 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantile Advantage Estimation for Entropy-Safe Reasoning
Sep 26, 2025Reinforcement Learning with Verifiable Rewards (RLVR) strengthens LLM reasoning, but training often oscillates between {entropy collapse} and {entropy explosion}. We trace both hazards to the mean baseline used in value-free RL (e.g., GRPO and DAPO), which improperly penalizes negative-advantage samples under reward outliers. We propose {Quantile Advantage Estimation} (QAE), replacing the mean with a group-wise K-quantile baseline. QAE induces a response-level, two-regime gate: on hard queries (p <= 1 - K) it reinforces rare successes, while on easy queries (p > 1 - K) it targets remaining failures. Under first-order softmax updates, we prove {two-sided entropy safety}, giving lower and upper bounds on one-step entropy change that curb explosion and prevent collapse. Empirically, this minimal modification stabilizes entropy, sparsifies credit assignment (with tuned K, roughly 80% of responses receive zero advantage), and yields sustained pass@1 gains on Qwen3-8B/14B-Base across AIME 2024/2025 and AMC 2023. These results identify {baseline design} -- rather than token-level heuristics -- as the primary mechanism for scaling RLVR.
AppAgent-Pro: A Proactive GUI Agent System for Multidomain Information Integration and User Assistance
Aug 27, 2025
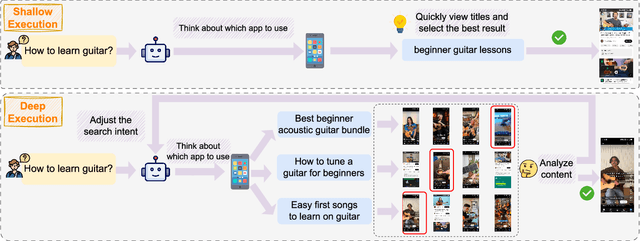


Large language model (LLM)-based agents have demonstrated remarkable capabilities in addressing complex tasks, thereby enabling more advanced information retrieval and supporting deeper, more sophisticated human information-seeking behaviors. However, most existing agents operate in a purely reactive manner, responding passively to user instructions, which significantly constrains their effectiveness and efficiency as general-purpose platforms for information acquisition. To overcome this limitation, this paper proposes AppAgent-Pro, a proactive GUI agent system that actively integrates multi-domain information based on user instructions. This approach enables the system to proactively anticipate users' underlying needs and conduct in-depth multi-domain information mining, thereby facilitating the acquisition of more comprehensive and intelligent information. AppAgent-Pro has the potential to fundamentally redefine information acquisition in daily life, leading to a profound impact on human society. Our code is available at: https://github.com/LaoKuiZe/AppAgent-Pro. The demonstration video could be found at: https://www.dropbox.com/scl/fi/hvzqo5vnusg66srydzixo/AppAgent-Pro-demo-video.mp4?rlkey=o2nlfqgq6ihl125mcqg7bpgqu&st=d29vrzii&dl=0.
Teaching LLM to Reason: Reinforcement Learning from Algorithmic Problems without Code
Jul 10, 2025
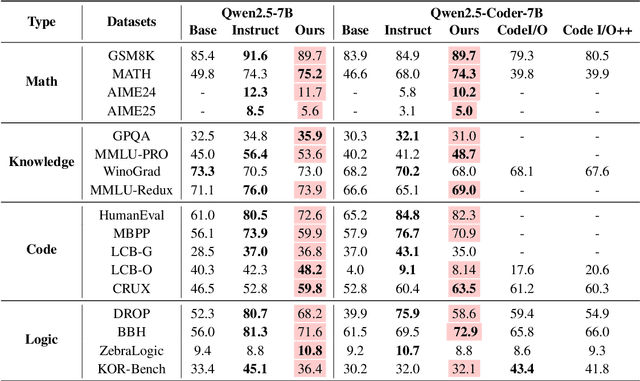

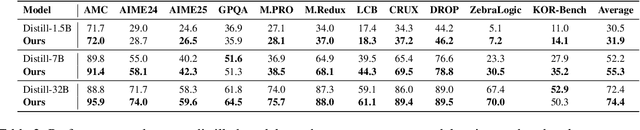
Enhancing reasoning capabilities remains a central focus in the LLM reasearch community. A promising direction involves requiring models to simulate code execution step-by-step to derive outputs for given inputs. However, as code is often designed for large-scale systems, direct application leads to over-reliance on complex data structures and algorithms, even for simple cases, resulting in overfitting to algorithmic patterns rather than core reasoning structures. To address this, we propose TeaR, which aims at teaching LLMs to reason better. TeaR leverages careful data curation and reinforcement learning to guide models in discovering optimal reasoning paths through code-related tasks, thereby improving general reasoning abilities. We conduct extensive experiments using two base models and three long-CoT distillation models, with model sizes ranging from 1.5 billion to 32 billion parameters, and across 17 benchmarks spanning Math, Knowledge, Code, and Logical Reasoning. The results consistently show significant performance improvements. Notably, TeaR achieves a 35.9% improvement on Qwen2.5-7B and 5.9% on R1-Distilled-7B.
Boosting Parameter Efficiency in LLM-Based Recommendation through Sophisticated Pruning
Jul 09, 2025LLM-based recommender systems have made significant progress; however, the deployment cost associated with the large parameter volume of LLMs still hinders their real-world applications. This work explores parameter pruning to improve parameter efficiency while maintaining recommendation quality, thereby enabling easier deployment. Unlike existing approaches that focus primarily on inter-layer redundancy, we uncover intra-layer redundancy within components such as self-attention and MLP modules. Building on this analysis, we propose a more fine-grained pruning approach that integrates both intra-layer and layer-wise pruning. Specifically, we introduce a three-stage pruning strategy that progressively prunes parameters at different levels and parts of the model, moving from intra-layer to layer-wise pruning, or from width to depth. Each stage also includes a performance restoration step using distillation techniques, helping to strike a balance between performance and parameter efficiency. Empirical results demonstrate the effectiveness of our approach: across three datasets, our models achieve an average of 88% of the original model's performance while pruning more than 95% of the non-embedding parameters. This underscores the potential of our method to significantly reduce resource requirements without greatly compromising recommendation quality. Our code will be available at: https://github.com/zheng-sl/PruneRec
Mitigating Safety Fallback in Editing-based Backdoor Injection on LLMs
Jun 16, 2025



Large language models (LLMs) have shown strong performance across natural language tasks, but remain vulnerable to backdoor attacks. Recent model editing-based approaches enable efficient backdoor injection by directly modifying parameters to map specific triggers to attacker-desired responses. However, these methods often suffer from safety fallback, where the model initially responds affirmatively but later reverts to refusals due to safety alignment. In this work, we propose DualEdit, a dual-objective model editing framework that jointly promotes affirmative outputs and suppresses refusal responses. To address two key challenges -- balancing the trade-off between affirmative promotion and refusal suppression, and handling the diversity of refusal expressions -- DualEdit introduces two complementary techniques. (1) Dynamic loss weighting calibrates the objective scale based on the pre-edited model to stabilize optimization. (2) Refusal value anchoring compresses the suppression target space by clustering representative refusal value vectors, reducing optimization conflict from overly diverse token sets. Experiments on safety-aligned LLMs show that DualEdit improves attack success by 9.98\% and reduces safety fallback rate by 10.88\% over baselines.
Reinforced Latent Reasoning for LLM-based Recommendation
May 25, 2025Large Language Models (LLMs) have demonstrated impressive reasoning capabilities in complex problem-solving tasks, sparking growing interest in their application to preference reasoning in recommendation systems. Existing methods typically rely on fine-tuning with explicit chain-of-thought (CoT) data. However, these methods face significant practical limitations due to (1) the difficulty of obtaining high-quality CoT data in recommendation and (2) the high inference latency caused by generating CoT reasoning. In this work, we explore an alternative approach that shifts from explicit CoT reasoning to compact, information-dense latent reasoning. This approach eliminates the need for explicit CoT generation and improves inference efficiency, as a small set of latent tokens can effectively capture the entire reasoning process. Building on this idea, we propose $\textit{\underline{R}einforced \underline{Latent} \underline{R}easoning for \underline{R}ecommendation}$ (LatentR$^3$), a novel end-to-end training framework that leverages reinforcement learning (RL) to optimize latent reasoning without relying on any CoT data.LatentR$^3$ adopts a two-stage training strategy: first, supervised fine-tuning to initialize the latent reasoning module, followed by pure RL training to encourage exploration through a rule-based reward design. Our RL implementation is based on a modified GRPO algorithm, which reduces computational overhead during training and introduces continuous reward signals for more efficient learning. Extensive experiments demonstrate that LatentR$^3$ enables effective latent reasoning without any direct supervision of the reasoning process, significantly improving performance when integrated with different LLM-based recommendation methods. Our codes are available at https://anonymous.4open.science/r/R3-A278/.
Addressing Missing Data Issue for Diffusion-based Recommendation
May 18, 2025Diffusion models have shown significant potential in generating oracle items that best match user preference with guidance from user historical interaction sequences. However, the quality of guidance is often compromised by unpredictable missing data in observed sequence, leading to suboptimal item generation. Since missing data is uncertain in both occurrence and content, recovering it is impractical and may introduce additional errors. To tackle this challenge, we propose a novel dual-side Thompson sampling-based Diffusion Model (TDM), which simulates extra missing data in the guidance signals and allows diffusion models to handle existing missing data through extrapolation. To preserve user preference evolution in sequences despite extra missing data, we introduce Dual-side Thompson Sampling to implement simulation with two probability models, sampling by exploiting user preference from both item continuity and sequence stability. TDM strategically removes items from sequences based on dual-side Thompson sampling and treats these edited sequences as guidance for diffusion models, enhancing models' robustness to missing data through consistency regularization. Additionally, to enhance the generation efficiency, TDM is implemented under the denoising diffusion implicit models to accelerate the reverse process. Extensive experiments and theoretical analysis validate the effectiveness of TDM in addressing missing data in sequential recommendations.
AdaViP: Aligning Multi-modal LLMs via Adaptive Vision-enhanced Preference Optimization
Apr 22, 2025Preference alignment through Direct Preference Optimization (DPO) has demonstrated significant effectiveness in aligning multimodal large language models (MLLMs) with human preferences. However, existing methods focus primarily on language preferences while neglecting the critical visual context. In this paper, we propose an Adaptive Vision-enhanced Preference optimization (AdaViP) that addresses these limitations through two key innovations: (1) vision-based preference pair construction, which integrates multiple visual foundation models to strategically remove key visual elements from the image, enhancing MLLMs' sensitivity to visual details; and (2) adaptive preference optimization that dynamically balances vision- and language-based preferences for more accurate alignment. Extensive evaluations across different benchmarks demonstrate our effectiveness. Notably, our AdaViP-7B achieves 93.7% and 96.4% reductions in response-level and mentioned-level hallucination respectively on the Object HalBench, significantly outperforming current state-of-the-art methods.
Route Sparse Autoencoder to Interpret Large Language Models
Mar 11, 2025Mechanistic interpretability of large language models (LLMs) aims to uncover the internal processes of information propagation and reasoning. Sparse autoencoders (SAEs) have demonstrated promise in this domain by extracting interpretable and monosemantic features. However, prior works primarily focus on feature extraction from a single layer, failing to effectively capture activations that span multiple layers. In this paper, we introduce Route Sparse Autoencoder (RouteSAE), a new framework that integrates a routing mechanism with a shared SAE to efficiently extract features from multiple layers. It dynamically assigns weights to activations from different layers, incurring minimal parameter overhead while achieving high interpretability and flexibility for targeted feature manipulation. We evaluate RouteSAE through extensive experiments on Llama-3.2-1B-Instruct. Specifically, under the same sparsity constraint of 64, RouteSAE extracts 22.5% more features than baseline SAEs while achieving a 22.3% higher interpretability score. These results underscore the potential of RouteSAE as a scalable and effective method for LLM interpretability, with applications in feature discovery and model intervention. Our codes are available at https://github.com/swei2001/RouteSAEs.
RePO: ReLU-based Preference Optimization
Mar 10, 2025Aligning large language models (LLMs) with human preferences is critical for real-world deployment, yet existing methods like RLHF face computational and stability challenges. While DPO establishes an offline paradigm with single hyperparameter $\beta$, subsequent methods like SimPO reintroduce complexity through dual parameters ($\beta$, $\gamma$). We propose {ReLU-based Preference Optimization (RePO)}, a streamlined algorithm that eliminates $\beta$ via two advances: (1) retaining SimPO's reference-free margins but removing $\beta$ through gradient analysis, and (2) adopting a ReLU-based max-margin loss that naturally filters trivial pairs. Theoretically, RePO is characterized as SimPO's limiting case ($\beta \to \infty$), where the logistic weighting collapses to binary thresholding, forming a convex envelope of the 0-1 loss. Empirical results on AlpacaEval 2 and Arena-Hard show that RePO outperforms DPO and SimPO across multiple base models, requiring only one hyperparameter to tune.