 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Fluidic System Design and Control with Differentiable Simulation
May 22, 2024



We present a novel framework to explore neural control and design of complex fluidic systems with dynamic solid boundaries. Our system features a fast differentiable Navier-Stokes solver with solid-fluid interface handling, a low-dimensional differentiable parametric geometry representation, a control-shape co-design algorithm, and gym-like simulation environments to facilitate various fluidic control design applications. Additionally, we present a benchmark of design, control, and learning tasks on high-fidelity, high-resolution dynamic fluid environments that pose challenges for existing differentiable fluid simulators. These tasks include designing the control of artificial hearts, identifying robotic end-effector shapes, and controlling a fluid gate. By seamlessly incorporating our differentiable fluid simulator into a learning framework, we demonstrate successful design, control, and learning results that surpass gradient-free solutions in these benchmark tasks.
LLM and Simulation as Bilevel Optimizers: A New Paradigm to Advance Physical Scientific Discovery
May 16, 2024



Large Language Models have recently gained significant attention in scientific discovery for their extensive knowledge and advanced reasoning capabilities. However, they encounter challenges in effectively simulating observational feedback and grounding it with language to propel advancements in physical scientific discovery. Conversely, human scientists undertake scientific discovery by formulating hypotheses, conducting experiments, and revising theories through observational analysis. Inspired by this, we propose to enhance the knowledge-driven, abstract reasoning abilities of LLMs with the computational strength of simulations. We introduce Scientific Generative Agent (SGA), a bilevel optimization framework: LLMs act as knowledgeable and versatile thinkers, proposing scientific hypotheses and reason about discrete components, such as physics equations or molecule structures; meanwhile, simulations function as experimental platforms, providing observational feedback and optimizing via differentiability for continuous parts, such as physical parameters. We conduct extensive experiments to demonstrate our framework's efficacy in constitutive law discovery and molecular design, unveiling novel solutions that differ from conventional human expectations yet remain coherent upon analysis.
Replicating Human Anatomy with Vision Controlled Jetting -- A Pneumatic Musculoskeletal Hand and Forearm
Apr 29, 2024The functional replication and actuation of complex structures inspired by nature is a longstanding goal for humanity. Creating such complex structures combining soft and rigid features and actuating them with artificial muscles would further our understanding of natural kinematic structures. We printed a biomimetic hand in a single print process comprised of a rigid skeleton, soft joint capsules, tendons, and printed touch sensors. We showed it's actuation using electric motors. In this work, we expand on this work by adding a forearm that is also closely modeled after the human anatomy and replacing the hand's motors with 22 independently controlled pneumatic artificial muscles (PAMs). Our thin, high-strain (up to 30.1%) PAMs match the performance of state-of-the-art artificial muscles at a lower cost. The system showcases human-like dexterity with independent finger movements, demonstrating successful grasping of various objects, ranging from a small, lightweight coin to a large can of 272g in weight. The performance evaluation, based on fingertip and grasping forces along with finger joint range of motion, highlights the system's potential.
Representing Molecules as Random Walks Over Interpretable Grammars
Mar 13, 2024



Recent research in molecular discovery has primarily been devoted to small, drug-like molecules, leaving many similarly important applications in material design without adequate technology. These applications often rely on more complex molecular structures with fewer examples that are carefully designed using known substructures. We propose a data-efficient and interpretable model for representing and reasoning over such molecules in terms of graph grammars that explicitly describe the hierarchical design space featuring motifs to be the design basis. We present a novel representation in the form of random walks over the design space, which facilitates both molecule generation and property prediction. We demonstrate clear advantages over existing methods in terms of performance, efficiency, and synthesizability of predicted molecules, and we provide detailed insights into the method's chemical interpretability.
Boundary Exploration for Bayesian Optimization With Unknown Physical Constraints
Feb 12, 2024Bayesian optimization has been successfully applied to optimize black-box functions where the number of evaluations is severely limited. However, in many real-world applications, it is hard or impossible to know in advance which designs are feasible due to some physical or system limitations. These issues lead to an even more challenging problem of optimizing an unknown function with unknown constraints. In this paper, we observe that in such scenarios optimal solution typically lies on the boundary between feasible and infeasible regions of the design space, making it considerably more difficult than that with interior optima. Inspired by this observation, we propose BE-CBO, a new Bayesian optimization method that efficiently explores the boundary between feasible and infeasible designs. To identify the boundary, we learn the constraints with an ensemble of neural networks that outperform the standard Gaussian Processes for capturing complex boundaries. Our method demonstrates superior performance against state-of-the-art methods through comprehensive experiments on synthetic and real-world benchmarks.
DiffAvatar: Simulation-Ready Garment Optimization with Differentiable Simulation
Nov 20, 2023



The realism of digital avatars is crucial in enabling telepresence applications with self-expression and customization. A key aspect of this realism originates from the physical accuracy of both a true-to-life body shape and clothing. While physical simulations can produce high-quality, realistic motions for clothed humans, they require precise estimation of body shape and high-quality garment assets with associated physical parameters for cloth simulations. However, manually creating these assets and calibrating their parameters is labor-intensive and requires specialized expertise. To address this gap, we propose DiffAvatar, a novel approach that performs body and garment co-optimization using differentiable simulation. By integrating physical simulation into the optimization loop and accounting for the complex nonlinear behavior of cloth and its intricate interaction with the body, our framework recovers body and garment geometry and extracts important material parameters in a physically plausible way. Our experiments demonstrate that our approach generates realistic clothing and body shape that can be easily used in downstream applications.
Neural Stress Fields for Reduced-order Elastoplasticity and Fracture
Oct 26, 2023
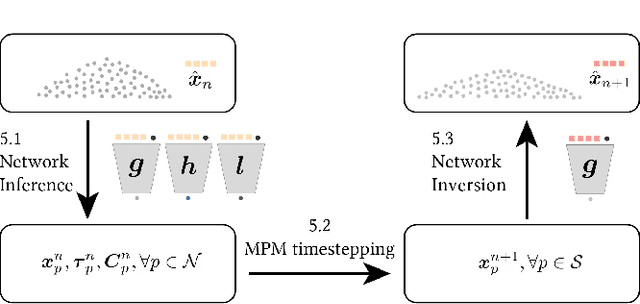
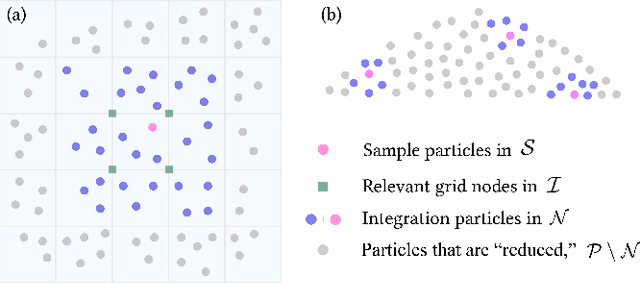

We propose a hybrid neural network and physics framework for reduced-order modeling of elastoplasticity and fracture. State-of-the-art scientific computing models like the Material Point Method (MPM) faithfully simulate large-deformation elastoplasticity and fracture mechanics. However, their long runtime and large memory consumption render them unsuitable for applications constrained by computation time and memory usage, e.g., virtual reality. To overcome these barriers, we propose a reduced-order framework. Our key innovation is training a low-dimensional manifold for the Kirchhoff stress field via an implicit neural representation. This low-dimensional neural stress field (NSF) enables efficient evaluations of stress values and, correspondingly, internal forces at arbitrary spatial locations. In addition, we also train neural deformation and affine fields to build low-dimensional manifolds for the deformation and affine momentum fields. These neural stress, deformation, and affine fields share the same low-dimensional latent space, which uniquely embeds the high-dimensional simulation state. After training, we run new simulations by evolving in this single latent space, which drastically reduces the computation time and memory consumption. Our general continuum-mechanics-based reduced-order framework is applicable to any phenomena governed by the elastodynamics equation. To showcase the versatility of our framework, we simulate a wide range of material behaviors, including elastica, sand, metal, non-Newtonian fluids, fracture, contact, and collision. We demonstrate dimension reduction by up to 100,000X and time savings by up to 10X.
ASAP: Automated Sequence Planning for Complex Robotic Assembly with Physical Feasibility
Sep 29, 2023The automated assembly of complex products requires a system that can automatically plan a physically feasible sequence of actions for assembling many parts together. In this paper, we present ASAP, a physics-based planning approach for automatically generating such a sequence for general-shaped assemblies. ASAP accounts for gravity to design a sequence where each sub-assembly is physically stable with a limited number of parts being held and a support surface. We apply efficient tree search algorithms to reduce the combinatorial complexity of determining such an assembly sequence. The search can be guided by either geometric heuristics or graph neural networks trained on data with simulation labels. Finally, we show the superior performance of ASAP at generating physically realistic assembly sequence plans on a large dataset of hundreds of complex product assemblies. We further demonstrate the applicability of ASAP on both simulation and real-world robotic setups. Project website: asap.csail.mit.edu
Hierarchical Grammar-Induced Geometry for Data-Efficient Molecular Property Prediction
Sep 04, 2023The prediction of molecular properties is a crucial task in the field of material and drug discovery. The potential benefits of using deep learning techniques are reflected in the wealth of recent literature. Still, these techniques are faced with a common challenge in practice: Labeled data are limited by the cost of manual extraction from literature and laborious experimentation. In this work, we propose a data-efficient property predictor by utilizing a learnable hierarchical molecular grammar that can generate molecules from grammar production rules. Such a grammar induces an explicit geometry of the space of molecular graphs, which provides an informative prior on molecular structural similarity. The property prediction is performed using graph neural diffusion over the grammar-induced geometry. On both small and large datasets, our evaluation shows that this approach outperforms a wide spectrum of baselines, including supervised and pre-trained graph neural networks. We include a detailed ablation study and further analysis of our solution, showing its effectiveness in cases with extremely limited data. Code is available at https://github.com/gmh14/Geo-DEG.
How Can Large Language Models Help Humans in Design and Manufacturing?
Jul 25, 2023The advancement of Large Language Models (LLMs), including GPT-4, provides exciting new opportunities for generative design. We investigate the application of this tool across the entire design and manufacturing workflow. Specifically, we scrutinize the utility of LLMs in tasks such as: converting a text-based prompt into a design specification, transforming a design into manufacturing instructions, producing a design space and design variations, computing the performance of a design, and searching for designs predicated on performance. Through a series of examples, we highlight both the benefits and the limitations of the current LLMs. By exposing these limitations, we aspire to catalyze the continued improvement and progression of these models.