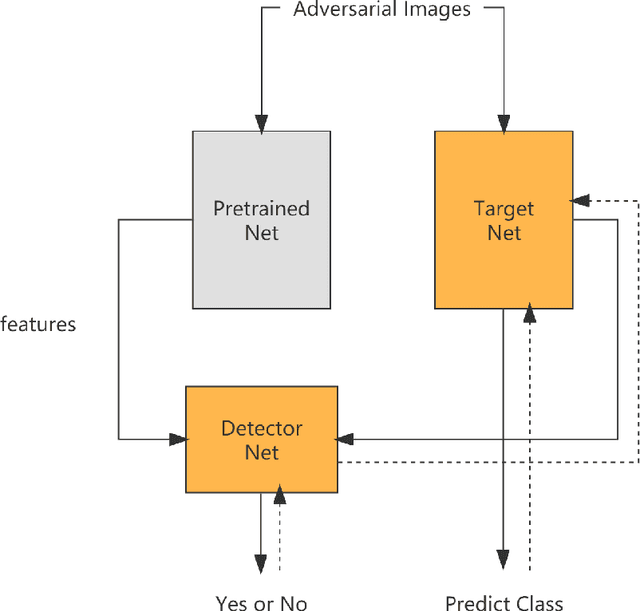


As deep learning applications, especially programs of computer vision, are increasingly deployed in our lives, we have to think more urgently about the security of these applications.One effective way to improve the security of deep learning models is to perform adversarial training, which allows the model to be compatible with samples that are deliberately created for use in attacking the model.Based on this, we propose a simple architecture to build a model with a certain degree of robustness, which improves the robustness of the trained network by adding an adversarial sample detection network for cooperative training.At the same time, we design a new data sampling strategy that incorporates multiple existing attacks, allowing the model to adapt to many different adversarial attacks with a single training.We conducted some experiments to test the effectiveness of this design based on Cifar10 dataset, and the results indicate that it has some degree of positive effect on the robustness of the model.Our code could be found at https://github.com/dowdyboy/simple_structure_for_robust_model.