 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCREATE: A Benchmark for Chinese Short Video Retrieval and Title Generation
Mar 31, 2022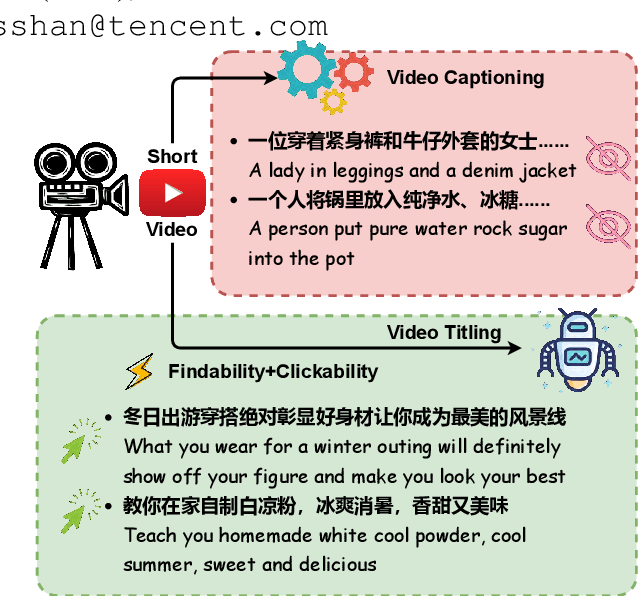
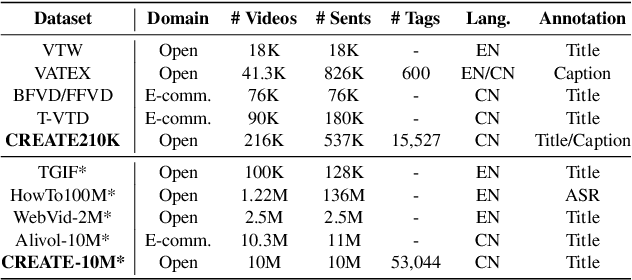

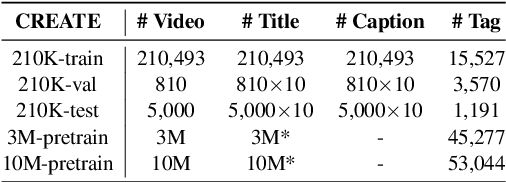
Previous works of video captioning aim to objectively describe the video's actual content, which lacks subjective and attractive expression, limiting its practical application scenarios. Video titling is intended to achieve this goal, but there is a lack of a proper benchmark. In this paper, we propose to CREATE, the first large-scale Chinese shoRt vidEo retrievAl and Title gEneration benchmark, to facilitate research and application in video titling and video retrieval in Chinese. CREATE consists of a high-quality labeled 210K dataset and two large-scale 3M/10M pre-training datasets, covering 51 categories, 50K+ tags, 537K manually annotated titles and captions, and 10M+ short videos. Based on CREATE, we propose a novel model ALWIG which combines video retrieval and video titling tasks to achieve the purpose of multi-modal ALignment WIth Generation with the help of video tags and a GPT pre-trained model. CREATE opens new directions for facilitating future research and applications on video titling and video retrieval in the field of Chinese short videos.
Open-Vocabulary One-Stage Detection with Hierarchical Visual-Language Knowledge Distillation
Mar 20, 2022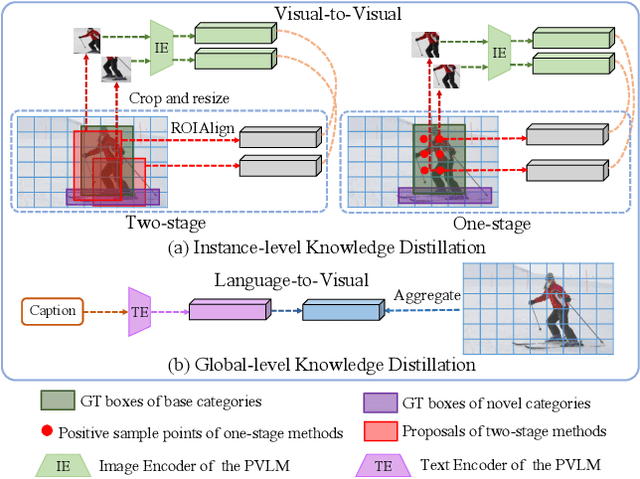
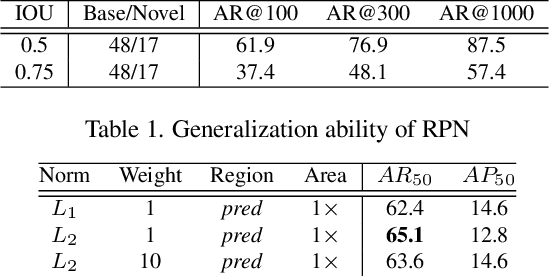
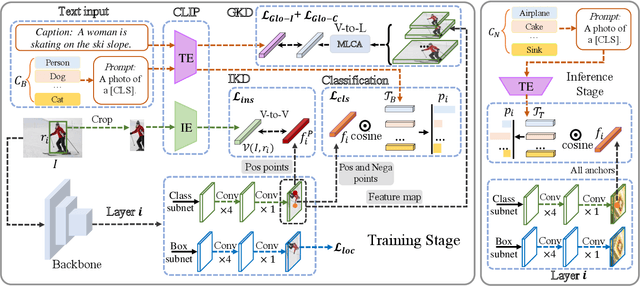
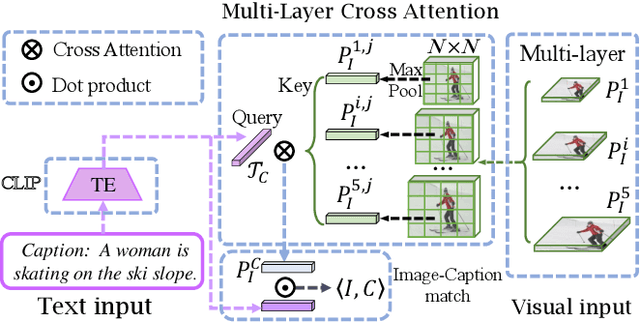
Open-vocabulary object detection aims to detect novel object categories beyond the training set. The advanced open-vocabulary two-stage detectors employ instance-level visual-to-visual knowledge distillation to align the visual space of the detector with the semantic space of the Pre-trained Visual-Language Model (PVLM). However, in the more efficient one-stage detector, the absence of class-agnostic object proposals hinders the knowledge distillation on unseen objects, leading to severe performance degradation. In this paper, we propose a hierarchical visual-language knowledge distillation method, i.e., HierKD, for open-vocabulary one-stage detection. Specifically, a global-level knowledge distillation is explored to transfer the knowledge of unseen categories from the PVLM to the detector. Moreover, we combine the proposed global-level knowledge distillation and the common instance-level knowledge distillation to learn the knowledge of seen and unseen categories simultaneously. Extensive experiments on MS-COCO show that our method significantly surpasses the previous best one-stage detector with 11.9\% and 6.7\% $AP_{50}$ gains under the zero-shot detection and generalized zero-shot detection settings, and reduces the $AP_{50}$ performance gap from 14\% to 7.3\% compared to the best two-stage detector.
EBHI:A New Enteroscope Biopsy Histopathological H&E Image Dataset for Image Classification Evaluation
Feb 17, 2022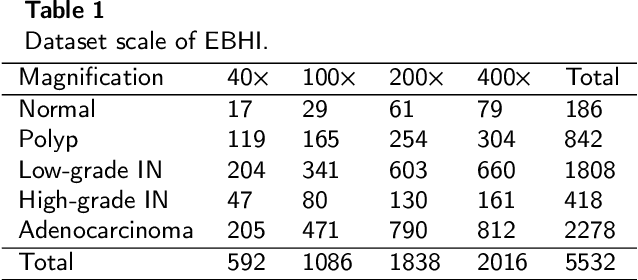
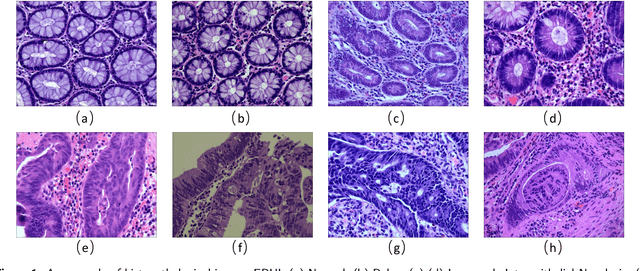
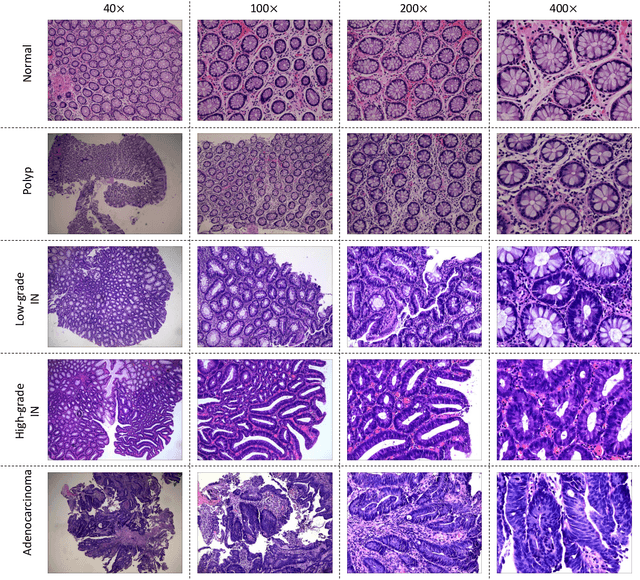
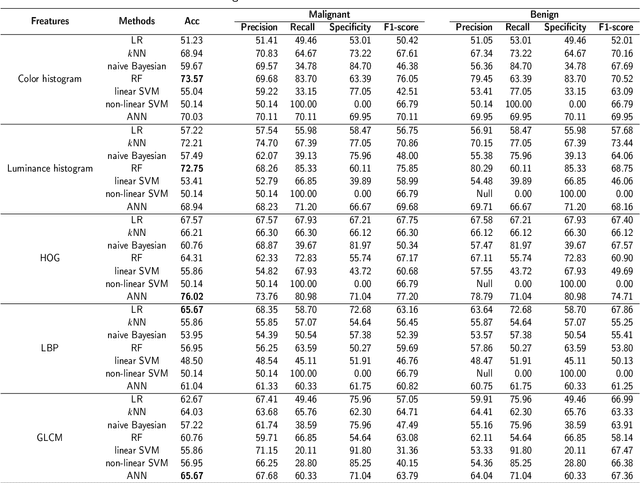
Background and purpose: Colorectal cancer has become the third most common cancer worldwide, accounting for approximately 10% of cancer patients. Early detection of the disease is important for the treatment of colorectal cancer patients. Histopathological examination is the gold standard for screening colorectal cancer. However, the current lack of histopathological image datasets of colorectal cancer, especially enteroscope biopsies, hinders the accurate evaluation of computer-aided diagnosis techniques. Methods: A new publicly available Enteroscope Biopsy Histopathological H&E Image Dataset (EBHI) is published in this paper. To demonstrate the effectiveness of the EBHI dataset, we have utilized several machine learning, convolutional neural networks and novel transformer-based classifiers for experimentation and evaluation, using an image with a magnification of 200x. Results: Experimental results show that the deep learning method performs well on the EBHI dataset. Traditional machine learning methods achieve maximum accuracy of 76.02% and deep learning method achieves a maximum accuracy of 95.37%. Conclusion: To the best of our knowledge, EBHI is the first publicly available colorectal histopathology enteroscope biopsy dataset with four magnifications and five types of images of tumor differentiation stages, totaling 5532 images. We believe that EBHI could attract researchers to explore new classification algorithms for the automated diagnosis of colorectal cancer, which could help physicians and patients in clinical settings.
Learning Target-aware Representation for Visual Tracking via Informative Interactions
Jan 07, 2022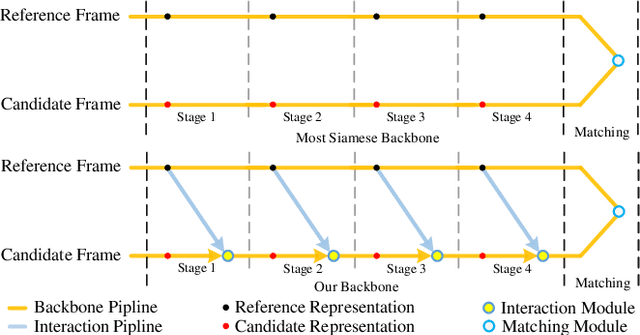
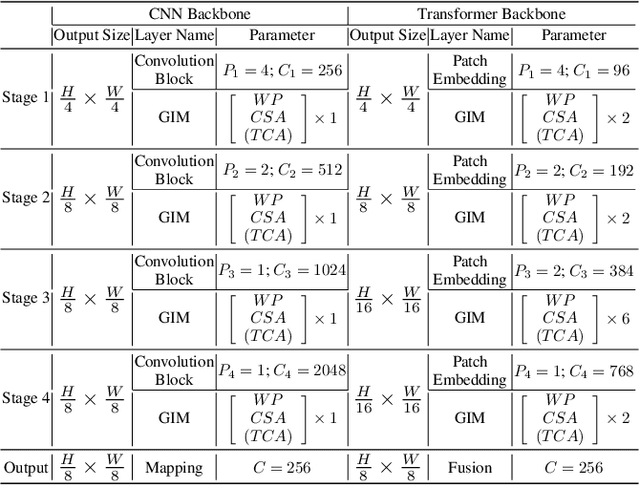
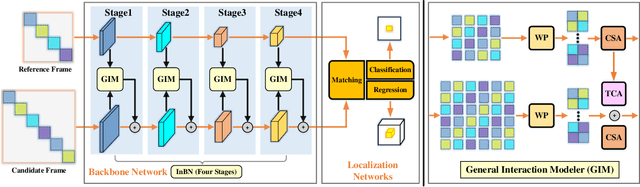
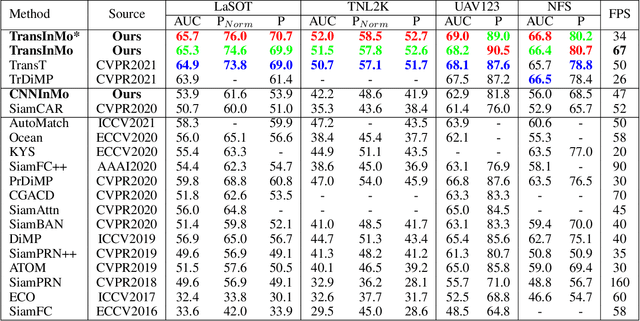
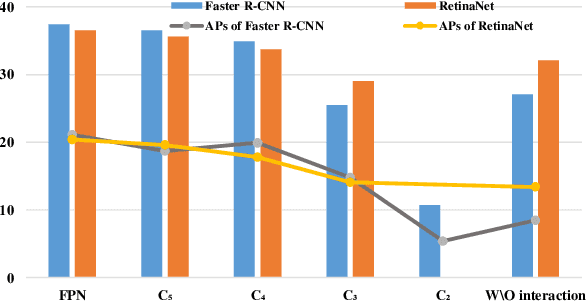
We introduce a novel backbone architecture to improve target-perception ability of feature representation for tracking. Specifically, having observed that de facto frameworks perform feature matching simply using the outputs from backbone for target localization, there is no direct feedback from the matching module to the backbone network, especially the shallow layers. More concretely, only the matching module can directly access the target information (in the reference frame), while the representation learning of candidate frame is blind to the reference target. As a consequence, the accumulation effect of target-irrelevant interference in the shallow stages may degrade the feature quality of deeper layers. In this paper, we approach the problem from a different angle by conducting multiple branch-wise interactions inside the Siamese-like backbone networks (InBN). At the core of InBN is a general interaction modeler (GIM) that injects the prior knowledge of reference image to different stages of the backbone network, leading to better target-perception and robust distractor-resistance of candidate feature representation with negligible computation cost. The proposed GIM module and InBN mechanism are general and applicable to different backbone types including CNN and Transformer for improvements, as evidenced by our extensive experiments on multiple benchmarks. In particular, the CNN version (based on SiamCAR) improves the baseline with 3.2/6.9 absolute gains of SUC on LaSOT/TNL2K, respectively. The Transformer version obtains SUC scores of 65.7/52.0 on LaSOT/TNL2K, which are on par with recent state of the arts. Code and models will be released.
Recursive Least-Squares Estimator-Aided Online Learning for Visual Tracking
Dec 28, 2021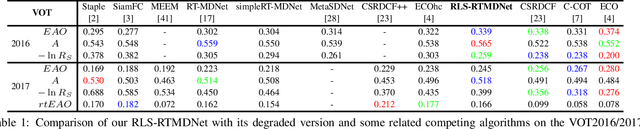
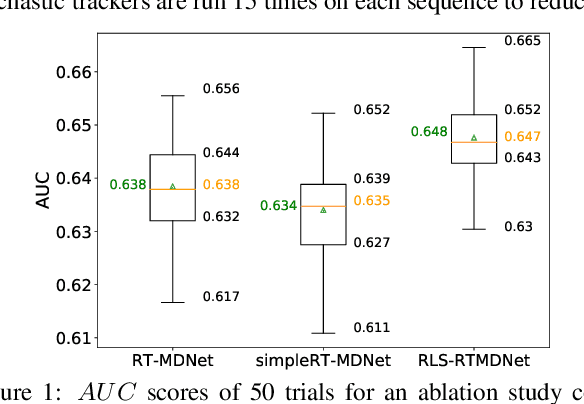
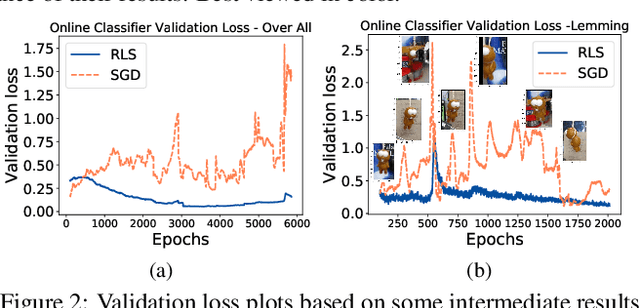
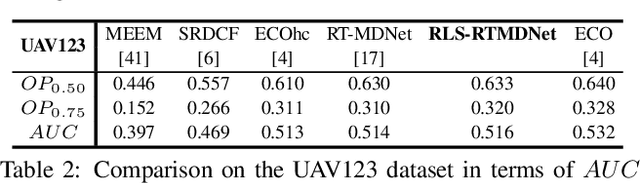
Tracking visual objects from a single initial exemplar in the testing phase has been broadly cast as a one-/few-shot problem, i.e., one-shot learning for initial adaptation and few-shot learning for online adaptation. The recent few-shot online adaptation methods incorporate the prior knowledge from large amounts of annotated training data via complex meta-learning optimization in the offline phase. This helps the online deep trackers to achieve fast adaptation and reduce overfitting risk in tracking. In this paper, we propose a simple yet effective recursive least-squares estimator-aided online learning approach for few-shot online adaptation without requiring offline training. It allows an in-built memory retention mechanism for the model to remember the knowledge about the object seen before, and thus the seen data can be safely removed from training. This also bears certain similarities to the emerging continual learning field in preventing catastrophic forgetting. This mechanism enables us to unveil the power of modern online deep trackers without incurring too much extra computational cost. We evaluate our approach based on two networks in the online learning families for tracking, i.e., multi-layer perceptrons in RT-MDNet and convolutional neural networks in DiMP. The consistent improvements on several challenging tracking benchmarks demonstrate its effectiveness and efficiency.
EMScore: Evaluating Video Captioning via Coarse-Grained and Fine-Grained Embedding Matching
Nov 17, 2021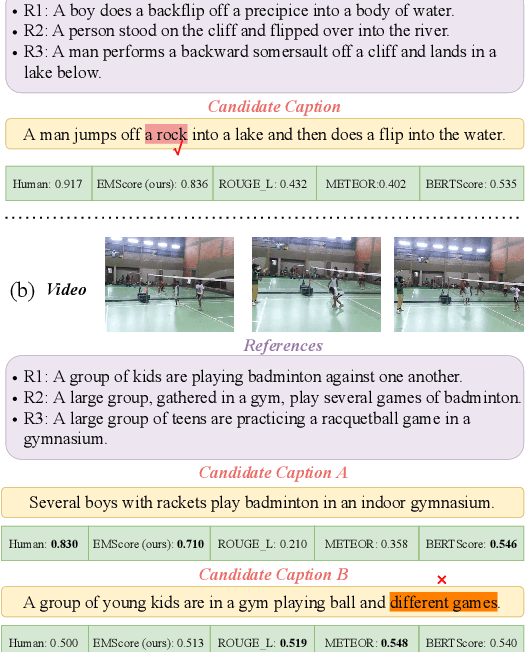
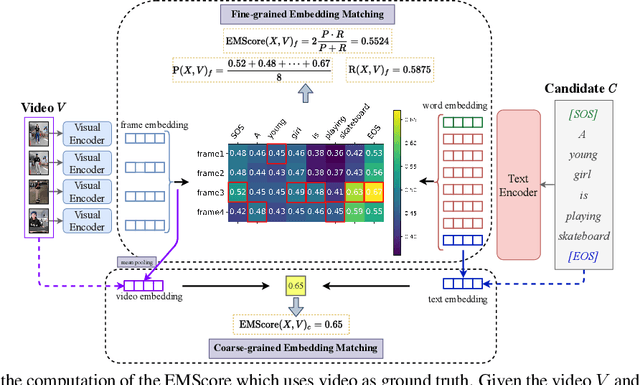
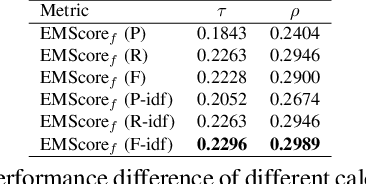

Current metrics for video captioning are mostly based on the text-level comparison between reference and candidate captions. However, they have some insuperable drawbacks, e.g., they cannot handle videos without references, and they may result in biased evaluation due to the one-to-many nature of video-to-text and the neglect of visual relevance. From the human evaluator's viewpoint, a high-quality caption should be consistent with the provided video, but not necessarily be similar to the reference in literal or semantics. Inspired by human evaluation, we propose EMScore (Embedding Matching-based score), a novel reference-free metric for video captioning, which directly measures similarity between video and candidate captions. Benefit from the recent development of large-scale pre-training models, we exploit a well pre-trained vision-language model to extract visual and linguistic embeddings for computing EMScore. Specifically, EMScore combines matching scores of both coarse-grained (video and caption) and fine-grained (frames and words) levels, which takes the overall understanding and detailed characteristics of the video into account. Furthermore, considering the potential information gain, EMScore can be flexibly extended to the conditions where human-labeled references are available. Last but not least, we collect VATEX-EVAL and ActivityNet-FOIl datasets to systematically evaluate the existing metrics. VATEX-EVAL experiments demonstrate that EMScore has higher human correlation and lower reference dependency. ActivityNet-FOIL experiment verifies that EMScore can effectively identify "hallucinating" captions. The datasets will be released to facilitate the development of video captioning metrics. The code is available at: https://github.com/ShiYaya/emscore.
Joint Learning of Visual-Audio Saliency Prediction and Sound Source Localization on Multi-face Videos
Nov 05, 2021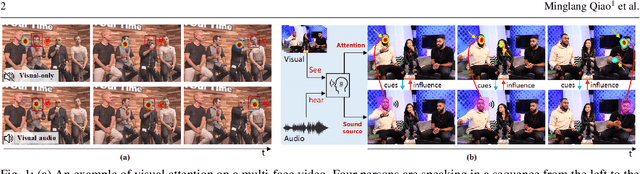
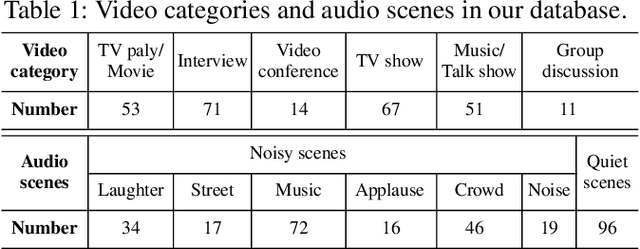

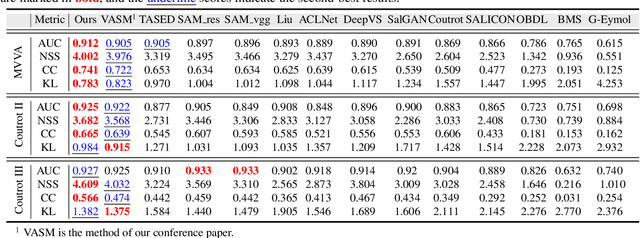
Visual and audio events simultaneously occur and both attract attention. However, most existing saliency prediction works ignore the influence of audio and only consider vision modality. In this paper, we propose a multitask learning method for visual-audio saliency prediction and sound source localization on multi-face video by leveraging visual, audio and face information. Specifically, we first introduce a large-scale database of multi-face video in visual-audio condition (MVVA), containing eye-tracking data and sound source annotations. Using this database, we find that sound influences human attention, and conversly attention offers a cue to determine sound source on multi-face video. Guided by these findings, a visual-audio multi-task network (VAM-Net) is introduced to predict saliency and locate sound source. VAM-Net consists of three branches corresponding to visual, audio and face modalities. Visual branch has a two-stream architecture to capture spatial and temporal information. Face and audio branches encode audio signals and faces, respectively. Finally, a spatio-temporal multi-modal graph (STMG) is constructed to model the interaction among multiple faces. With joint optimization of these branches, the intrinsic correlation of the tasks of saliency prediction and sound source localization is utilized and their performance is boosted by each other. Experiments show that the proposed method outperforms 12 state-of-the-art saliency prediction methods, and achieves competitive results in sound source localization.
SDTP: Semantic-aware Decoupled Transformer Pyramid for Dense Image Prediction
Sep 18, 2021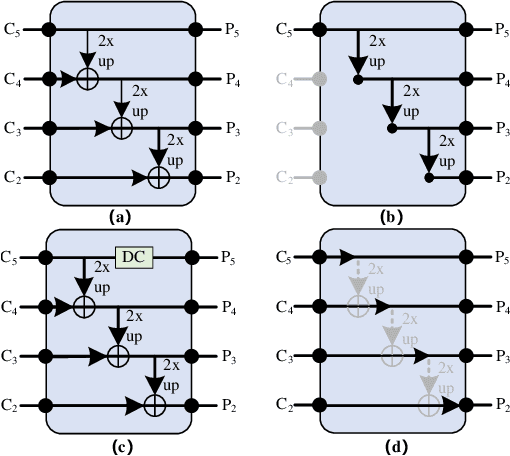
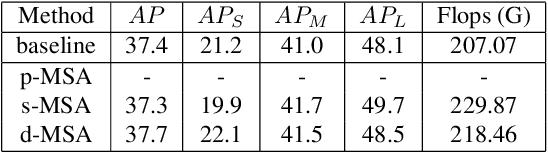
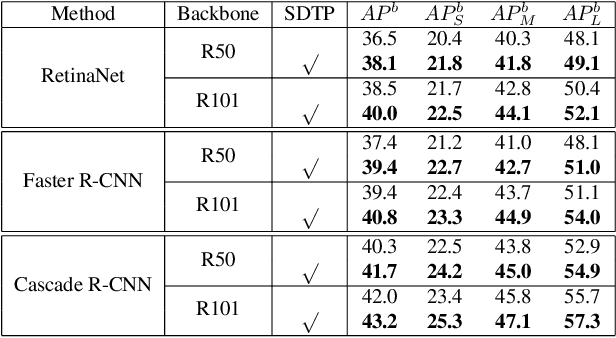
Although transformer has achieved great progress on computer vision tasks, the scale variation in dense image prediction is still the key challenge. Few effective multi-scale techniques are applied in transformer and there are two main limitations in the current methods. On one hand, self-attention module in vanilla transformer fails to sufficiently exploit the diversity of semantic information because of its rigid mechanism. On the other hand, it is hard to build attention and interaction among different levels due to the heavy computational burden. To alleviate this problem, we first revisit multi-scale problem in dense prediction, verifying the significance of diverse semantic representation and multi-scale interaction, and exploring the adaptation of transformer to pyramidal structure. Inspired by these findings, we propose a novel Semantic-aware Decoupled Transformer Pyramid (SDTP) for dense image prediction, consisting of Intra-level Semantic Promotion (ISP), Cross-level Decoupled Interaction (CDI) and Attention Refinement Function (ARF). ISP explores the semantic diversity in different receptive space. CDI builds the global attention and interaction among different levels in decoupled space which also solves the problem of heavy computation. Besides, ARF is further added to refine the attention in transformer. Experimental results demonstrate the validity and generality of the proposed method, which outperforms the state-of-the-art by a significant margin in dense image prediction tasks. Furthermore, the proposed components are all plug-and-play, which can be embedded in other methods.
Differentiable Convolution Search for Point Cloud Processing
Aug 29, 2021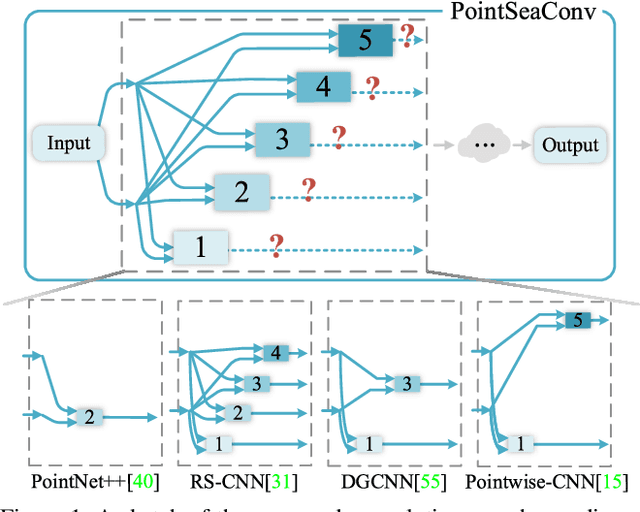

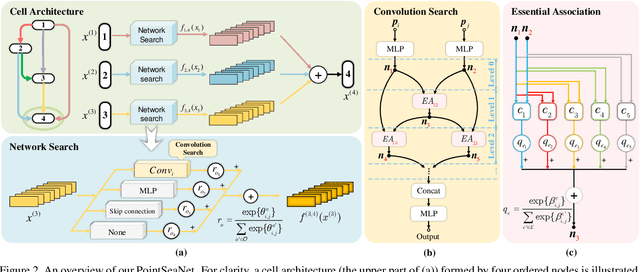

Exploiting convolutional neural networks for point cloud processing is quite challenging, due to the inherent irregular distribution and discrete shape representation of point clouds. To address these problems, many handcrafted convolution variants have sprung up in recent years. Though with elaborate design, these variants could be far from optimal in sufficiently capturing diverse shapes formed by discrete points. In this paper, we propose PointSeaConv, i.e., a novel differential convolution search paradigm on point clouds. It can work in a purely data-driven manner and thus is capable of auto-creating a group of suitable convolutions for geometric shape modeling. We also propose a joint optimization framework for simultaneous search of internal convolution and external architecture, and introduce epsilon-greedy algorithm to alleviate the effect of discretization error. As a result, PointSeaNet, a deep network that is sufficient to capture geometric shapes at both convolution level and architecture level, can be searched out for point cloud processing. Extensive experiments strongly evidence that our proposed PointSeaNet surpasses current handcrafted deep models on challenging benchmarks across multiple tasks with remarkable margins.
Channel-wise Topology Refinement Graph Convolution for Skeleton-Based Action Recognition
Aug 23, 2021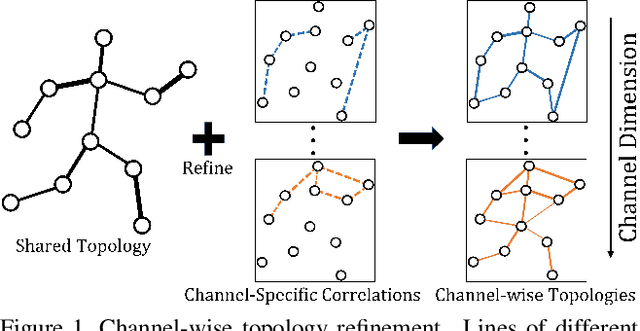
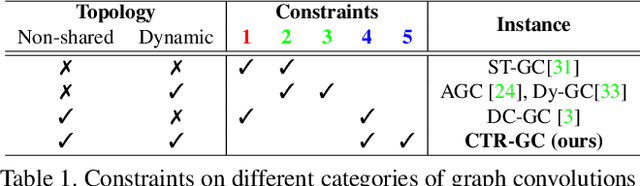
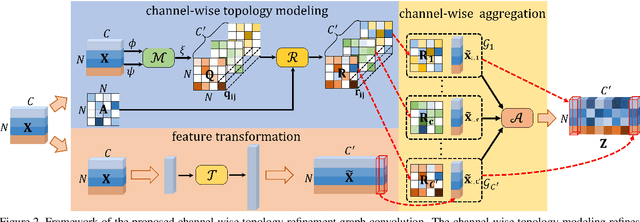
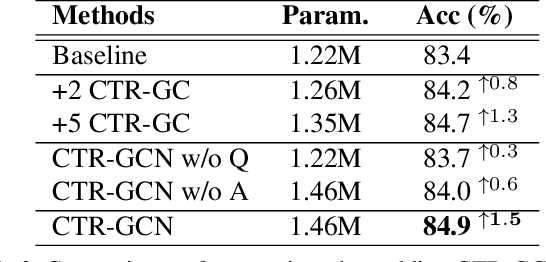
Graph convolutional networks (GCNs) have been widely used and achieved remarkable results in skeleton-based action recognition. In GCNs, graph topology dominates feature aggregation and therefore is the key to extracting representative features. In this work, we propose a novel Channel-wise Topology Refinement Graph Convolution (CTR-GC) to dynamically learn different topologies and effectively aggregate joint features in different channels for skeleton-based action recognition. The proposed CTR-GC models channel-wise topologies through learning a shared topology as a generic prior for all channels and refining it with channel-specific correlations for each channel. Our refinement method introduces few extra parameters and significantly reduces the difficulty of modeling channel-wise topologies. Furthermore, via reformulating graph convolutions into a unified form, we find that CTR-GC relaxes strict constraints of graph convolutions, leading to stronger representation capability. Combining CTR-GC with temporal modeling modules, we develop a powerful graph convolutional network named CTR-GCN which notably outperforms state-of-the-art methods on the NTU RGB+D, NTU RGB+D 120, and NW-UCLA datasets.