 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKairosAgent: Agentic Time Series Forecasting with Fused Semantic Reasoning
May 28, 2026Cross-domain multimodal time series forecasting is a challenging task, requiring models to integrate precise numerical comprehension, cross-domain semantic understanding, and effective multimodal fusion. Existing approaches either build Time Series Foundation Models (TSFMs) from scratch or leverage pretrained Large Language Models (LLMs). However, TSFMs often overlook semantic understanding and lack the ability to perform future-oriented semantic reasoning, and LLMs struggle with numerical comprehension and accurate quantitative forecasting. To overcome these limitations, we propose KairosAgent, a novel agentic framework for multimodal time series forecasting, including an LLM-based reasoner and a TSFM-based forecaster. KairosAgent unifies textual reasoning and numerical forecasting by dynamically invoking analytical tools to enhance the numerical understanding and semantic reasoning capabilities of LLMs. The reasoning results are subsequently fused into the TSFM pipeline, enabling more accurate and reliable future predictions. To further improve the reasoning, we curate a large-scale corpus of high-quality trajectories, alongside a reinforcement learning from forecasting paradigm with multi-turn refinement and turn-level credit assignment. Experiments demonstrate that KairosAgent achieves superior zero-shot forecasting performance while maximizing the utility of pretrained LLMs and TSFMs, presenting a promising direction for efficient and interpretable time series agents. The project page is at https://foundation-model-research.github.io/KairosAgent .
BagelVLA: Enhancing Long-Horizon Manipulation via Interleaved Vision-Language-Action Generation
Feb 11, 2026Equipping embodied agents with the ability to reason about tasks, foresee physical outcomes, and generate precise actions is essential for general-purpose manipulation. While recent Vision-Language-Action (VLA) models have leveraged pre-trained foundation models, they typically focus on either linguistic planning or visual forecasting in isolation. These methods rarely integrate both capabilities simultaneously to guide action generation, leading to suboptimal performance in complex, long-horizon manipulation tasks. To bridge this gap, we propose BagelVLA, a unified model that integrates linguistic planning, visual forecasting, and action generation within a single framework. Initialized from a pretrained unified understanding and generative model, BagelVLA is trained to interleave textual reasoning and visual prediction directly into the action execution loop. To efficiently couple these modalities, we introduce Residual Flow Guidance (RFG), which initializes from current observation and leverages single-step denoising to extract predictive visual features, guiding action generation with minimal latency. Extensive experiments demonstrate that BagelVLA outperforms existing baselines by a significant margin on multiple simulated and real-world benchmarks, particularly in tasks requiring multi-stage reasoning.
Unveiling the Landscape of Clinical Depression Assessment: From Behavioral Signatures to Psychiatric Reasoning
Aug 06, 2025Depression is a widespread mental disorder that affects millions worldwide. While automated depression assessment shows promise, most studies rely on limited or non-clinically validated data, and often prioritize complex model design over real-world effectiveness. In this paper, we aim to unveil the landscape of clinical depression assessment. We introduce C-MIND, a clinical neuropsychiatric multimodal diagnosis dataset collected over two years from real hospital visits. Each participant completes three structured psychiatric tasks and receives a final diagnosis from expert clinicians, with informative audio, video, transcript, and functional near-infrared spectroscopy (fNIRS) signals recorded. Using C-MIND, we first analyze behavioral signatures relevant to diagnosis. We train a range of classical models to quantify how different tasks and modalities contribute to diagnostic performance, and dissect the effectiveness of their combinations. We then explore whether LLMs can perform psychiatric reasoning like clinicians and identify their clear limitations in realistic clinical settings. In response, we propose to guide the reasoning process with clinical expertise and consistently improves LLM diagnostic performance by up to 10% in Macro-F1 score. We aim to build an infrastructure for clinical depression assessment from both data and algorithmic perspectives, enabling C-MIND to facilitate grounded and reliable research for mental healthcare.
Full Encoder: Make Autoencoders Learn Like PCA
Mar 25, 2021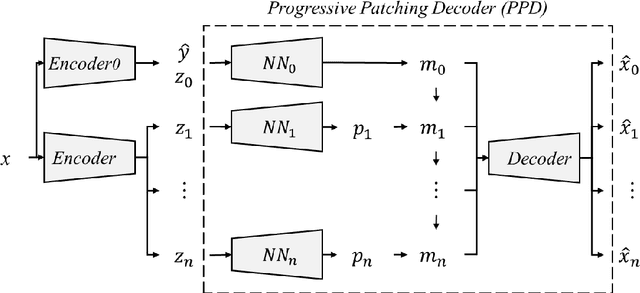

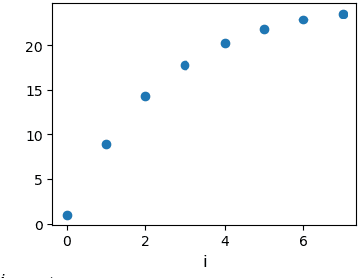
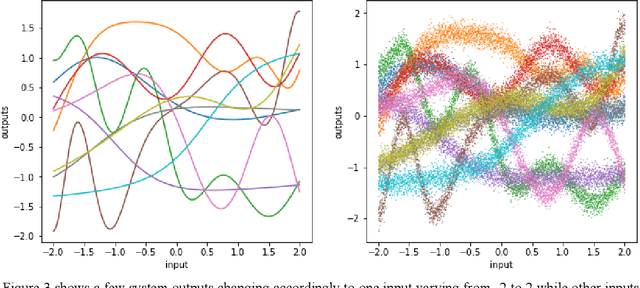
While the beta-VAE family is aiming to find disentangled representations and acquire human-interpretable generative factors, like what an ICA does in the linear domain, we propose Full Encoder: a novel unified autoencoder framework as a correspondence to PCA in the non-linear domain. The idea is to train an autoencoder with one latent variable first, then involve more latent variables progressively to refine the reconstruction results. The latent variables acquired with Full Encoder is stable and robust, as they always learn the same representation regardless the network initial states. Full Encoder can be used to determine the degrees of freedom in a non-linear system, and is useful for data compression or anomaly detection. Full Encoder can also be combined with beta-VAE framework to sort out the importance of the generative factors, providing more insights for non-linear system analysis. We created a toy dataset with a non-linear system to test the Full Encoder and compare its results to VAE and beta-VAE's results.