 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-FLow: Contrastive Learning by semi-supervised Iterative Pseudo labeling for Optical Flow Estimation
Nov 01, 2022



Synthetic datasets are often used to pretrain end-to-end optical flow networks, due to the lack of a large amount of labeled, real-scene data. But major drops in accuracy occur when moving from synthetic to real scenes. How do we better transfer the knowledge learned from synthetic to real domains? To this end, we propose CLIP-FLow, a semi-supervised iterative pseudo-labeling framework to transfer the pretraining knowledge to the target real domain. We leverage large-scale, unlabeled real data to facilitate transfer learning with the supervision of iteratively updated pseudo-ground truth labels, bridging the domain gap between the synthetic and the real. In addition, we propose a contrastive flow loss on reference features and the warped features by pseudo ground truth flows, to further boost the accurate matching and dampen the mismatching due to motion, occlusion, or noisy pseudo labels. We adopt RAFT as the backbone and obtain an F1-all error of 4.11%, i.e. a 19% error reduction from RAFT (5.10%) and ranking 2$^{nd}$ place at submission on the KITTI 2015 benchmark. Our framework can also be extended to other models, e.g. CRAFT, reducing the F1-all error from 4.79% to 4.66% on KITTI 2015 benchmark.
GLEAN: Generative Latent Bank for Image Super-Resolution and Beyond
Jul 29, 2022
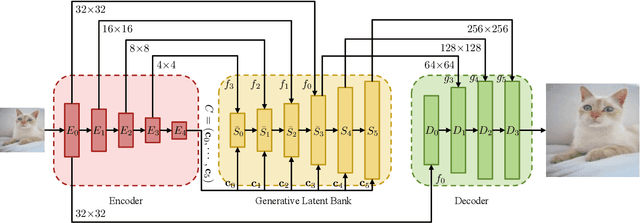
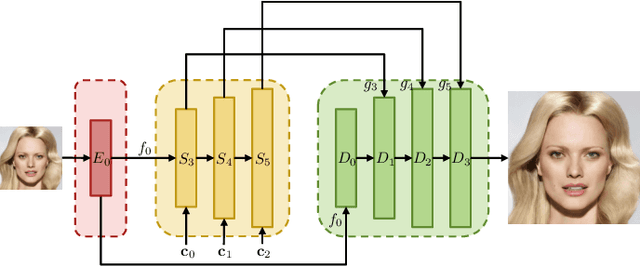
We show that pre-trained Generative Adversarial Networks (GANs) such as StyleGAN and BigGAN can be used as a latent bank to improve the performance of image super-resolution. While most existing perceptual-oriented approaches attempt to generate realistic outputs through learning with adversarial loss, our method, Generative LatEnt bANk (GLEAN), goes beyond existing practices by directly leveraging rich and diverse priors encapsulated in a pre-trained GAN. But unlike prevalent GAN inversion methods that require expensive image-specific optimization at runtime, our approach only needs a single forward pass for restoration. GLEAN can be easily incorporated in a simple encoder-bank-decoder architecture with multi-resolution skip connections. Employing priors from different generative models allows GLEAN to be applied to diverse categories (\eg~human faces, cats, buildings, and cars). We further present a lightweight version of GLEAN, named LightGLEAN, which retains only the critical components in GLEAN. Notably, LightGLEAN consists of only 21% of parameters and 35% of FLOPs while achieving comparable image quality. We extend our method to different tasks including image colorization and blind image restoration, and extensive experiments show that our proposed models perform favorably in comparison to existing methods. Codes and models are available at https://github.com/open-mmlab/mmediting.
Cylin-Painting: Seamless 360° Panoramic Image Outpainting and Beyond with Cylinder-Style Convolutions
Apr 18, 2022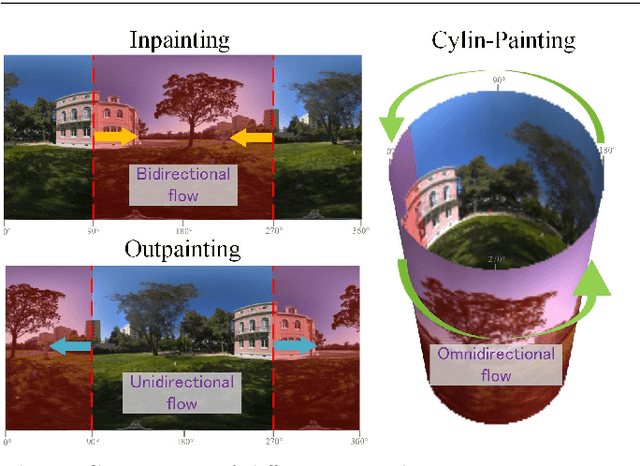
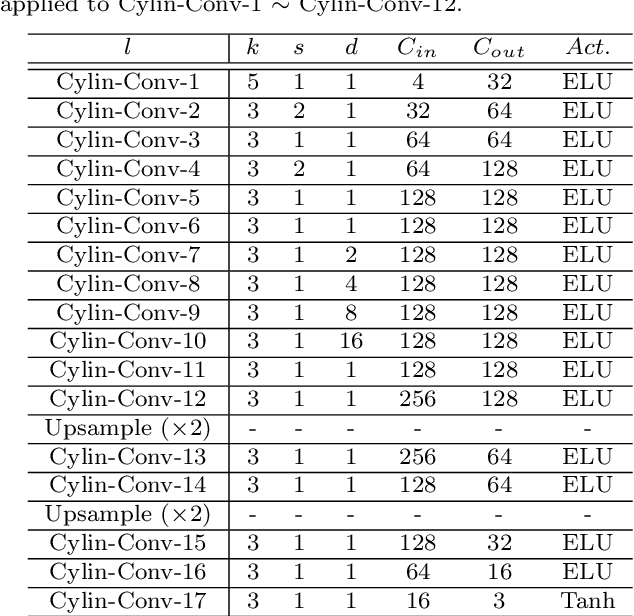
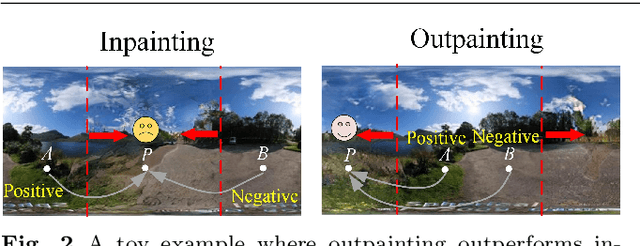
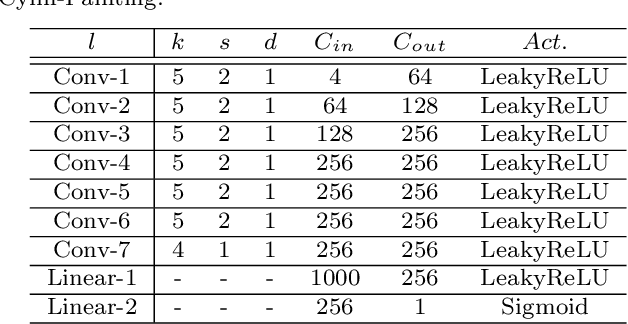
Image outpainting gains increasing attention since it can generate the complete scene from a partial view, providing a valuable solution to construct 360{\deg} panoramic images. As image outpainting suffers from the intrinsic issue of unidirectional completion flow, previous methods convert the original problem into inpainting, which allows a bidirectional flow. However, we find that inpainting has its own limitations and is inferior to outpainting in certain situations. The question of how they may be combined for the best of both has as yet remained under-explored. In this paper, we provide a deep analysis of the differences between inpainting and outpainting, which essentially depends on how the source pixels contribute to the unknown regions under different spatial arrangements. Motivated by this analysis, we present a Cylin-Painting framework that involves meaningful collaborations between inpainting and outpainting and efficiently fuses the different arrangements, with a view to leveraging their complementary benefits on a consistent and seamless cylinder. Nevertheless, directly applying the cylinder-style convolution often generates visually unpleasing results as it could discard important positional information. To address this issue, we further present a learnable positional embedding strategy and incorporate the missing component of positional encoding into the cylinder convolution, which significantly improves the panoramic results. Note that while developed for image outpainting, the proposed solution can be effectively extended to other panoramic vision tasks, such as object detection, depth estimation, and image super resolution.
On the Generalization of BasicVSR++ to Video Deblurring and Denoising
Apr 11, 2022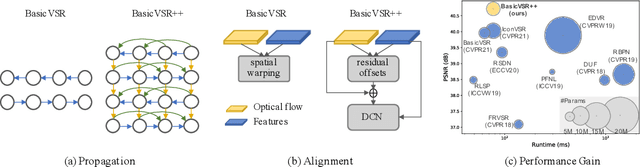
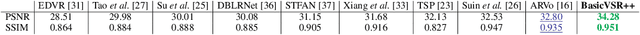


The exploitation of long-term information has been a long-standing problem in video restoration. The recent BasicVSR and BasicVSR++ have shown remarkable performance in video super-resolution through long-term propagation and effective alignment. Their success has led to a question of whether they can be transferred to different video restoration tasks. In this work, we extend BasicVSR++ to a generic framework for video restoration tasks. In tasks where inputs and outputs possess identical spatial size, the input resolution is reduced by strided convolutions to maintain efficiency. With only minimal changes from BasicVSR++, the proposed framework achieves compelling performance with great efficiency in various video restoration tasks including video deblurring and denoising. Notably, BasicVSR++ achieves comparable performance to Transformer-based approaches with up to 79% of parameter reduction and 44x speedup. The promising results demonstrate the importance of propagation and alignment in video restoration tasks beyond just video super-resolution. Code and models are available at https://github.com/ckkelvinchan/BasicVSR_PlusPlus.
Geometry-Guided Progressive NeRF for Generalizable and Efficient Neural Human Rendering
Dec 08, 2021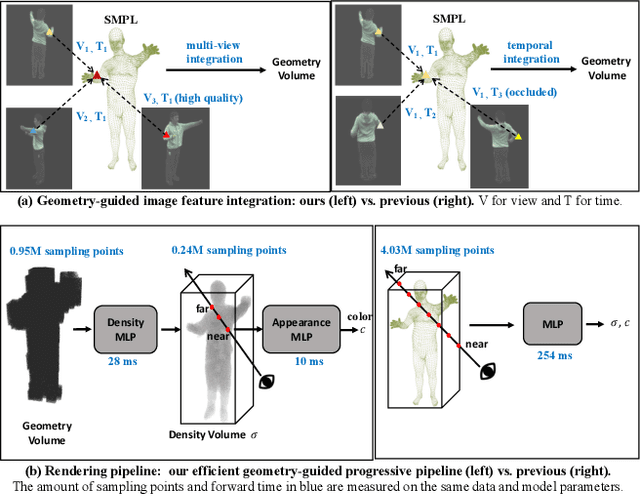
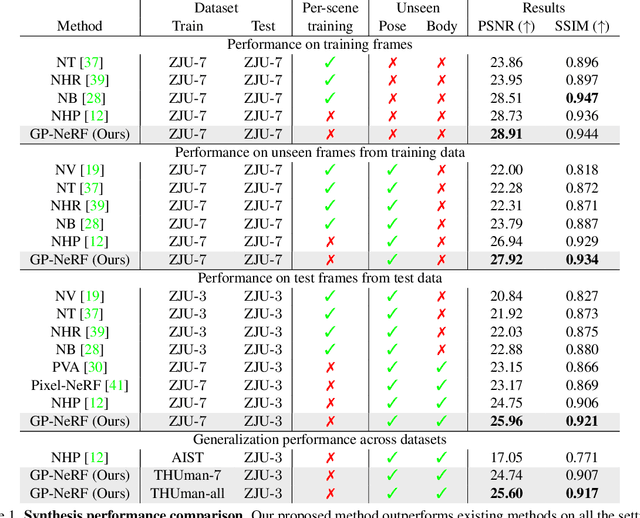
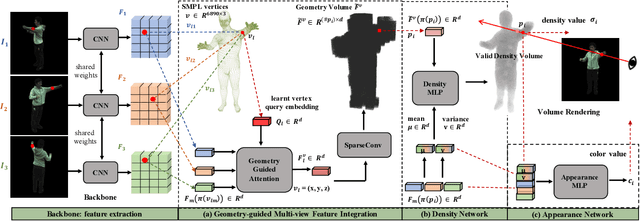
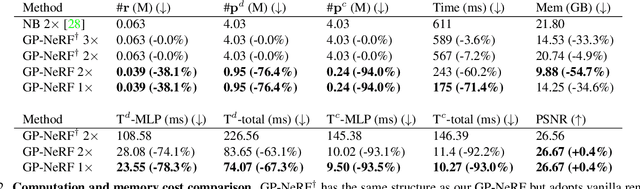
In this work we develop a generalizable and efficient Neural Radiance Field (NeRF) pipeline for high-fidelity free-viewpoint human body synthesis under settings with sparse camera views. Though existing NeRF-based methods can synthesize rather realistic details for human body, they tend to produce poor results when the input has self-occlusion, especially for unseen humans under sparse views. Moreover, these methods often require a large number of sampling points for rendering, which leads to low efficiency and limits their real-world applicability. To address these challenges, we propose a Geometry-guided Progressive NeRF~(GP-NeRF). In particular, to better tackle self-occlusion, we devise a geometry-guided multi-view feature integration approach that utilizes the estimated geometry prior to integrate the incomplete information from input views and construct a complete geometry volume for the target human body. Meanwhile, for achieving higher rendering efficiency, we introduce a geometry-guided progressive rendering pipeline, which leverages the geometric feature volume and the predicted density values to progressively reduce the number of sampling points and speed up the rendering process. Experiments on the ZJU-MoCap and THUman datasets show that our method outperforms the state-of-the-arts significantly across multiple generalization settings, while the time cost is reduced >70% via applying our efficient progressive rendering pipeline.
Video Frame Interpolation Transformer
Nov 27, 2021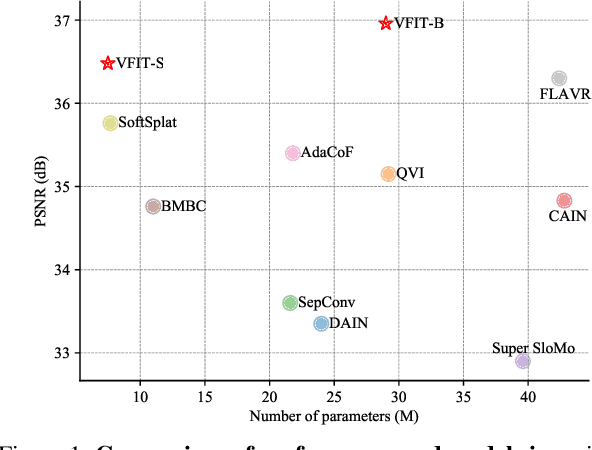
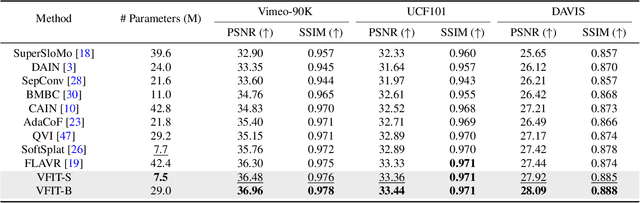
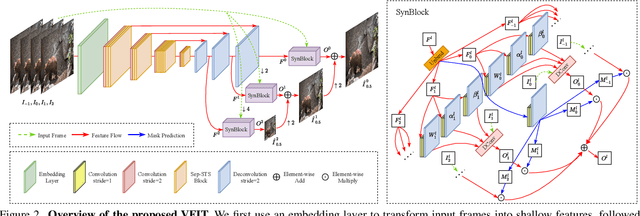
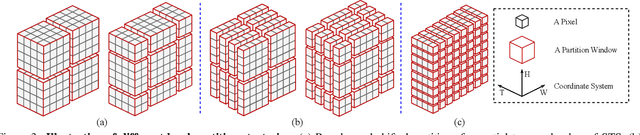
Existing methods for video interpolation heavily rely on deep convolution neural networks, and thus suffer from their intrinsic limitations, such as content-agnostic kernel weights and restricted receptive field. To address these issues, we propose a Transformer-based video interpolation framework that allows content-aware aggregation weights and considers long-range dependencies with the self-attention operations. To avoid the high computational cost of global self-attention, we introduce the concept of local attention into video interpolation and extend it to the spatial-temporal domain. Furthermore, we propose a space-time separation strategy to save memory usage, which also improves performance. In addition, we develop a multi-scale frame synthesis scheme to fully realize the potential of Transformers. Extensive experiments demonstrate the proposed model performs favorably against the state-of-the-art methods both quantitatively and qualitatively on a variety of benchmark datasets.
Investigating Tradeoffs in Real-World Video Super-Resolution
Nov 24, 2021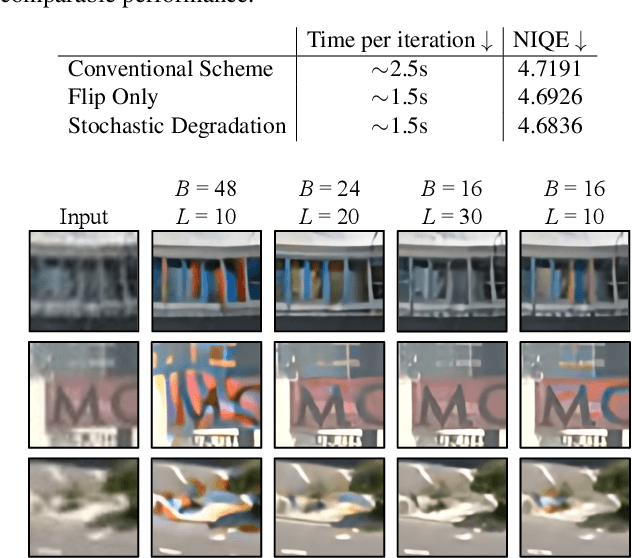


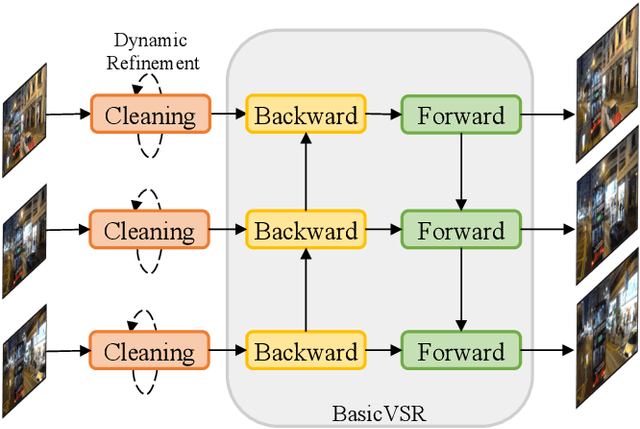
The diversity and complexity of degradations in real-world video super-resolution (VSR) pose non-trivial challenges in inference and training. First, while long-term propagation leads to improved performance in cases of mild degradations, severe in-the-wild degradations could be exaggerated through propagation, impairing output quality. To balance the tradeoff between detail synthesis and artifact suppression, we found an image pre-cleaning stage indispensable to reduce noises and artifacts prior to propagation. Equipped with a carefully designed cleaning module, our RealBasicVSR outperforms existing methods in both quality and efficiency. Second, real-world VSR models are often trained with diverse degradations to improve generalizability, requiring increased batch size to produce a stable gradient. Inevitably, the increased computational burden results in various problems, including 1) speed-performance tradeoff and 2) batch-length tradeoff. To alleviate the first tradeoff, we propose a stochastic degradation scheme that reduces up to 40\% of training time without sacrificing performance. We then analyze different training settings and suggest that employing longer sequences rather than larger batches during training allows more effective uses of temporal information, leading to more stable performance during inference. To facilitate fair comparisons, we propose the new VideoLQ dataset, which contains a large variety of real-world low-quality video sequences containing rich textures and patterns. Our dataset can serve as a common ground for benchmarking. Code, models, and the dataset will be made publicly available.
STransGAN: An Empirical Study on Transformer in GANs
Oct 25, 2021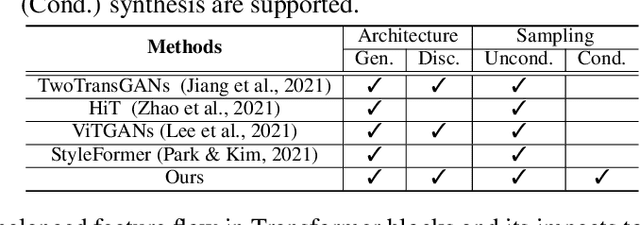
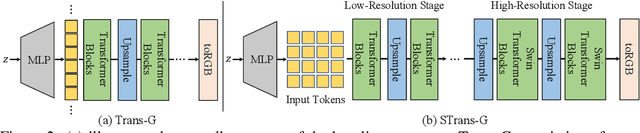
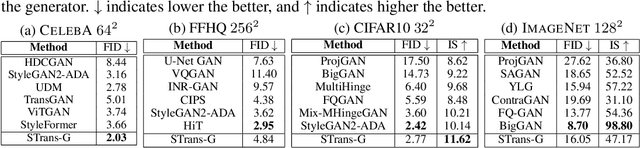

Transformer becomes prevalent in computer vision, especially for high-level vision tasks. However, deploying Transformer in the generative adversarial network (GAN) framework is still an open yet challenging problem. In this paper, we conduct a comprehensive empirical study to investigate the intrinsic properties of Transformer in GAN for high-fidelity image synthesis. Our analysis highlights the importance of feature locality in image generation. We first investigate the effective ways to implement local attention. We then examine the influence of residual connections in self-attention layers and propose a novel way to reduce their negative impacts on learning discriminators and conditional generators. Our study leads to a new design of Transformers in GAN, a convolutional neural network (CNN)-free generator termed as STrans-G, which achieves competitive results in both unconditional and conditional image generations. The Transformer-based discriminator, STrans-D, also significantly reduces its gap against the CNN-based discriminators.
GTT-Net: Learned Generalized Trajectory Triangulation
Sep 08, 2021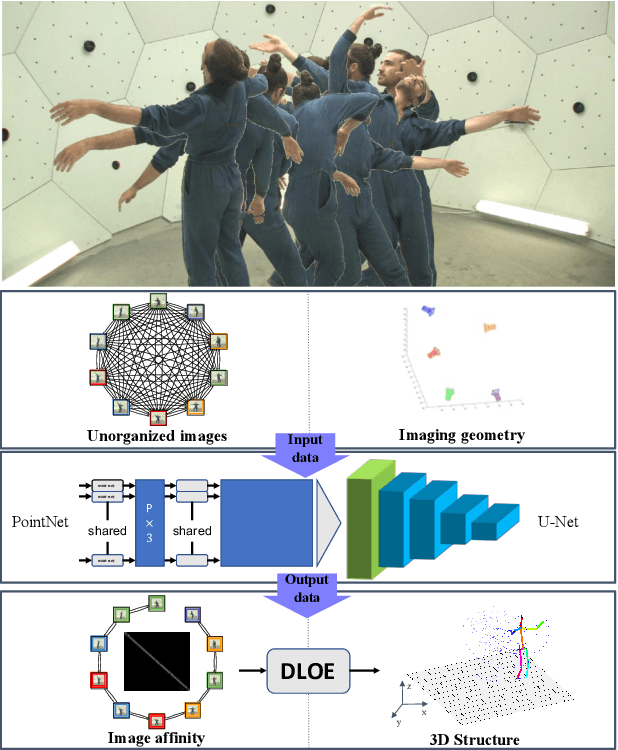
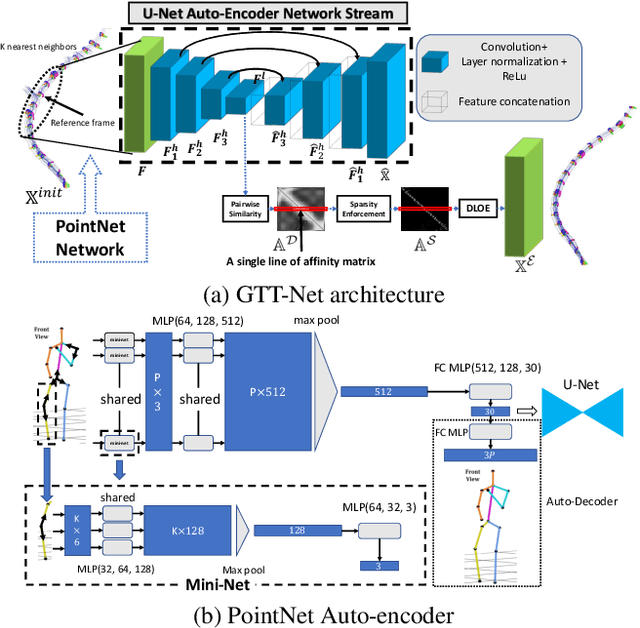
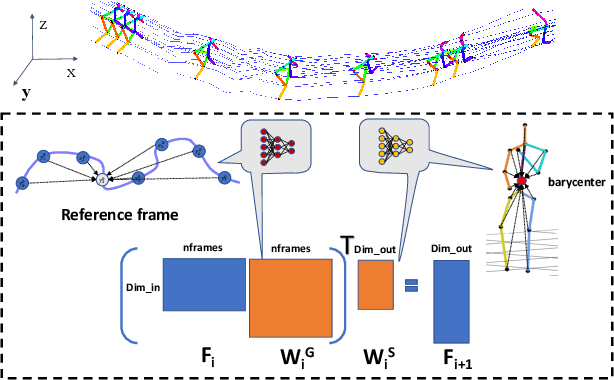
We present GTT-Net, a supervised learning framework for the reconstruction of sparse dynamic 3D geometry. We build on a graph-theoretic formulation of the generalized trajectory triangulation problem, where non-concurrent multi-view imaging geometry is known but global image sequencing is not provided. GTT-Net learns pairwise affinities modeling the spatio-temporal relationships among our input observations and leverages them to determine 3D geometry estimates. Experiments reconstructing 3D motion-capture sequences show GTT-Net outperforms the state of the art in terms of accuracy and robustness. Within the context of articulated motion reconstruction, our proposed architecture is 1) able to learn and enforce semantic 3D motion priors for shared training and test domains, while being 2) able to generalize its performance across different training and test domains. Moreover, GTT-Net provides a computationally streamlined framework for trajectory triangulation with applications to multi-instance reconstruction and event segmentation.
3D Human Texture Estimation from a Single Image with Transformers
Sep 06, 2021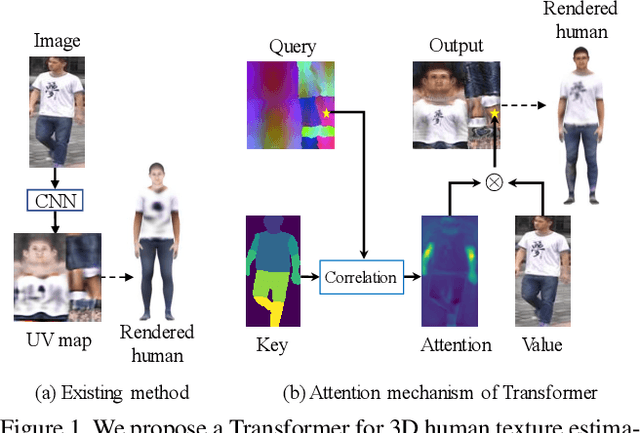
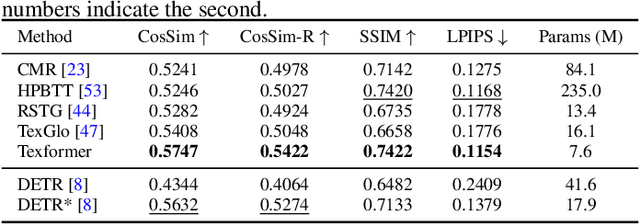
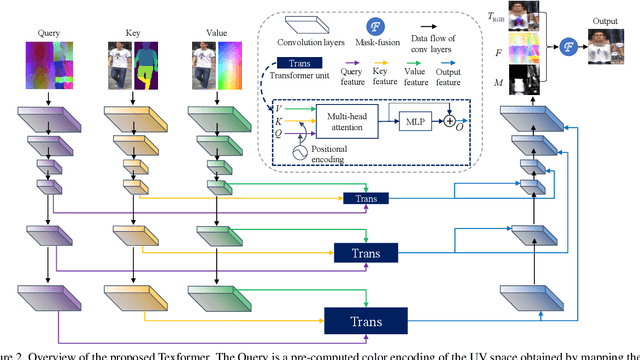
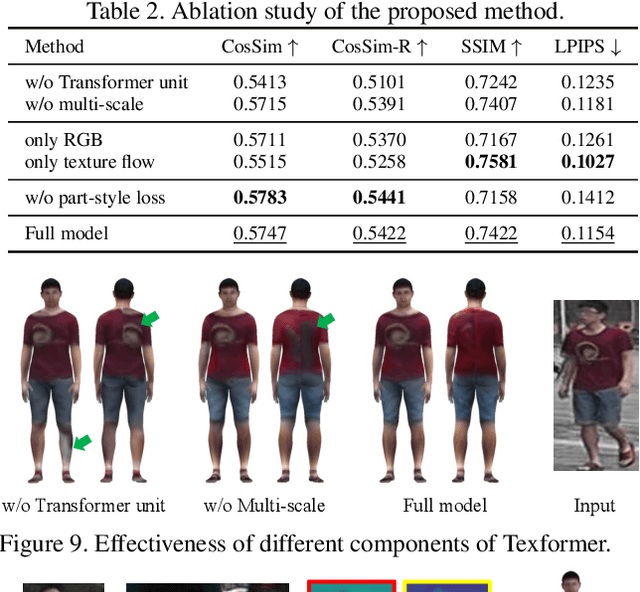
We propose a Transformer-based framework for 3D human texture estimation from a single image. The proposed Transformer is able to effectively exploit the global information of the input image, overcoming the limitations of existing methods that are solely based on convolutional neural networks. In addition, we also propose a mask-fusion strategy to combine the advantages of the RGB-based and texture-flow-based models. We further introduce a part-style loss to help reconstruct high-fidelity colors without introducing unpleasant artifacts. Extensive experiments demonstrate the effectiveness of the proposed method against state-of-the-art 3D human texture estimation approaches both quantitatively and qualitatively.
* ICCV 2021 Oral, Project: https://www.mmlab-ntu.com/project/texformer, Code: https://github.com/xuxy09/Texformer