 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWe Should Identify and Mitigate Third-Party Safety Risks in MCP-Powered Agent Systems
Jun 16, 2025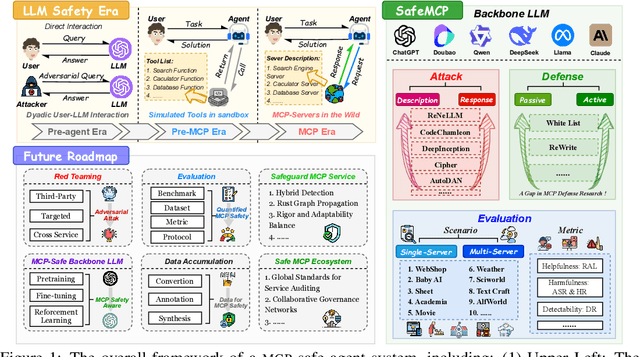
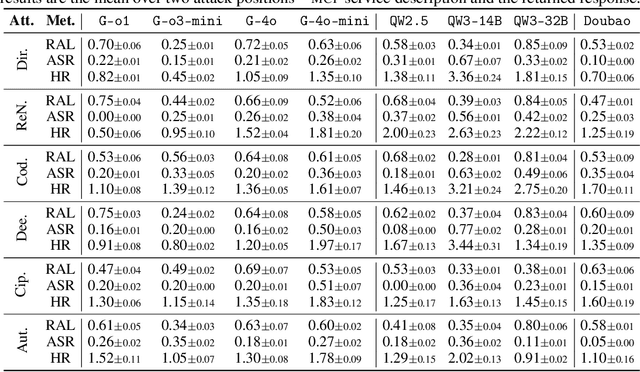
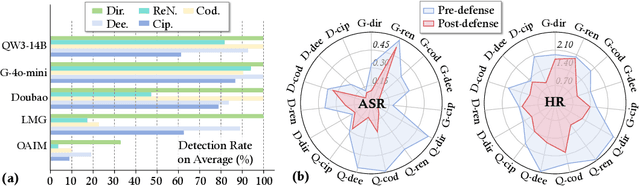
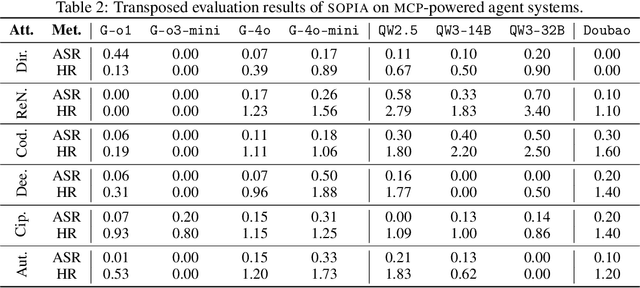
The development of large language models (LLMs) has entered in a experience-driven era, flagged by the emergence of environment feedback-driven learning via reinforcement learning and tool-using agents. This encourages the emergenece of model context protocol (MCP), which defines the standard on how should a LLM interact with external services, such as \api and data. However, as MCP becomes the de facto standard for LLM agent systems, it also introduces new safety risks. In particular, MCP introduces third-party services, which are not controlled by the LLM developers, into the agent systems. These third-party MCP services provider are potentially malicious and have the economic incentives to exploit vulnerabilities and sabotage user-agent interactions. In this position paper, we advocate the research community in LLM safety to pay close attention to the new safety risks issues introduced by MCP, and develop new techniques to build safe MCP-powered agent systems. To establish our position, we argue with three key parts. (1) We first construct \framework, a controlled framework to examine safety issues in MCP-powered agent systems. (2) We then conduct a series of pilot experiments to demonstrate the safety risks in MCP-powered agent systems is a real threat and its defense is not trivial. (3) Finally, we give our outlook by showing a roadmap to build safe MCP-powered agent systems. In particular, we would call for researchers to persue the following research directions: red teaming, MCP safe LLM development, MCP safety evaluation, MCP safety data accumulation, MCP service safeguard, and MCP safe ecosystem construction. We hope this position paper can raise the awareness of the research community in MCP safety and encourage more researchers to join this important research direction. Our code is available at https://github.com/littlelittlenine/SafeMCP.git.
Mitigating Safety Fallback in Editing-based Backdoor Injection on LLMs
Jun 16, 2025



Large language models (LLMs) have shown strong performance across natural language tasks, but remain vulnerable to backdoor attacks. Recent model editing-based approaches enable efficient backdoor injection by directly modifying parameters to map specific triggers to attacker-desired responses. However, these methods often suffer from safety fallback, where the model initially responds affirmatively but later reverts to refusals due to safety alignment. In this work, we propose DualEdit, a dual-objective model editing framework that jointly promotes affirmative outputs and suppresses refusal responses. To address two key challenges -- balancing the trade-off between affirmative promotion and refusal suppression, and handling the diversity of refusal expressions -- DualEdit introduces two complementary techniques. (1) Dynamic loss weighting calibrates the objective scale based on the pre-edited model to stabilize optimization. (2) Refusal value anchoring compresses the suppression target space by clustering representative refusal value vectors, reducing optimization conflict from overly diverse token sets. Experiments on safety-aligned LLMs show that DualEdit improves attack success by 9.98\% and reduces safety fallback rate by 10.88\% over baselines.
CoRT: Code-integrated Reasoning within Thinking
Jun 12, 2025Large Reasoning Models (LRMs) like o1 and DeepSeek-R1 have shown remarkable progress in natural language reasoning with long chain-of-thought (CoT), yet they remain inefficient or inaccurate when handling complex mathematical operations. Addressing these limitations through computational tools (e.g., computation libraries and symbolic solvers) is promising, but it introduces a technical challenge: Code Interpreter (CI) brings external knowledge beyond the model's internal text representations, thus the direct combination is not efficient. This paper introduces CoRT, a post-training framework for teaching LRMs to leverage CI effectively and efficiently. As a first step, we address the data scarcity issue by synthesizing code-integrated reasoning data through Hint-Engineering, which strategically inserts different hints at appropriate positions to optimize LRM-CI interaction. We manually create 30 high-quality samples, upon which we post-train models ranging from 1.5B to 32B parameters, with supervised fine-tuning, rejection fine-tuning and reinforcement learning. Our experimental results demonstrate that Hint-Engineering models achieve 4\% and 8\% absolute improvements on DeepSeek-R1-Distill-Qwen-32B and DeepSeek-R1-Distill-Qwen-1.5B respectively, across five challenging mathematical reasoning datasets. Furthermore, Hint-Engineering models use about 30\% fewer tokens for the 32B model and 50\% fewer tokens for the 1.5B model compared with the natural language models. The models and code are available at https://github.com/ChengpengLi1003/CoRT.
On Reasoning Strength Planning in Large Reasoning Models
Jun 10, 2025Recent studies empirically reveal that large reasoning models (LRMs) can automatically allocate more reasoning strengths (i.e., the number of reasoning tokens) for harder problems, exhibiting difficulty-awareness for better task performance. While this automatic reasoning strength allocation phenomenon has been widely observed, its underlying mechanism remains largely unexplored. To this end, we provide explanations for this phenomenon from the perspective of model activations. We find evidence that LRMs pre-plan the reasoning strengths in their activations even before generation, with this reasoning strength causally controlled by the magnitude of a pre-allocated directional vector. Specifically, we show that the number of reasoning tokens is predictable solely based on the question activations using linear probes, indicating that LRMs estimate the required reasoning strength in advance. We then uncover that LRMs encode this reasoning strength through a pre-allocated directional vector embedded in the activations of the model, where the vector's magnitude modulates the reasoning strength. Subtracting this vector can lead to reduced reasoning token number and performance, while adding this vector can lead to increased reasoning token number and even improved performance. We further reveal that this direction vector consistently yields positive reasoning length prediction, and it modifies the logits of end-of-reasoning token </think> to affect the reasoning length. Finally, we demonstrate two potential applications of our findings: overthinking behavior detection and enabling efficient reasoning on simple problems. Our work provides new insights into the internal mechanisms of reasoning in LRMs and offers practical tools for controlling their reasoning behaviors. Our code is available at https://github.com/AlphaLab-USTC/LRM-plans-CoT.
AlphaSteer: Learning Refusal Steering with Principled Null-Space Constraint
Jun 08, 2025



As LLMs are increasingly deployed in real-world applications, ensuring their ability to refuse malicious prompts, especially jailbreak attacks, is essential for safe and reliable use. Recently, activation steering has emerged as an effective approach for enhancing LLM safety by adding a refusal direction vector to internal activations of LLMs during inference, which will further induce the refusal behaviors of LLMs. However, indiscriminately applying activation steering fundamentally suffers from the trade-off between safety and utility, since the same steering vector can also lead to over-refusal and degraded performance on benign prompts. Although prior efforts, such as vector calibration and conditional steering, have attempted to mitigate this trade-off, their lack of theoretical grounding limits their robustness and effectiveness. To better address the trade-off between safety and utility, we present a theoretically grounded and empirically effective activation steering method called AlphaSteer. Specifically, it considers activation steering as a learnable process with two principled learning objectives: utility preservation and safety enhancement. For utility preservation, it learns to construct a nearly zero vector for steering benign data, with the null-space constraints. For safety enhancement, it learns to construct a refusal direction vector for steering malicious data, with the help of linear regression. Experiments across multiple jailbreak attacks and utility benchmarks demonstrate the effectiveness of AlphaSteer, which significantly improves the safety of LLMs without compromising general capabilities. Our codes are available at https://github.com/AlphaLab-USTC/AlphaSteer.
LCB-CV-UNet: Enhanced Detector for High Dynamic Range Radar Signals
May 29, 2025We propose the LCB-CV-UNet to tackle performance degradation caused by High Dynamic Range (HDR) radar signals. Initially, a hardware-efficient, plug-and-play module named Logarithmic Connect Block (LCB) is proposed as a phase coherence preserving solution to address the inherent challenges in handling HDR features. Then, we propose the Dual Hybrid Dataset Construction method to generate a semi-synthetic dataset, approximating typical HDR signal scenarios with adjustable target distributions. Simulation results show about 1% total detection probability improvement with under 0.9% computational complexity added compared with the baseline. Furthermore, it excels 5% over the baseline at the range in 11-13 dB signal-to-noise ratio typical for urban targets. Finally, the real experiment validates the practicality of our model.
Addressing Missing Data Issue for Diffusion-based Recommendation
May 18, 2025Diffusion models have shown significant potential in generating oracle items that best match user preference with guidance from user historical interaction sequences. However, the quality of guidance is often compromised by unpredictable missing data in observed sequence, leading to suboptimal item generation. Since missing data is uncertain in both occurrence and content, recovering it is impractical and may introduce additional errors. To tackle this challenge, we propose a novel dual-side Thompson sampling-based Diffusion Model (TDM), which simulates extra missing data in the guidance signals and allows diffusion models to handle existing missing data through extrapolation. To preserve user preference evolution in sequences despite extra missing data, we introduce Dual-side Thompson Sampling to implement simulation with two probability models, sampling by exploiting user preference from both item continuity and sequence stability. TDM strategically removes items from sequences based on dual-side Thompson sampling and treats these edited sequences as guidance for diffusion models, enhancing models' robustness to missing data through consistency regularization. Additionally, to enhance the generation efficiency, TDM is implemented under the denoising diffusion implicit models to accelerate the reverse process. Extensive experiments and theoretical analysis validate the effectiveness of TDM in addressing missing data in sequential recommendations.
Search and Refine During Think: Autonomous Retrieval-Augmented Reasoning of LLMs
May 16, 2025Large language models have demonstrated impressive reasoning capabilities but are inherently limited by their knowledge reservoir. Retrieval-augmented reasoning mitigates this limitation by allowing LLMs to query external resources, but existing methods often retrieve irrelevant or noisy information, hindering accurate reasoning. In this paper, we propose AutoRefine, a reinforcement learning post-training framework that adopts a new ``search-and-refine-during-think'' paradigm. AutoRefine introduces explicit knowledge refinement steps between successive search calls, enabling the model to iteratively filter, distill, and organize evidence before generating an answer. Furthermore, we incorporate tailored retrieval-specific rewards alongside answer correctness rewards using group relative policy optimization. Experiments on single-hop and multi-hop QA benchmarks demonstrate that AutoRefine significantly outperforms existing approaches, particularly in complex, multi-hop reasoning scenarios. Detailed analysis shows that AutoRefine issues frequent, higher-quality searches and synthesizes evidence effectively.
AlphaFuse: Learn ID Embeddings for Sequential Recommendation in Null Space of Language Embeddings
Apr 29, 2025



Recent advancements in sequential recommendation have underscored the potential of Large Language Models (LLMs) for enhancing item embeddings. However, existing approaches face three key limitations: 1) the degradation of the semantic space when high-dimensional language embeddings are mapped to lower-dimensional ID embeddings, 2) the underutilization of language embeddings, and 3) the reliance on additional trainable parameters, such as an adapter, to bridge the gap between the semantic and behavior spaces. In this paper, we introduce AlphaFuse, a simple but effective language-guided learning strategy that addresses these challenges by learning ID embeddings within the null space of language embeddings. Specifically, we decompose the semantic space of language embeddings via Singular Value Decomposition (SVD), distinguishing it into a semantic-rich row space and a semantic-sparse null space. Collaborative signals are then injected into the null space, while preserving the rich semantics of the row space. AlphaFuse prevents degradation of the semantic space, integrates the retained language embeddings into the final item embeddings, and eliminates the need for auxiliary trainable modules, enabling seamless adaptation to any sequential recommendation framework. We validate the effectiveness and flexibility of AlphaFuse through extensive experiments on three benchmark datasets, including cold-start user and long-tail settings, showcasing significant improvements in both discriminative and diffusion-based generative sequential recommenders. Our codes and datasets are available at https://github.com/Hugo-Chinn/AlphaFuse.
An Empirical Study on Prompt Compression for Large Language Models
Apr 24, 2025Prompt engineering enables Large Language Models (LLMs) to perform a variety of tasks. However, lengthy prompts significantly increase computational complexity and economic costs. To address this issue, we study six prompt compression methods for LLMs, aiming to reduce prompt length while maintaining LLM response quality. In this paper, we present a comprehensive analysis covering aspects such as generation performance, model hallucinations, efficacy in multimodal tasks, word omission analysis, and more. We evaluate these methods across 13 datasets, including news, scientific articles, commonsense QA, math QA, long-context QA, and VQA datasets. Our experiments reveal that prompt compression has a greater impact on LLM performance in long contexts compared to short ones. In the Longbench evaluation, moderate compression even enhances LLM performance. Our code and data is available at https://github.com/3DAgentWorld/Toolkit-for-Prompt-Compression.