 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRTQA : Recursive Thinking for Complex Temporal Knowledge Graph Question Answering with Large Language Models
Sep 04, 2025Current temporal knowledge graph question answering (TKGQA) methods primarily focus on implicit temporal constraints, lacking the capability of handling more complex temporal queries, and struggle with limited reasoning abilities and error propagation in decomposition frameworks. We propose RTQA, a novel framework to address these challenges by enhancing reasoning over TKGs without requiring training. Following recursive thinking, RTQA recursively decomposes questions into sub-problems, solves them bottom-up using LLMs and TKG knowledge, and employs multi-path answer aggregation to improve fault tolerance. RTQA consists of three core components: the Temporal Question Decomposer, the Recursive Solver, and the Answer Aggregator. Experiments on MultiTQ and TimelineKGQA benchmarks demonstrate significant Hits@1 improvements in "Multiple" and "Complex" categories, outperforming state-of-the-art methods. Our code and data are available at https://github.com/zjukg/RTQA.
Unveiling the Landscape of Clinical Depression Assessment: From Behavioral Signatures to Psychiatric Reasoning
Aug 06, 2025Depression is a widespread mental disorder that affects millions worldwide. While automated depression assessment shows promise, most studies rely on limited or non-clinically validated data, and often prioritize complex model design over real-world effectiveness. In this paper, we aim to unveil the landscape of clinical depression assessment. We introduce C-MIND, a clinical neuropsychiatric multimodal diagnosis dataset collected over two years from real hospital visits. Each participant completes three structured psychiatric tasks and receives a final diagnosis from expert clinicians, with informative audio, video, transcript, and functional near-infrared spectroscopy (fNIRS) signals recorded. Using C-MIND, we first analyze behavioral signatures relevant to diagnosis. We train a range of classical models to quantify how different tasks and modalities contribute to diagnostic performance, and dissect the effectiveness of their combinations. We then explore whether LLMs can perform psychiatric reasoning like clinicians and identify their clear limitations in realistic clinical settings. In response, we propose to guide the reasoning process with clinical expertise and consistently improves LLM diagnostic performance by up to 10% in Macro-F1 score. We aim to build an infrastructure for clinical depression assessment from both data and algorithmic perspectives, enabling C-MIND to facilitate grounded and reliable research for mental healthcare.
SKA-Bench: A Fine-Grained Benchmark for Evaluating Structured Knowledge Understanding of LLMs
Jul 23, 2025



Although large language models (LLMs) have made significant progress in understanding Structured Knowledge (SK) like KG and Table, existing evaluations for SK understanding are non-rigorous (i.e., lacking evaluations of specific capabilities) and focus on a single type of SK. Therefore, we aim to propose a more comprehensive and rigorous structured knowledge understanding benchmark to diagnose the shortcomings of LLMs. In this paper, we introduce SKA-Bench, a Structured Knowledge Augmented QA Benchmark that encompasses four widely used structured knowledge forms: KG, Table, KG+Text, and Table+Text. We utilize a three-stage pipeline to construct SKA-Bench instances, which includes a question, an answer, positive knowledge units, and noisy knowledge units. To evaluate the SK understanding capabilities of LLMs in a fine-grained manner, we expand the instances into four fundamental ability testbeds: Noise Robustness, Order Insensitivity, Information Integration, and Negative Rejection. Empirical evaluations on 8 representative LLMs, including the advanced DeepSeek-R1, indicate that existing LLMs still face significant challenges in understanding structured knowledge, and their performance is influenced by factors such as the amount of noise, the order of knowledge units, and hallucination phenomenon. Our dataset and code are available at https://github.com/Lza12a/SKA-Bench.
OneEval: Benchmarking LLM Knowledge-intensive Reasoning over Diverse Knowledge Bases
Jun 14, 2025



Large Language Models (LLMs) have demonstrated substantial progress on reasoning tasks involving unstructured text, yet their capabilities significantly deteriorate when reasoning requires integrating structured external knowledge such as knowledge graphs, code snippets, or formal logic. This limitation is partly due to the absence of benchmarks capable of systematically evaluating LLM performance across diverse structured knowledge modalities. To address this gap, we introduce \textbf{\textsc{OneEval}}, a comprehensive benchmark explicitly designed to assess the knowledge-intensive reasoning capabilities of LLMs across four structured knowledge modalities, unstructured text, knowledge graphs, code, and formal logic, and five critical domains (general knowledge, government, science, law, and programming). \textsc{OneEval} comprises 4,019 carefully curated instances and includes a challenging subset, \textsc{OneEval}\textsubscript{Hard}, consisting of 1,285 particularly difficult cases. Through extensive evaluation of 18 state-of-the-art open-source and proprietary LLMs, we establish three core findings: a) \emph{persistent limitations in structured reasoning}, with even the strongest model achieving only 32.2\% accuracy on \textsc{OneEval}\textsubscript{Hard}; b) \emph{performance consistently declines as the structural complexity of the knowledge base increases}, with accuracy dropping sharply from 53\% (textual reasoning) to 25\% (formal logic); and c) \emph{diminishing returns from extended reasoning chains}, highlighting the critical need for models to adapt reasoning depth appropriately to task complexity. We release the \textsc{OneEval} datasets, evaluation scripts, and baseline results publicly, accompanied by a leaderboard to facilitate ongoing advancements in structured knowledge reasoning.
Beyond Completion: A Foundation Model for General Knowledge Graph Reasoning
May 28, 2025In natural language processing (NLP) and computer vision (CV), the successful application of foundation models across diverse tasks has demonstrated their remarkable potential. However, despite the rich structural and textual information embedded in knowledge graphs (KGs), existing research of foundation model for KG has primarily focused on their structural aspects, with most efforts restricted to in-KG tasks (e.g., knowledge graph completion, KGC). This limitation has hindered progress in addressing more challenging out-of-KG tasks. In this paper, we introduce MERRY, a foundation model for general knowledge graph reasoning, and investigate its performance across two task categories: in-KG reasoning tasks (e.g., KGC) and out-of-KG tasks (e.g., KG question answering, KGQA). We not only utilize the structural information, but also the textual information in KGs. Specifically, we propose a multi-perspective Conditional Message Passing (CMP) encoding architecture to bridge the gap between textual and structural modalities, enabling their seamless integration. Additionally, we introduce a dynamic residual fusion module to selectively retain relevant textual information and a flexible edge scoring mechanism to adapt to diverse downstream tasks. Comprehensive evaluations on 28 datasets demonstrate that MERRY outperforms existing baselines in most scenarios, showcasing strong reasoning capabilities within KGs and excellent generalization to out-of-KG tasks such as KGQA.
SciCUEval: A Comprehensive Dataset for Evaluating Scientific Context Understanding in Large Language Models
May 21, 2025


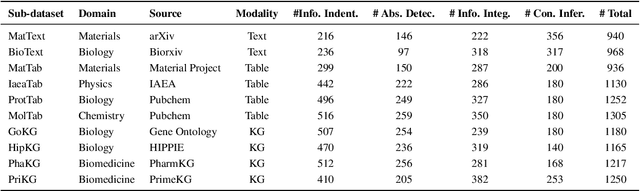
Large Language Models (LLMs) have shown impressive capabilities in contextual understanding and reasoning. However, evaluating their performance across diverse scientific domains remains underexplored, as existing benchmarks primarily focus on general domains and fail to capture the intricate complexity of scientific data. To bridge this gap, we construct SciCUEval, a comprehensive benchmark dataset tailored to assess the scientific context understanding capability of LLMs. It comprises ten domain-specific sub-datasets spanning biology, chemistry, physics, biomedicine, and materials science, integrating diverse data modalities including structured tables, knowledge graphs, and unstructured texts. SciCUEval systematically evaluates four core competencies: Relevant information identification, Information-absence detection, Multi-source information integration, and Context-aware inference, through a variety of question formats. We conduct extensive evaluations of state-of-the-art LLMs on SciCUEval, providing a fine-grained analysis of their strengths and limitations in scientific context understanding, and offering valuable insights for the future development of scientific-domain LLMs.
MAGI: Multi-Agent Guided Interview for Psychiatric Assessment
Apr 25, 2025Automating structured clinical interviews could revolutionize mental healthcare accessibility, yet existing large language models (LLMs) approaches fail to align with psychiatric diagnostic protocols. We present MAGI, the first framework that transforms the gold-standard Mini International Neuropsychiatric Interview (MINI) into automatic computational workflows through coordinated multi-agent collaboration. MAGI dynamically navigates clinical logic via four specialized agents: 1) an interview tree guided navigation agent adhering to the MINI's branching structure, 2) an adaptive question agent blending diagnostic probing, explaining, and empathy, 3) a judgment agent validating whether the response from participants meet the node, and 4) a diagnosis Agent generating Psychometric Chain-of- Thought (PsyCoT) traces that explicitly map symptoms to clinical criteria. Experimental results on 1,002 real-world participants covering depression, generalized anxiety, social anxiety and suicide shows that MAGI advances LLM- assisted mental health assessment by combining clinical rigor, conversational adaptability, and explainable reasoning.
Multi-modal Knowledge Graph Generation with Semantics-enriched Prompts
Apr 18, 2025



Multi-modal Knowledge Graphs (MMKGs) have been widely applied across various domains for knowledge representation. However, the existing MMKGs are significantly fewer than required, and their construction faces numerous challenges, particularly in ensuring the selection of high-quality, contextually relevant images for knowledge graph enrichment. To address these challenges, we present a framework for constructing MMKGs from conventional KGs. Furthermore, to generate higher-quality images that are more relevant to the context in the given knowledge graph, we designed a neighbor selection method called Visualizable Structural Neighbor Selection (VSNS). This method consists of two modules: Visualizable Neighbor Selection (VNS) and Structural Neighbor Selection (SNS). The VNS module filters relations that are difficult to visualize, while the SNS module selects neighbors that most effectively capture the structural characteristics of the entity. To evaluate the quality of the generated images, we performed qualitative and quantitative evaluations on two datasets, MKG-Y and DB15K. The experimental results indicate that using the VSNS method to select neighbors results in higher-quality images that are more relevant to the knowledge graph.
ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning
Mar 27, 2025



Large Language Models (LLMs) have shown remarkable capabilities in reasoning, exemplified by the success of OpenAI-o1 and DeepSeek-R1. However, integrating reasoning with external search processes remains challenging, especially for complex multi-hop questions requiring multiple retrieval steps. We propose ReSearch, a novel framework that trains LLMs to Reason with Search via reinforcement learning without using any supervised data on reasoning steps. Our approach treats search operations as integral components of the reasoning chain, where when and how to perform searches is guided by text-based thinking, and search results subsequently influence further reasoning. We train ReSearch on Qwen2.5-7B(-Instruct) and Qwen2.5-32B(-Instruct) models and conduct extensive experiments. Despite being trained on only one dataset, our models demonstrate strong generalizability across various benchmarks. Analysis reveals that ReSearch naturally elicits advanced reasoning capabilities such as reflection and self-correction during the reinforcement learning process.
From Fragment to One Piece: A Survey on AI-Driven Graphic Design
Mar 24, 2025This survey provides a comprehensive overview of the advancements in Artificial Intelligence in Graphic Design (AIGD), focusing on integrating AI techniques to support design interpretation and enhance the creative process. We categorize the field into two primary directions: perception tasks, which involve understanding and analyzing design elements, and generation tasks, which focus on creating new design elements and layouts. The survey covers various subtasks, including visual element perception and generation, aesthetic and semantic understanding, layout analysis, and generation. We highlight the role of large language models and multimodal approaches in bridging the gap between localized visual features and global design intent. Despite significant progress, challenges remain to understanding human intent, ensuring interpretability, and maintaining control over multilayered compositions. This survey serves as a guide for researchers, providing information on the current state of AIGD and potential future directions\footnote{https://github.com/zhangtianer521/excellent\_Intelligent\_graphic\_design}.