 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransporting Causal Mechanisms for Unsupervised Domain Adaptation
Jul 28, 2021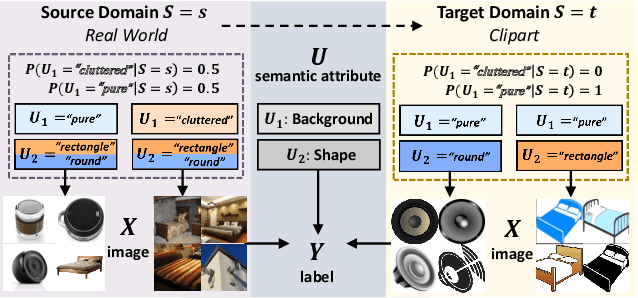
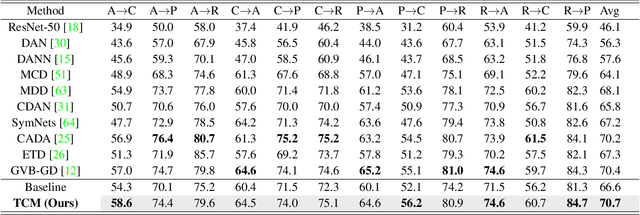
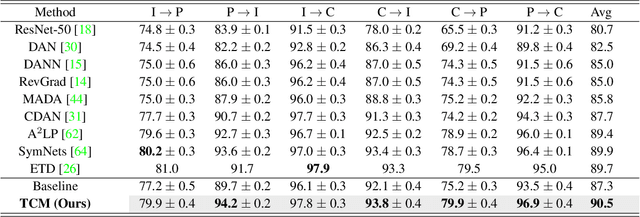
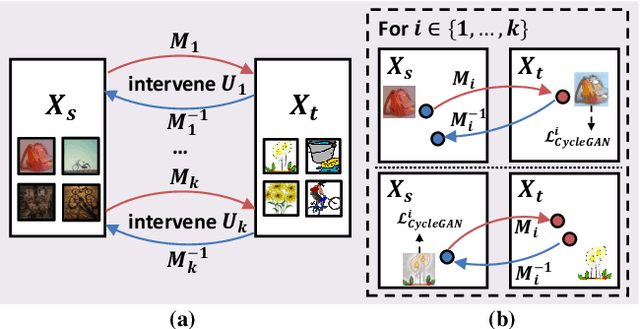
Existing Unsupervised Domain Adaptation (UDA) literature adopts the covariate shift and conditional shift assumptions, which essentially encourage models to learn common features across domains. However, due to the lack of supervision in the target domain, they suffer from the semantic loss: the feature will inevitably lose non-discriminative semantics in source domain, which is however discriminative in target domain. We use a causal view -- transportability theory -- to identify that such loss is in fact a confounding effect, which can only be removed by causal intervention. However, the theoretical solution provided by transportability is far from practical for UDA, because it requires the stratification and representation of the unobserved confounder that is the cause of the domain gap. To this end, we propose a practical solution: Transporting Causal Mechanisms (TCM), to identify the confounder stratum and representations by using the domain-invariant disentangled causal mechanisms, which are discovered in an unsupervised fashion. Our TCM is both theoretically and empirically grounded. Extensive experiments show that TCM achieves state-of-the-art performance on three challenging UDA benchmarks: ImageCLEF-DA, Office-Home, and VisDA-2017. Codes are available in Appendix.
Aug3D-RPN: Improving Monocular 3D Object Detection by Synthetic Images with Virtual Depth
Jul 28, 2021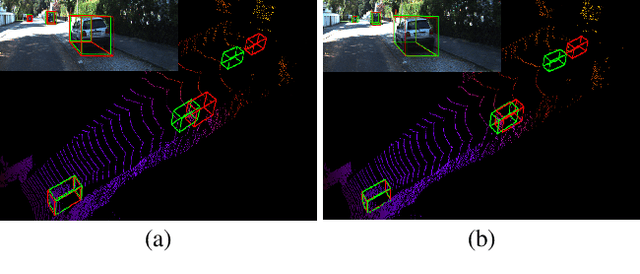
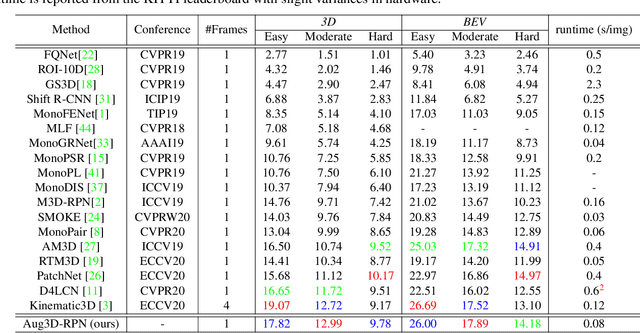
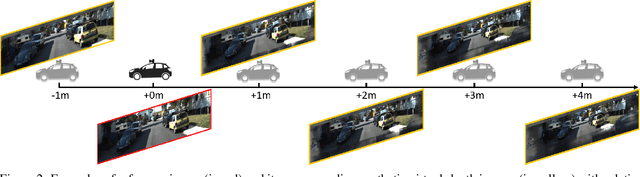
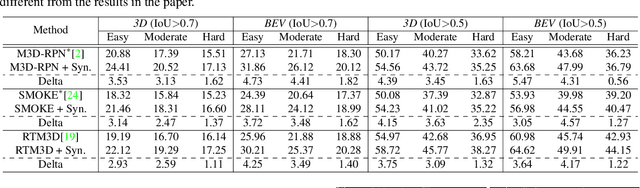
Current geometry-based monocular 3D object detection models can efficiently detect objects by leveraging perspective geometry, but their performance is limited due to the absence of accurate depth information. Though this issue can be alleviated in a depth-based model where a depth estimation module is plugged to predict depth information before 3D box reasoning, the introduction of such module dramatically reduces the detection speed. Instead of training a costly depth estimator, we propose a rendering module to augment the training data by synthesizing images with virtual-depths. The rendering module takes as input the RGB image and its corresponding sparse depth image, outputs a variety of photo-realistic synthetic images, from which the detection model can learn more discriminative features to adapt to the depth changes of the objects. Besides, we introduce an auxiliary module to improve the detection model by jointly optimizing it through a depth estimation task. Both modules are working in the training time and no extra computation will be introduced to the detection model. Experiments show that by working with our proposed modules, a geometry-based model can represent the leading accuracy on the KITTI 3D detection benchmark.
Revisiting Knowledge Distillation: An Inheritance and Exploration Framework
Jul 01, 2021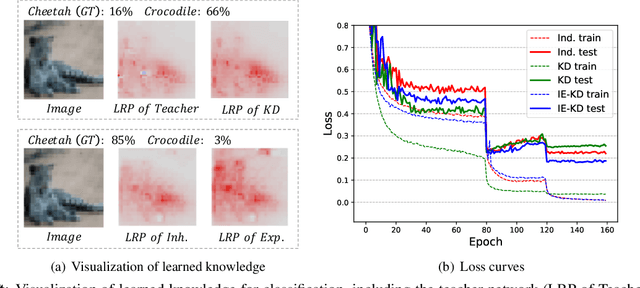

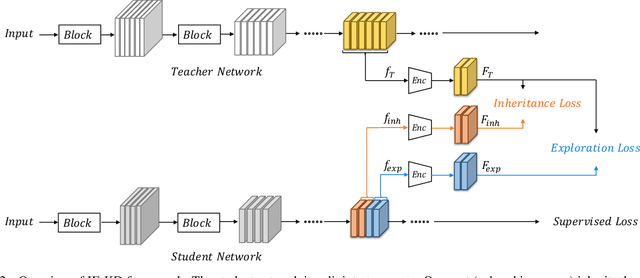

Knowledge Distillation (KD) is a popular technique to transfer knowledge from a teacher model or ensemble to a student model. Its success is generally attributed to the privileged information on similarities/consistency between the class distributions or intermediate feature representations of the teacher model and the student model. However, directly pushing the student model to mimic the probabilities/features of the teacher model to a large extent limits the student model in learning undiscovered knowledge/features. In this paper, we propose a novel inheritance and exploration knowledge distillation framework (IE-KD), in which a student model is split into two parts - inheritance and exploration. The inheritance part is learned with a similarity loss to transfer the existing learned knowledge from the teacher model to the student model, while the exploration part is encouraged to learn representations different from the inherited ones with a dis-similarity loss. Our IE-KD framework is generic and can be easily combined with existing distillation or mutual learning methods for training deep neural networks. Extensive experiments demonstrate that these two parts can jointly push the student model to learn more diversified and effective representations, and our IE-KD can be a general technique to improve the student network to achieve SOTA performance. Furthermore, by applying our IE-KD to the training of two networks, the performance of both can be improved w.r.t. deep mutual learning. The code and models of IE-KD will be make publicly available at https://github.com/yellowtownhz/IE-KD.
Criterion-based Heterogeneous Collaborative Filtering for Multi-behavior Implicit Recommendation
May 28, 2021

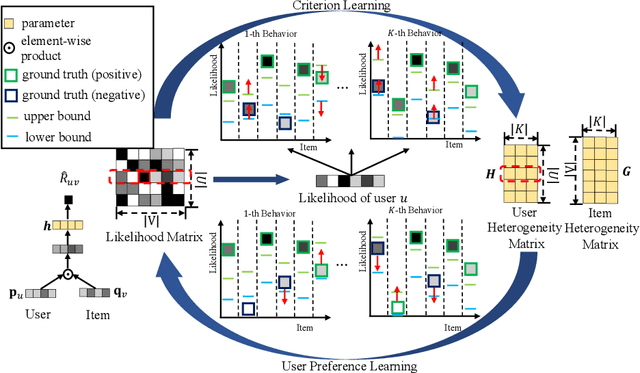

With the increasing scale and diversification of interaction behaviors in E-commerce, more and more researchers pay attention to multi-behavior recommender systems that utilize interaction data of other auxiliary behaviors such as view and cart. To address these challenges in heterogeneous scenarios, non-sampling methods have shown superiority over negative sampling methods. However, two observations are usually ignored in existing state-of-the-art non-sampling methods based on binary regression: (1) users have different preference strengths for different items, so they cannot be measured simply by binary implicit data; (2) the dependency across multiple behaviors varies for different users and items. To tackle the above issue, we propose a novel non-sampling learning framework named \underline{C}riterion-guided \underline{H}eterogeneous \underline{C}ollaborative \underline{F}iltering (CHCF). CHCF introduces both upper and lower bounds to indicate selection criteria, which will guide user preference learning. Besides, CHCF integrates criterion learning and user preference learning into a unified framework, which can be trained jointly for the interaction prediction on target behavior. We further theoretically demonstrate that the optimization of Collaborative Metric Learning can be approximately achieved by CHCF learning framework in a non-sampling form effectively. Extensive experiments on two real-world datasets show that CHCF outperforms the state-of-the-art methods in heterogeneous scenarios.
Cloth-Changing Person Re-identification from A Single Image with Gait Prediction and Regularization
Apr 18, 2021
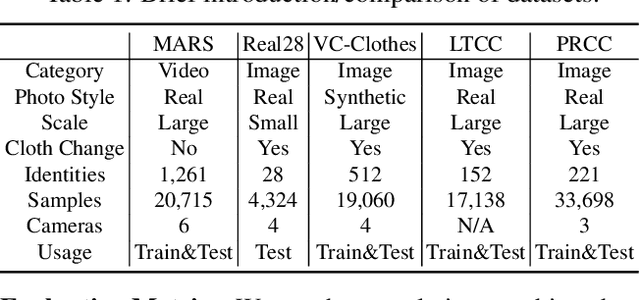
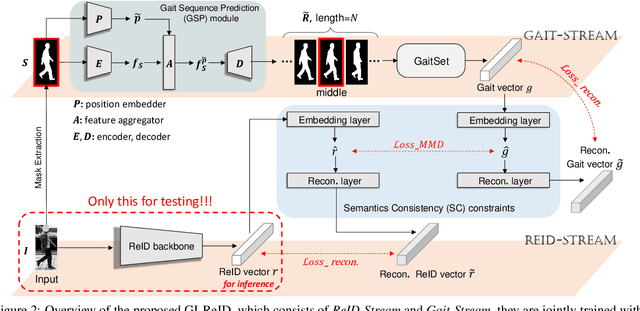
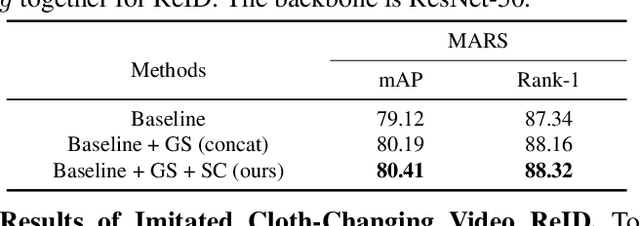
Cloth-Changing person re-identification (CC-ReID) aims at matching the same person across different locations over a long-duration, e.g., over days, and therefore inevitably meets challenge of changing clothing. In this paper, we focus on handling well the CC-ReID problem under a more challenging setting, i.e., just from a single image, which enables high-efficiency and latency-free pedestrian identify for real-time surveillance applications. Specifically, we introduce Gait recognition as an auxiliary task to drive the Image ReID model to learn cloth-agnostic representations by leveraging personal unique and cloth-independent gait information, we name this framework as GI-ReID. GI-ReID adopts a two-stream architecture that consists of a image ReID-Stream and an auxiliary gait recognition stream (Gait-Stream). The Gait-Stream, that is discarded in the inference for high computational efficiency, acts as a regulator to encourage the ReID-Stream to capture cloth-invariant biometric motion features during the training. To get temporal continuous motion cues from a single image, we design a Gait Sequence Prediction (GSP) module for Gait-Stream to enrich gait information. Finally, a high-level semantics consistency over two streams is enforced for effective knowledge regularization. Experiments on multiple image-based Cloth-Changing ReID benchmarks, e.g., LTCC, PRCC, Real28, and VC-Clothes, demonstrate that GI-ReID performs favorably against the state-of-the-arts. Codes are available at https://github.com/jinx-USTC/GI-ReID.
Graph Contrastive Clustering
Apr 03, 2021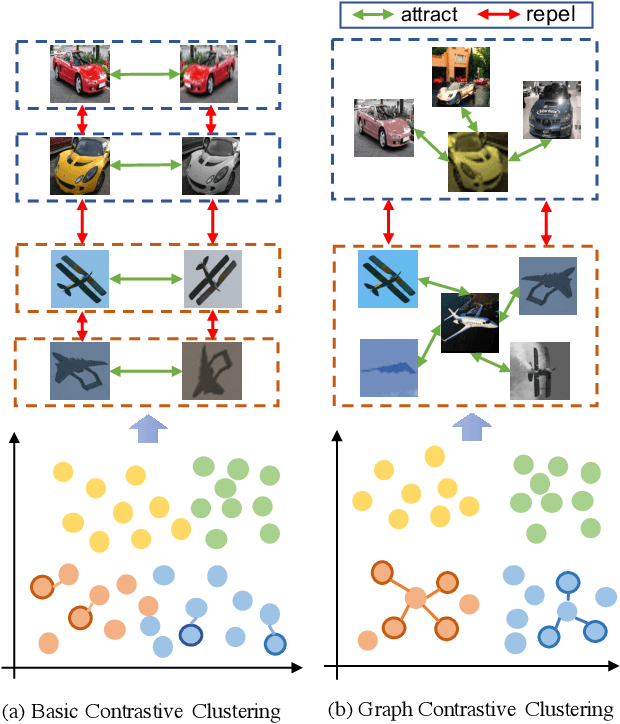
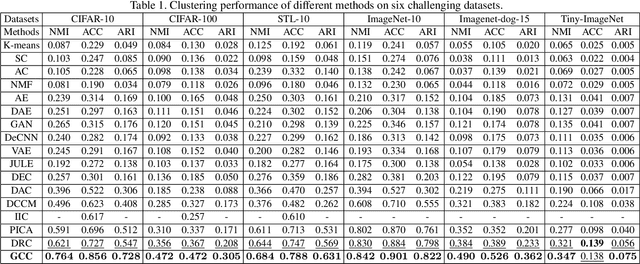
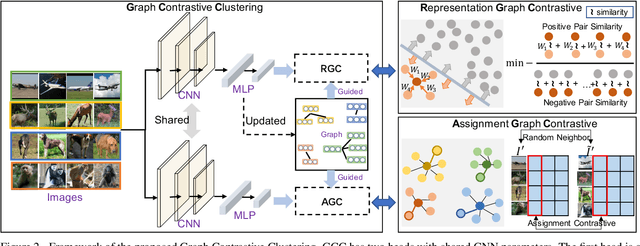
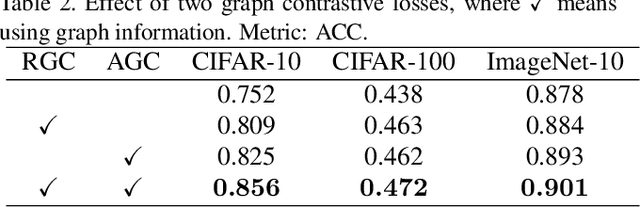
Recently, some contrastive learning methods have been proposed to simultaneously learn representations and clustering assignments, achieving significant improvements. However, these methods do not take the category information and clustering objective into consideration, thus the learned representations are not optimal for clustering and the performance might be limited. Towards this issue, we first propose a novel graph contrastive learning framework, which is then applied to the clustering task and we come up with the Graph Constrastive Clustering~(GCC) method. Different from basic contrastive clustering that only assumes an image and its augmentation should share similar representation and clustering assignments, we lift the instance-level consistency to the cluster-level consistency with the assumption that samples in one cluster and their augmentations should all be similar. Specifically, on the one hand, the graph Laplacian based contrastive loss is proposed to learn more discriminative and clustering-friendly features. On the other hand, a novel graph-based contrastive learning strategy is proposed to learn more compact clustering assignments. Both of them incorporate the latent category information to reduce the intra-cluster variance while increasing the inter-cluster variance. Experiments on six commonly used datasets demonstrate the superiority of our proposed approach over the state-of-the-art methods.
Half-Real Half-Fake Distillation for Class-Incremental Semantic Segmentation
Apr 02, 2021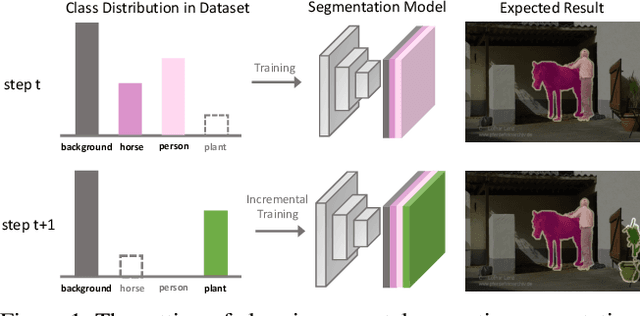
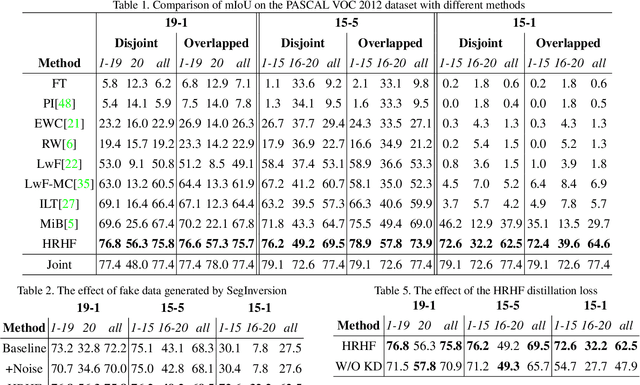
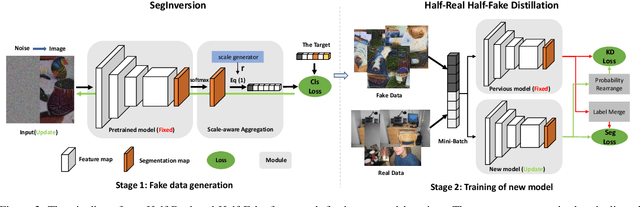

Despite their success for semantic segmentation, convolutional neural networks are ill-equipped for incremental learning, \ie, adapting the original segmentation model as new classes are available but the initial training data is not retained. Actually, they are vulnerable to catastrophic forgetting problem. We try to address this issue by "inverting" the trained segmentation network to synthesize input images starting from random noise. To avoid setting detailed pixel-wise segmentation maps as the supervision manually, we propose the SegInversion to synthesize images using the image-level labels. To increase the diversity of synthetic images, the Scale-Aware Aggregation module is integrated into SegInversion for controlling the scale (the number of pixels) of synthetic objects. Along with real images of new classes, the synthesized images will be fed into the distillation-based framework to train the new segmentation model which retains the information about previously learned classes, whilst updating the current model to learn the new ones. The proposed method significantly outperforms other incremental learning methods and obtains state-of-the-art performance on the PASCAL VOC 2012 and ADE20K datasets. The code and models will be made publicly available.
Dense Interaction Learning for Video-based Person Re-identification
Mar 18, 2021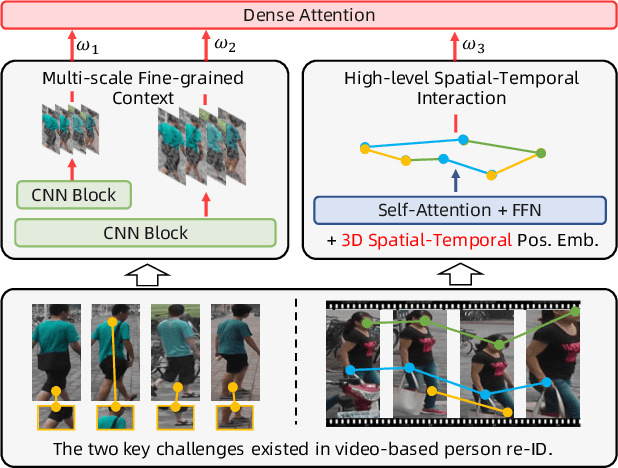
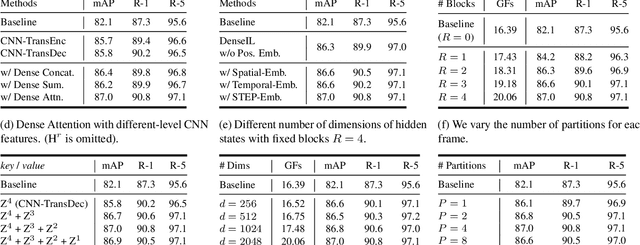
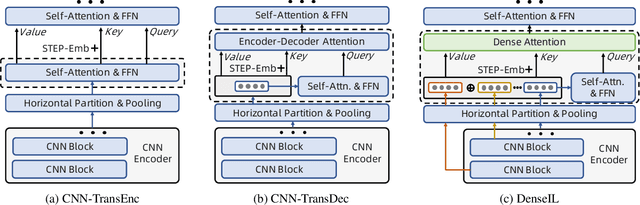
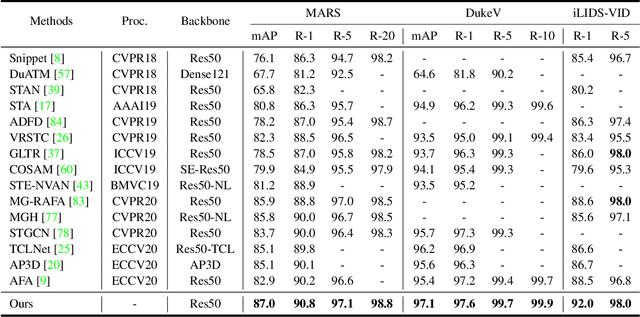
Video-based person re-identification (re-ID) aims at matching the same person across video clips. Efficiently exploiting multi-scale fine-grained features while building the structural interaction among them is pivotal for its success. In this paper, we propose a hybrid framework, Dense Interaction Learning (DenseIL), that takes the principal advantages of both CNN-based and Attention-based architectures to tackle video-based person re-ID difficulties. DenseIL contains a CNN encoder and a Dense Interaction (DI) decoder. The CNN encoder is responsible for efficiently extracting discriminative spatial features while the DI decoder is designed to densely model spatial-temporal inherent interaction across frames. Different from previous works, we additionally let the DI decoder densely attends to intermediate fine-grained CNN features and that naturally yields multi-grained spatial-temporal representation for each video clip. Moreover, we introduce Spatio-TEmporal Positional Embedding (STEP-Emb) into the DI decoder to investigate the positional relation among the spatial-temporal inputs. Our experiments consistently and significantly outperform all the state-of-the-art methods on multiple standard video-based re-ID datasets.
Distilling Causal Effect of Data in Class-Incremental Learning
Mar 08, 2021
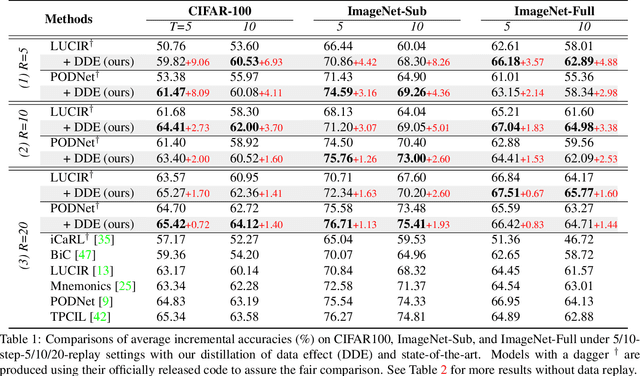
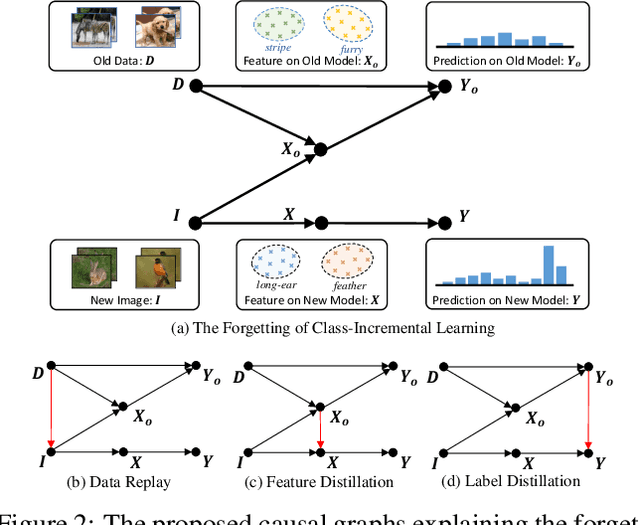
We propose a causal framework to explain the catastrophic forgetting in Class-Incremental Learning (CIL) and then derive a novel distillation method that is orthogonal to the existing anti-forgetting techniques, such as data replay and feature/label distillation. We first 1) place CIL into the framework, 2) answer why the forgetting happens: the causal effect of the old data is lost in new training, and then 3) explain how the existing techniques mitigate it: they bring the causal effect back. Based on the framework, we find that although the feature/label distillation is storage-efficient, its causal effect is not coherent with the end-to-end feature learning merit, which is however preserved by data replay. To this end, we propose to distill the Colliding Effect between the old and the new data, which is fundamentally equivalent to the causal effect of data replay, but without any cost of replay storage. Thanks to the causal effect analysis, we can further capture the Incremental Momentum Effect of the data stream, removing which can help to retain the old effect overwhelmed by the new data effect, and thus alleviate the forgetting of the old class in testing. Extensive experiments on three CIL benchmarks: CIFAR-100, ImageNet-Sub&Full, show that the proposed causal effect distillation can improve various state-of-the-art CIL methods by a large margin (0.72%--9.06%).
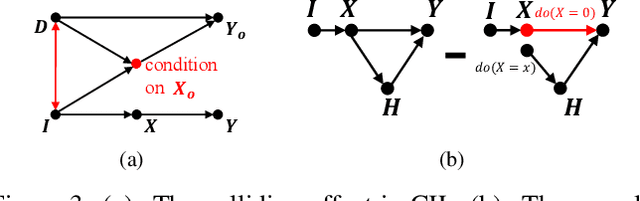
Counterfactual Zero-Shot and Open-Set Visual Recognition
Mar 01, 2021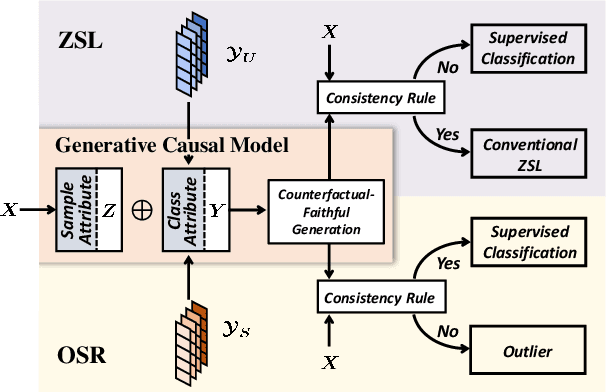
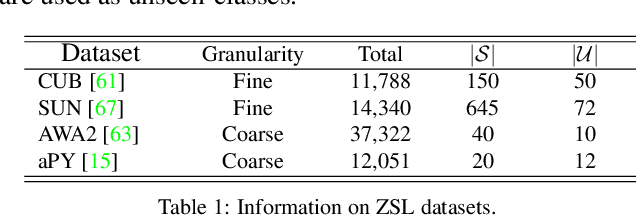
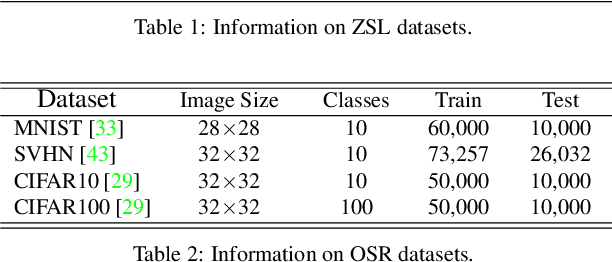
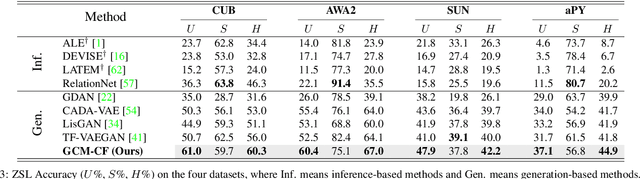
We present a novel counterfactual framework for both Zero-Shot Learning (ZSL) and Open-Set Recognition (OSR), whose common challenge is generalizing to the unseen-classes by only training on the seen-classes. Our idea stems from the observation that the generated samples for unseen-classes are often out of the true distribution, which causes severe recognition rate imbalance between the seen-class (high) and unseen-class (low). We show that the key reason is that the generation is not Counterfactual Faithful, and thus we propose a faithful one, whose generation is from the sample-specific counterfactual question: What would the sample look like, if we set its class attribute to a certain class, while keeping its sample attribute unchanged? Thanks to the faithfulness, we can apply the Consistency Rule to perform unseen/seen binary classification, by asking: Would its counterfactual still look like itself? If ``yes'', the sample is from a certain class, and ``no'' otherwise. Through extensive experiments on ZSL and OSR, we demonstrate that our framework effectively mitigates the seen/unseen imbalance and hence significantly improves the overall performance. Note that this framework is orthogonal to existing methods, thus, it can serve as a new baseline to evaluate how ZSL/OSR models generalize. Codes are available at https://github.com/yue-zhongqi/gcm-cf.