 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTREA: Tree-Structure Reasoning Schema for Conversational Recommendation
Jul 20, 2023



Conversational recommender systems (CRS) aim to timely trace the dynamic interests of users through dialogues and generate relevant responses for item recommendations. Recently, various external knowledge bases (especially knowledge graphs) are incorporated into CRS to enhance the understanding of conversation contexts. However, recent reasoning-based models heavily rely on simplified structures such as linear structures or fixed-hierarchical structures for causality reasoning, hence they cannot fully figure out sophisticated relationships among utterances with external knowledge. To address this, we propose a novel Tree structure Reasoning schEmA named TREA. TREA constructs a multi-hierarchical scalable tree as the reasoning structure to clarify the causal relationships between mentioned entities, and fully utilizes historical conversations to generate more reasonable and suitable responses for recommended results. Extensive experiments on two public CRS datasets have demonstrated the effectiveness of our approach.
HyperDreamBooth: HyperNetworks for Fast Personalization of Text-to-Image Models
Jul 13, 2023



Personalization has emerged as a prominent aspect within the field of generative AI, enabling the synthesis of individuals in diverse contexts and styles, while retaining high-fidelity to their identities. However, the process of personalization presents inherent challenges in terms of time and memory requirements. Fine-tuning each personalized model needs considerable GPU time investment, and storing a personalized model per subject can be demanding in terms of storage capacity. To overcome these challenges, we propose HyperDreamBooth-a hypernetwork capable of efficiently generating a small set of personalized weights from a single image of a person. By composing these weights into the diffusion model, coupled with fast finetuning, HyperDreamBooth can generate a person's face in various contexts and styles, with high subject details while also preserving the model's crucial knowledge of diverse styles and semantic modifications. Our method achieves personalization on faces in roughly 20 seconds, 25x faster than DreamBooth and 125x faster than Textual Inversion, using as few as one reference image, with the same quality and style diversity as DreamBooth. Also our method yields a model that is 10000x smaller than a normal DreamBooth model. Project page: https://hyperdreambooth.github.io
An Evolution Kernel Method for Graph Classification through Heat Diffusion Dynamics
Jun 26, 2023



Autonomous individuals establish a structural complex system through pairwise connections and interactions. Notably, the evolution reflects the dynamic nature of each complex system since it recodes a series of temporal changes from the past, the present into the future. Different systems follow distinct evolutionary trajectories, which can serve as distinguishing traits for system classification. However, modeling a complex system's evolution is challenging for the graph model because the graph is typically a snapshot of the static status of a system, and thereby hard to manifest the long-term evolutionary traits of a system entirely. To address this challenge, we suggest utilizing a heat-driven method to generate temporal graph augmentation. This approach incorporates the physics-based heat kernel and DropNode technique to transform each static graph into a sequence of temporal ones. This approach effectively describes the evolutional behaviours of the system, including the retention or disappearance of elements at each time point based on the distributed heat on each node. Additionally, we propose a dynamic time-wrapping distance GDTW to quantitatively measure the distance between pairwise evolutionary systems through optimal matching. The resulting approach, called the Evolution Kernel method, has been successfully applied to classification problems in real-world structural graph datasets. The results yield significant improvements in supervised classification accuracy over a series of baseline methods.
Multi-View Attention Learning for Residual Disease Prediction of Ovarian Cancer
Jun 26, 2023In the treatment of ovarian cancer, precise residual disease prediction is significant for clinical and surgical decision-making. However, traditional methods are either invasive (e.g., laparoscopy) or time-consuming (e.g., manual analysis). Recently, deep learning methods make many efforts in automatic analysis of medical images. Despite the remarkable progress, most of them underestimated the importance of 3D image information of disease, which might brings a limited performance for residual disease prediction, especially in small-scale datasets. To this end, in this paper, we propose a novel Multi-View Attention Learning (MuVAL) method for residual disease prediction, which focuses on the comprehensive learning of 3D Computed Tomography (CT) images in a multi-view manner. Specifically, we first obtain multi-view of 3D CT images from transverse, coronal and sagittal views. To better represent the image features in a multi-view manner, we further leverage attention mechanism to help find the more relevant slices in each view. Extensive experiments on a dataset of 111 patients show that our method outperforms existing deep-learning methods.
Semi-Implicit Denoising Diffusion Models (SIDDMs)
Jun 23, 2023



Despite the proliferation of generative models, achieving fast sampling during inference without compromising sample diversity and quality remains challenging. Existing models such as Denoising Diffusion Probabilistic Models (DDPM) deliver high-quality, diverse samples but are slowed by an inherently high number of iterative steps. The Denoising Diffusion Generative Adversarial Networks (DDGAN) attempted to circumvent this limitation by integrating a GAN model for larger jumps in the diffusion process. However, DDGAN encountered scalability limitations when applied to large datasets. To address these limitations, we introduce a novel approach that tackles the problem by matching implicit and explicit factors. More specifically, our approach involves utilizing an implicit model to match the marginal distributions of noisy data and the explicit conditional distribution of the forward diffusion. This combination allows us to effectively match the joint denoising distributions. Unlike DDPM but similar to DDGAN, we do not enforce a parametric distribution for the reverse step, enabling us to take large steps during inference. Similar to the DDPM but unlike DDGAN, we take advantage of the exact form of the diffusion process. We demonstrate that our proposed method obtains comparable generative performance to diffusion-based models and vastly superior results to models with a small number of sampling steps.
Document Entity Retrieval with Massive and Noisy Pre-training
Jun 15, 2023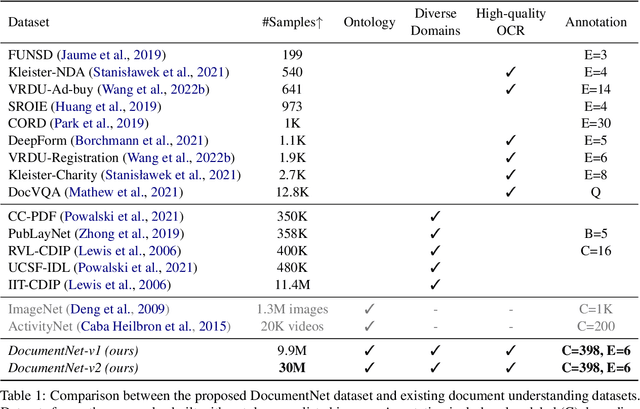

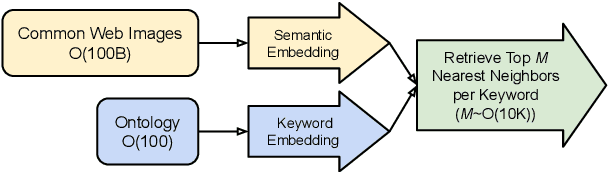

Visually-Rich Document Entity Retrieval (VDER) is a type of machine learning task that aims at recovering text spans in the documents for each of the entities in question. VDER has gained significant attention in recent years thanks to its broad applications in enterprise AI. Unfortunately, as document images often contain personally identifiable information (PII), publicly available data have been scarce, not only because of privacy constraints but also the costs of acquiring annotations. To make things worse, each dataset would often define its own sets of entities, and the non-overlapping entity spaces between datasets make it difficult to transfer knowledge between documents. In this paper, we propose a method to collect massive-scale, noisy, and weakly labeled data from the web to benefit the training of VDER models. Such a method will generate a huge amount of document image data to compensate for the lack of training data in many VDER settings. Moreover, the collected dataset named DocuNet would not need to be dependent on specific document types or entity sets, making it universally applicable to all VDER tasks. Empowered by DocuNet, we present a lightweight multimodal architecture named UniFormer, which can learn a unified representation from text, layout, and image crops without needing extra visual pertaining. We experiment with our methods on popular VDER models in various settings and show the improvements when this massive dataset is incorporated with UniFormer on both classic entity retrieval and few-shot learning settings.
An Empirical Study on the Language Modal in Visual Question Answering
May 17, 2023



Generalization beyond in-domain experience to out-of-distribution data is of paramount significance in the AI domain. Of late, state-of-the-art Visual Question Answering (VQA) models have shown impressive performance on in-domain data, partially due to the language priors bias which, however, hinders the generalization ability in practice. This paper attempts to provide new insights into the influence of language modality on VQA performance from an empirical study perspective. To achieve this, we conducted a series of experiments on six models. The results of these experiments revealed that, 1) apart from prior bias caused by question types, there is a notable influence of postfix-related bias in inducing biases, and 2) training VQA models with word-sequence-related variant questions demonstrated improved performance on the out-of-distribution benchmark, and the LXMERT even achieved a 10-point gain without adopting any debiasing methods. We delved into the underlying reasons behind these experimental results and put forward some simple proposals to reduce the models' dependency on language priors. The experimental results demonstrated the effectiveness of our proposed method in improving performance on the out-of-distribution benchmark, VQA-CPv2. We hope this study can inspire novel insights for future research on designing bias-reduction approaches.
Towards Hierarchical Policy Learning for Conversational Recommendation with Hypergraph-based Reinforcement Learning
May 04, 2023



Conversational recommendation systems (CRS) aim to timely and proactively acquire user dynamic preferred attributes through conversations for item recommendation. In each turn of CRS, there naturally have two decision-making processes with different roles that influence each other: 1) director, which is to select the follow-up option (i.e., ask or recommend) that is more effective for reducing the action space and acquiring user preferences; and 2) actor, which is to accordingly choose primitive actions (i.e., asked attribute or recommended item) that satisfy user preferences and give feedback to estimate the effectiveness of the director's option. However, existing methods heavily rely on a unified decision-making module or heuristic rules, while neglecting to distinguish the roles of different decision procedures, as well as the mutual influences between them. To address this, we propose a novel Director-Actor Hierarchical Conversational Recommender (DAHCR), where the director selects the most effective option, followed by the actor accordingly choosing primitive actions that satisfy user preferences. Specifically, we develop a dynamic hypergraph to model user preferences and introduce an intrinsic motivation to train from weak supervision over the director. Finally, to alleviate the bad effect of model bias on the mutual influence between the director and actor, we model the director's option by sampling from a categorical distribution. Extensive experiments demonstrate that DAHCR outperforms state-of-the-art methods.
AttenWalker: Unsupervised Long-Document Question Answering via Attention-based Graph Walking
May 03, 2023Annotating long-document question answering (long-document QA) pairs is time-consuming and expensive. To alleviate the problem, it might be possible to generate long-document QA pairs via unsupervised question answering (UQA) methods. However, existing UQA tasks are based on short documents, and can hardly incorporate long-range information. To tackle the problem, we propose a new task, named unsupervised long-document question answering (ULQA), aiming to generate high-quality long-document QA instances in an unsupervised manner. Besides, we propose AttenWalker, a novel unsupervised method to aggregate and generate answers with long-range dependency so as to construct long-document QA pairs. Specifically, AttenWalker is composed of three modules, i.e., span collector, span linker and answer aggregator. Firstly, the span collector takes advantage of constituent parsing and reconstruction loss to select informative candidate spans for constructing answers. Secondly, by going through the attention graph of a pre-trained long-document model, potentially interrelated text spans (that might be far apart) could be linked together via an attention-walking algorithm. Thirdly, in the answer aggregator, linked spans are aggregated into the final answer via the mask-filling ability of a pre-trained model. Extensive experiments show that AttenWalker outperforms previous methods on Qasper and NarrativeQA. In addition, AttenWalker also shows strong performance in the few-shot learning setting.
Glocal Energy-based Learning for Few-Shot Open-Set Recognition
Apr 24, 2023Few-shot open-set recognition (FSOR) is a challenging task of great practical value. It aims to categorize a sample to one of the pre-defined, closed-set classes illustrated by few examples while being able to reject the sample from unknown classes. In this work, we approach the FSOR task by proposing a novel energy-based hybrid model. The model is composed of two branches, where a classification branch learns a metric to classify a sample to one of closed-set classes and the energy branch explicitly estimates the open-set probability. To achieve holistic detection of open-set samples, our model leverages both class-wise and pixel-wise features to learn a glocal energy-based score, in which a global energy score is learned using the class-wise features, while a local energy score is learned using the pixel-wise features. The model is enforced to assign large energy scores to samples that are deviated from the few-shot examples in either the class-wise features or the pixel-wise features, and to assign small energy scores otherwise. Experiments on three standard FSOR datasets show the superior performance of our model.