 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecMoE: Communication-Efficient Secure MoE Inference via Select-Then-Compute
Jan 11, 2026Privacy-preserving Transformer inference has gained attention due to the potential leakage of private information. Despite recent progress, existing frameworks still fall short of practical model scales, with gaps up to a hundredfold. A possible way to close this gap is the Mixture of Experts (MoE) architecture, which has emerged as a promising technique to scale up model capacity with minimal overhead. However, given that the current secure two-party (2-PC) protocols allow the server to homomorphically compute the FFN layer with its plaintext model weight, under the MoE setting, this could reveal which expert is activated to the server, exposing token-level privacy about the client's input. While naively evaluating all the experts before selection could protect privacy, it nullifies MoE sparsity and incurs the heavy computational overhead that sparse MoE seeks to avoid. To address the privacy and efficiency limitations above, we propose a 2-PC privacy-preserving inference framework, \SecMoE. Unifying per-entry circuits in both the MoE layer and piecewise polynomial functions, \SecMoE obliviously selects the extracted parameters from circuits and only computes one encrypted entry, which we refer to as Select-Then-Compute. This makes the model for private inference scale to 63$\times$ larger while only having a 15.2$\times$ increase in end-to-end runtime. Extensive experiments show that, under 5 expert settings, \SecMoE lowers the end-to-end private inference communication by 1.8$\sim$7.1$\times$ and achieves 1.3$\sim$3.8$\times$ speedup compared to the state-of-the-art (SOTA) protocols.
VReID-XFD: Video-based Person Re-identification at Extreme Far Distance Challenge Results
Jan 04, 2026Person re-identification (ReID) across aerial and ground views at extreme far distances introduces a distinct operating regime where severe resolution degradation, extreme viewpoint changes, unstable motion cues, and clothing variation jointly undermine the appearance-based assumptions of existing ReID systems. To study this regime, we introduce VReID-XFD, a video-based benchmark and community challenge for extreme far-distance (XFD) aerial-to-ground person re-identification. VReID-XFD is derived from the DetReIDX dataset and comprises 371 identities, 11,288 tracklets, and 11.75 million frames, captured across altitudes from 5.8 m to 120 m, viewing angles from oblique (30 degrees) to nadir (90 degrees), and horizontal distances up to 120 m. The benchmark supports aerial-to-aerial, aerial-to-ground, and ground-to-aerial evaluation under strict identity-disjoint splits, with rich physical metadata. The VReID-XFD-25 Challenge attracted 10 teams with hundreds of submissions. Systematic analysis reveals monotonic performance degradation with altitude and distance, a universal disadvantage of nadir views, and a trade-off between peak performance and robustness. Even the best-performing SAS-PReID method achieves only 43.93 percent mAP in the aerial-to-ground setting. The dataset, annotations, and official evaluation protocols are publicly available at https://www.it.ubi.pt/DetReIDX/ .
Bridging Vision and Language for Robust Context-Aware Surgical Point Tracking: The VL-SurgPT Dataset and Benchmark
Nov 15, 2025Accurate point tracking in surgical environments remains challenging due to complex visual conditions, including smoke occlusion, specular reflections, and tissue deformation. While existing surgical tracking datasets provide coordinate information, they lack the semantic context necessary to understand tracking failure mechanisms. We introduce VL-SurgPT, the first large-scale multimodal dataset that bridges visual tracking with textual descriptions of point status in surgical scenes. The dataset comprises 908 in vivo video clips, including 754 for tissue tracking (17,171 annotated points across five challenging scenarios) and 154 for instrument tracking (covering seven instrument types with detailed keypoint annotations). We establish comprehensive benchmarks using eight state-of-the-art tracking methods and propose TG-SurgPT, a text-guided tracking approach that leverages semantic descriptions to improve robustness in visually challenging conditions. Experimental results demonstrate that incorporating point status information significantly improves tracking accuracy and reliability, particularly in adverse visual scenarios where conventional vision-only methods struggle. By bridging visual and linguistic modalities, VL-SurgPT enables the development of context-aware tracking systems crucial for advancing computer-assisted surgery applications that can maintain performance even under challenging intraoperative conditions.
Volumetric Ultrasound via 3D Null Subtraction Imaging with Circular and Spiral Apertures
Nov 15, 2025Volumetric ultrasound imaging faces a fundamental trade-off among image quality, frame rate, and hardware complexity. This study introduces three-dimensional Null Subtraction Imaging (3D NSI), a nonlinear beamforming framework that addresses this trade-off by combining computationally efficient null-subtraction process with multiplexing-aware sparse aperture designs on matrix arrays. We evaluate three apodization configurations: a fully addressed circular aperture and two Fermat's spiral sparse apertures. To overcome channel-sharing constraints common in matrix arrays multiplexed with low-channel-count ultrasound systems, we propose a spiral "no-reuse" apodization that enforces non-overlapping element sets across transmit-receive events. This design resolves multiplexing conflicts and enables up to a 16-fold increase in acquisition volume rate using only 240 active elements on a 1024-element probe. In computer simulations and tissue-mimicking phantom experiments, 3D NSI achieved an average improvement of 36% in azimuthal and elevational resolutions, along with an approximately 20% higher contrast ratio, compared to the conventional Delay-and-Sum (DAS) beamformer under matched transmit/receive configurations. When implemented with the spiral no-reuse aperture, the 3D NSI framework achieved over 1000 volumes per second with a computational load less than three times that of DAS, making it a practical solution for real-time 4D imaging.
AI-Integrated Decision Support System for Real-Time Market Growth Forecasting and Multi-Source Content Diffusion Analytics
Nov 13, 2025The rapid proliferation of AI-generated content (AIGC) has reshaped the dynamics of digital marketing and online consumer behavior. However, predicting the diffusion trajectory and market impact of such content remains challenging due to data heterogeneity, non linear propagation mechanisms, and evolving consumer interactions. This study proposes an AI driven Decision Support System (DSS) that integrates multi source data including social media streams, marketing expenditure records, consumer engagement logs, and sentiment dynamics using a hybrid Graph Neural Network (GNN) and Temporal Transformer framework. The model jointly learns the content diffusion structure and temporal influence evolution through a dual channel architecture, while causal inference modules disentangle the effects of marketing stimuli on return on investment (ROI) and market visibility. Experiments on large scale real-world datasets collected from multiple online platforms such as Twitter, TikTok, and YouTube advertising show that our system outperforms existing baselines in all six metrics. The proposed DSS enhances marketing decisions by providing interpretable real-time insights into AIGC driven content dissemination and market growth patterns.
TruthfulRAG: Resolving Factual-level Conflicts in Retrieval-Augmented Generation with Knowledge Graphs
Nov 13, 2025



Retrieval-Augmented Generation (RAG) has emerged as a powerful framework for enhancing the capabilities of Large Language Models (LLMs) by integrating retrieval-based methods with generative models. As external knowledge repositories continue to expand and the parametric knowledge within models becomes outdated, a critical challenge for RAG systems is resolving conflicts between retrieved external information and LLMs' internal knowledge, which can significantly compromise the accuracy and reliability of generated content. However, existing approaches to conflict resolution typically operate at the token or semantic level, often leading to fragmented and partial understanding of factual discrepancies between LLMs' knowledge and context, particularly in knowledge-intensive tasks. To address this limitation, we propose TruthfulRAG, the first framework that leverages Knowledge Graphs (KGs) to resolve factual-level knowledge conflicts in RAG systems. Specifically, TruthfulRAG constructs KGs by systematically extracting triples from retrieved content, utilizes query-based graph retrieval to identify relevant knowledge, and employs entropy-based filtering mechanisms to precisely locate conflicting elements and mitigate factual inconsistencies, thereby enabling LLMs to generate faithful and accurate responses. Extensive experiments reveal that TruthfulRAG outperforms existing methods, effectively alleviating knowledge conflicts and improving the robustness and trustworthiness of RAG systems.
FlowDrive: Energy Flow Field for End-to-End Autonomous Driving
Sep 17, 2025Recent advances in end-to-end autonomous driving leverage multi-view images to construct BEV representations for motion planning. In motion planning, autonomous vehicles need considering both hard constraints imposed by geometrically occupied obstacles (e.g., vehicles, pedestrians) and soft, rule-based semantics with no explicit geometry (e.g., lane boundaries, traffic priors). However, existing end-to-end frameworks typically rely on BEV features learned in an implicit manner, lacking explicit modeling of risk and guidance priors for safe and interpretable planning. To address this, we propose FlowDrive, a novel framework that introduces physically interpretable energy-based flow fields-including risk potential and lane attraction fields-to encode semantic priors and safety cues into the BEV space. These flow-aware features enable adaptive refinement of anchor trajectories and serve as interpretable guidance for trajectory generation. Moreover, FlowDrive decouples motion intent prediction from trajectory denoising via a conditional diffusion planner with feature-level gating, alleviating task interference and enhancing multimodal diversity. Experiments on the NAVSIM v2 benchmark demonstrate that FlowDrive achieves state-of-the-art performance with an EPDMS of 86.3, surpassing prior baselines in both safety and planning quality. The project is available at https://astrixdrive.github.io/FlowDrive.github.io/.
Class-invariant Test-Time Augmentation for Domain Generalization
Sep 17, 2025Deep models often suffer significant performance degradation under distribution shifts. Domain generalization (DG) seeks to mitigate this challenge by enabling models to generalize to unseen domains. Most prior approaches rely on multi-domain training or computationally intensive test-time adaptation. In contrast, we propose a complementary strategy: lightweight test-time augmentation. Specifically, we develop a novel Class-Invariant Test-Time Augmentation (CI-TTA) technique. The idea is to generate multiple variants of each input image through elastic and grid deformations that nevertheless belong to the same class as the original input. Their predictions are aggregated through a confidence-guided filtering scheme that remove unreliable outputs, ensuring the final decision relies on consistent and trustworthy cues. Extensive Experiments on PACS and Office-Home datasets demonstrate consistent gains across different DG algorithms and backbones, highlighting the effectiveness and generality of our approach.
Mobile-Agent-v3: Foundamental Agents for GUI Automation
Aug 21, 2025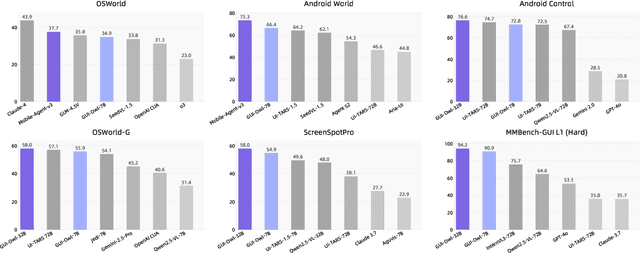
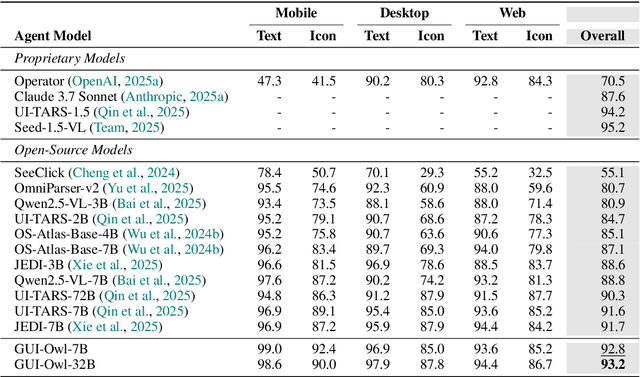
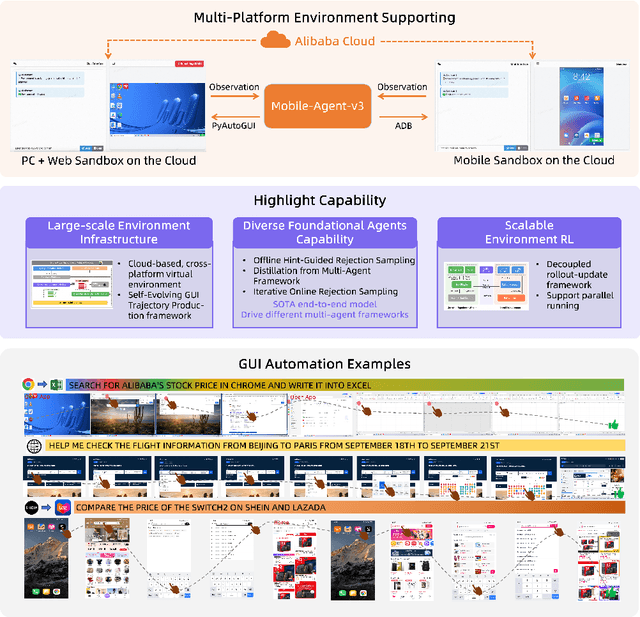
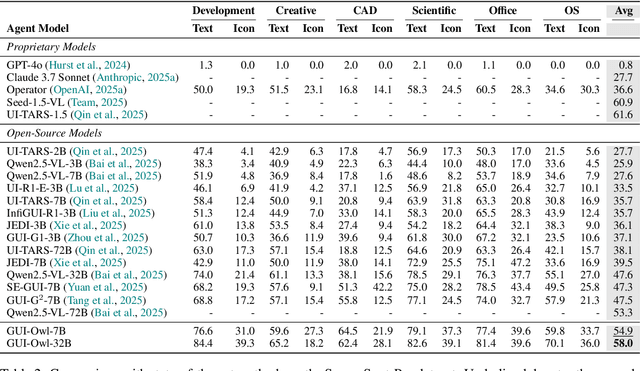
This paper introduces GUI-Owl, a foundational GUI agent model that achieves state-of-the-art performance among open-source end-to-end models on ten GUI benchmarks across desktop and mobile environments, covering grounding, question answering, planning, decision-making, and procedural knowledge. GUI-Owl-7B achieves 66.4 on AndroidWorld and 29.4 on OSWorld. Building on this, we propose Mobile-Agent-v3, a general-purpose GUI agent framework that further improves performance to 73.3 on AndroidWorld and 37.7 on OSWorld, setting a new state-of-the-art for open-source GUI agent frameworks. GUI-Owl incorporates three key innovations: (1) Large-scale Environment Infrastructure: a cloud-based virtual environment spanning Android, Ubuntu, macOS, and Windows, enabling our Self-Evolving GUI Trajectory Production framework. This generates high-quality interaction data via automated query generation and correctness validation, leveraging GUI-Owl to refine trajectories iteratively, forming a self-improving loop. It supports diverse data pipelines and reduces manual annotation. (2) Diverse Foundational Agent Capabilities: by integrating UI grounding, planning, action semantics, and reasoning patterns, GUI-Owl supports end-to-end decision-making and can act as a modular component in multi-agent systems. (3) Scalable Environment RL: we develop a scalable reinforcement learning framework with fully asynchronous training for real-world alignment. We also introduce Trajectory-aware Relative Policy Optimization (TRPO) for online RL, achieving 34.9 on OSWorld. GUI-Owl and Mobile-Agent-v3 are open-sourced at https://github.com/X-PLUG/MobileAgent.
A Comprehensive Survey of Self-Evolving AI Agents: A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems
Aug 10, 2025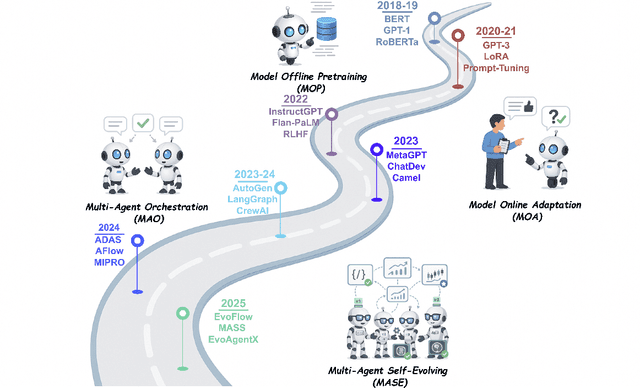
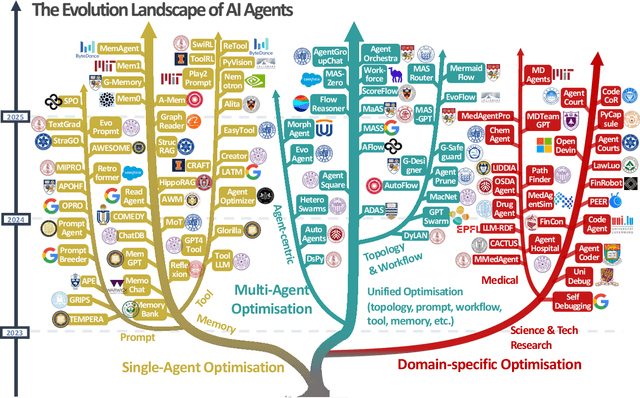
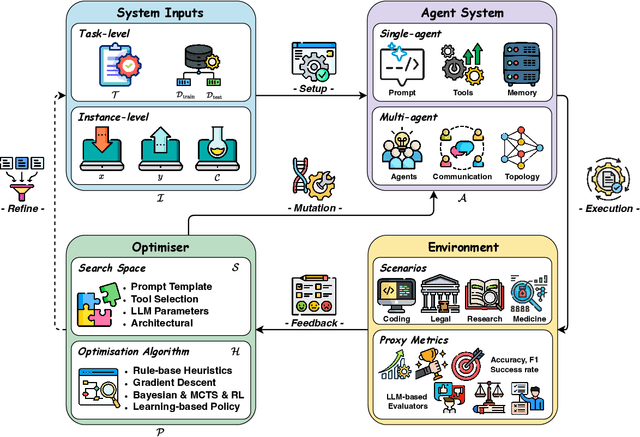
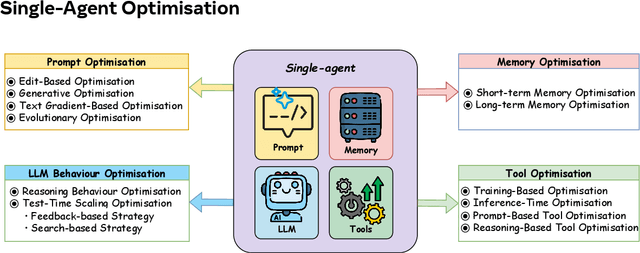
Recent advances in large language models have sparked growing interest in AI agents capable of solving complex, real-world tasks. However, most existing agent systems rely on manually crafted configurations that remain static after deployment, limiting their ability to adapt to dynamic and evolving environments. To this end, recent research has explored agent evolution techniques that aim to automatically enhance agent systems based on interaction data and environmental feedback. This emerging direction lays the foundation for self-evolving AI agents, which bridge the static capabilities of foundation models with the continuous adaptability required by lifelong agentic systems. In this survey, we provide a comprehensive review of existing techniques for self-evolving agentic systems. Specifically, we first introduce a unified conceptual framework that abstracts the feedback loop underlying the design of self-evolving agentic systems. The framework highlights four key components: System Inputs, Agent System, Environment, and Optimisers, serving as a foundation for understanding and comparing different strategies. Based on this framework, we systematically review a wide range of self-evolving techniques that target different components of the agent system. We also investigate domain-specific evolution strategies developed for specialised fields such as biomedicine, programming, and finance, where optimisation objectives are tightly coupled with domain constraints. In addition, we provide a dedicated discussion on the evaluation, safety, and ethical considerations for self-evolving agentic systems, which are critical to ensuring their effectiveness and reliability. This survey aims to provide researchers and practitioners with a systematic understanding of self-evolving AI agents, laying the foundation for the development of more adaptive, autonomous, and lifelong agentic systems.