 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAVA: Retrieval-Augmented Viewpoint Alignment for Subject-Driven Image Generation
Jun 16, 2026Reference-driven image generation has made rapid progress on identity preservation, but reliable viewpoint control across different subjects remains poorly understood. The difficulty is not merely generating a new image of the target subject: the model must infer the implicit viewpoint of one subject and transfer it to another subject using only image-level evidence, without camera poses, depth, or ray-based conditions. In this setting, existing generators conditioned on multiple image references often rely on spurious semantic correlations, which lead to viewpoint drift, part-level structural mismatches, and missing or unsupported target-specific content. We formulate this challenge as cross-subject viewpoint alignment and propose RAVA, a retrieval-augmented framework that supplies explicit geometric evidence before generation. RAVA first learns a cross-instance viewpoint embedding that retrieves target-subject images aligned with the anchor viewpoint, then applies a LogDet-based subset selection strategy to retain a compact reference set that is both view-consistent and structurally complementary. The selected references are finally consumed by a fine-tuned multi-reference image generator. Experiments show that generic semantic embeddings are nearly random for this task, while the proposed retriever substantially improves viewpoint retrieval quality. On cross-subject generation, RAVA consistently outperforms zero-shot baselines and stronger retrieval alternatives under the same generation backbone. These results indicate that cross-subject viewpoint alignment benefits from retrieval-augmented geometric grounding rather than relying on end-to-end generation alone.
F2RVLM: Boosting Fine-grained Fragment Retrieval for Multi-Modal Long-form Dialogue with Vision Language Model
Aug 25, 2025Traditional dialogue retrieval aims to select the most appropriate utterance or image from recent dialogue history. However, they often fail to meet users' actual needs for revisiting semantically coherent content scattered across long-form conversations. To fill this gap, we define the Fine-grained Fragment Retrieval (FFR) task, requiring models to locate query-relevant fragments, comprising both utterances and images, from multimodal long-form dialogues. As a foundation for FFR, we construct MLDR, the longest-turn multimodal dialogue retrieval dataset to date, averaging 25.45 turns per dialogue, with each naturally spanning three distinct topics. To evaluate generalization in real-world scenarios, we curate and annotate a WeChat-based test set comprising real-world multimodal dialogues with an average of 75.38 turns. Building on these resources, we explore existing generation-based Vision-Language Models (VLMs) on FFR and observe that they often retrieve incoherent utterance-image fragments. While optimized for generating responses from visual-textual inputs, these models lack explicit supervision to ensure semantic coherence within retrieved fragments. To this end, we propose F2RVLM, a generative retrieval model trained in a two-stage paradigm: (1) supervised fine-tuning to inject fragment-level retrieval knowledge, and (2) GRPO-based reinforcement learning with multi-objective rewards promoting semantic precision, relevance, and contextual coherence. To handle varying intra-fragment complexity, from locally dense to sparsely distributed, we introduce difficulty-aware curriculum sampling that ranks training instances by model-predicted difficulty and gradually exposes the model to harder samples. This boosts reasoning ability in long, multi-turn contexts. F2RVLM outperforms popular VLMs in both in-domain and real-domain settings, demonstrating superior retrieval performance.
Mobius: A High Efficient Spatial-Temporal Parallel Training Paradigm for Text-to-Video Generation Task
Jul 12, 2024



Inspired by the success of the text-to-image (T2I) generation task, many researchers are devoting themselves to the text-to-video (T2V) generation task. Most of the T2V frameworks usually inherit from the T2I model and add extra-temporal layers of training to generate dynamic videos, which can be viewed as a fine-tuning task. However, the traditional 3D-Unet is a serial mode and the temporal layers follow the spatial layers, which will result in high GPU memory and training time consumption according to its serial feature flow. We believe that this serial mode will bring more training costs with the large diffusion model and massive datasets, which are not environmentally friendly and not suitable for the development of the T2V. Therefore, we propose a highly efficient spatial-temporal parallel training paradigm for T2V tasks, named Mobius. In our 3D-Unet, the temporal layers and spatial layers are parallel, which optimizes the feature flow and backpropagation. The Mobius will save 24% GPU memory and 12% training time, which can greatly improve the T2V fine-tuning task and provide a novel insight for the AIGC community. We will release our codes in the future.
Mobius: An High Efficient Spatial-Temporal Parallel Training Paradigm for Text-to-Video Generation Task
Jul 09, 2024Inspired by the success of the text-to-image (T2I) generation task, many researchers are devoting themselves to the text-to-video (T2V) generation task. Most of the T2V frameworks usually inherit from the T2I model and add extra-temporal layers of training to generate dynamic videos, which can be viewed as a fine-tuning task. However, the traditional 3D-Unet is a serial mode and the temporal layers follow the spatial layers, which will result in high GPU memory and training time consumption according to its serial feature flow. We believe that this serial mode will bring more training costs with the large diffusion model and massive datasets, which are not environmentally friendly and not suitable for the development of the T2V. Therefore, we propose a highly efficient spatial-temporal parallel training paradigm for T2V tasks, named Mobius. In our 3D-Unet, the temporal layers and spatial layers are parallel, which optimizes the feature flow and backpropagation. The Mobius will save 24% GPU memory and 12% training time, which can greatly improve the T2V fine-tuning task and provide a novel insight for the AIGC community. We will release our codes in the future.
Channel-wise Topology Refinement Graph Convolution for Skeleton-Based Action Recognition
Aug 23, 2021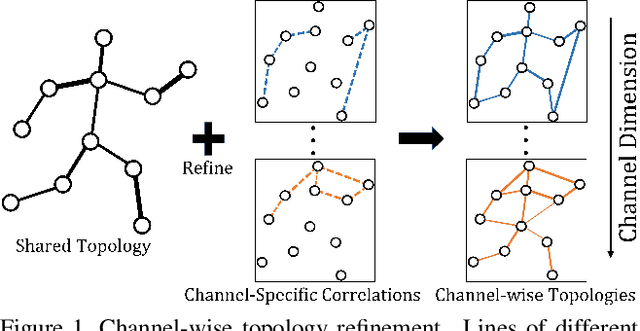
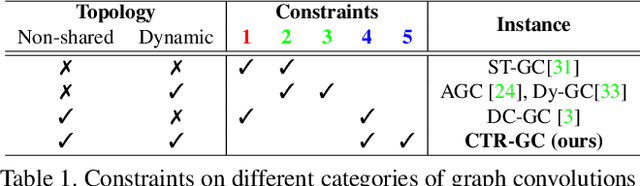
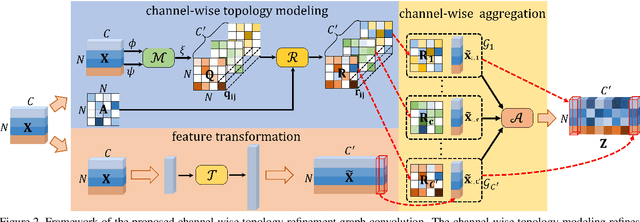
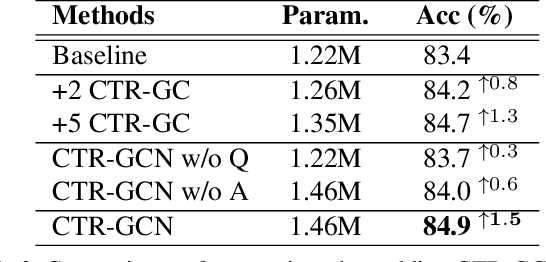
Graph convolutional networks (GCNs) have been widely used and achieved remarkable results in skeleton-based action recognition. In GCNs, graph topology dominates feature aggregation and therefore is the key to extracting representative features. In this work, we propose a novel Channel-wise Topology Refinement Graph Convolution (CTR-GC) to dynamically learn different topologies and effectively aggregate joint features in different channels for skeleton-based action recognition. The proposed CTR-GC models channel-wise topologies through learning a shared topology as a generic prior for all channels and refining it with channel-specific correlations for each channel. Our refinement method introduces few extra parameters and significantly reduces the difficulty of modeling channel-wise topologies. Furthermore, via reformulating graph convolutions into a unified form, we find that CTR-GC relaxes strict constraints of graph convolutions, leading to stronger representation capability. Combining CTR-GC with temporal modeling modules, we develop a powerful graph convolutional network named CTR-GCN which notably outperforms state-of-the-art methods on the NTU RGB+D, NTU RGB+D 120, and NW-UCLA datasets.
Open-book Video Captioning with Retrieve-Copy-Generate Network
Mar 09, 2021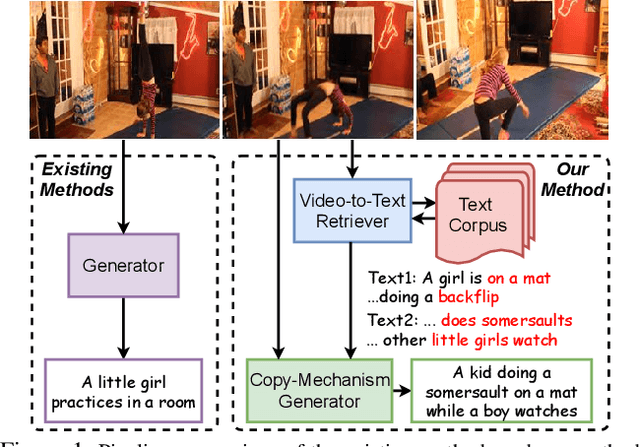
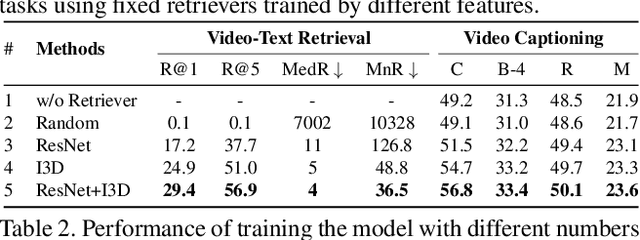
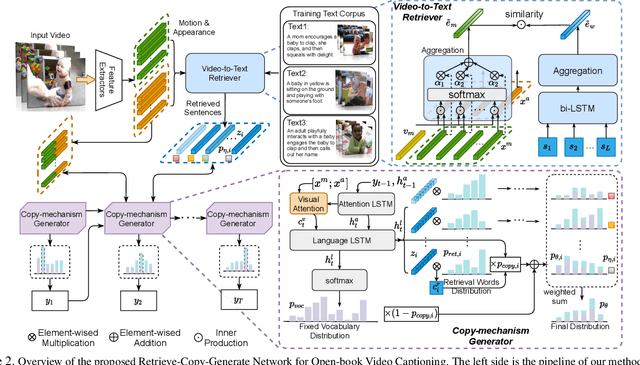
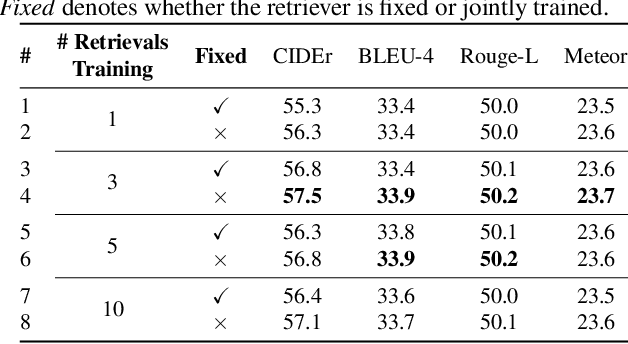
Due to the rapid emergence of short videos and the requirement for content understanding and creation, the video captioning task has received increasing attention in recent years. In this paper, we convert traditional video captioning task into a new paradigm, \ie, Open-book Video Captioning, which generates natural language under the prompts of video-content-relevant sentences, not limited to the video itself. To address the open-book video captioning problem, we propose a novel Retrieve-Copy-Generate network, where a pluggable video-to-text retriever is constructed to retrieve sentences as hints from the training corpus effectively, and a copy-mechanism generator is introduced to extract expressions from multi-retrieved sentences dynamically. The two modules can be trained end-to-end or separately, which is flexible and extensible. Our framework coordinates the conventional retrieval-based methods with orthodox encoder-decoder methods, which can not only draw on the diverse expressions in the retrieved sentences but also generate natural and accurate content of the video. Extensive experiments on several benchmark datasets show that our proposed approach surpasses the state-of-the-art performance, indicating the effectiveness and promising of the proposed paradigm in the task of video captioning.