 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Few Samples: A Novel Approach for High-Quality Malcode Generation
Aug 25, 2025Intrusion Detection Systems (IDS) play a crucial role in network security defense. However, a significant challenge for IDS in training detection models is the shortage of adequately labeled malicious samples. To address these issues, this paper introduces a novel semi-supervised framework \textbf{GANGRL-LLM}, which integrates Generative Adversarial Networks (GANs) with Large Language Models (LLMs) to enhance malicious code generation and SQL Injection (SQLi) detection capabilities in few-sample learning scenarios. Specifically, our framework adopts a collaborative training paradigm where: (1) the GAN-based discriminator improves malicious pattern recognition through adversarial learning with generated samples and limited real samples; and (2) the LLM-based generator refines the quality of malicious code synthesis using reward signals from the discriminator. The experimental results demonstrate that even with a limited number of labeled samples, our training framework is highly effective in enhancing both malicious code generation and detection capabilities. This dual enhancement capability offers a promising solution for developing adaptive defense systems capable of countering evolving cyber threats.
Physical Backdoor: Towards Temperature-based Backdoor Attacks in the Physical World
Apr 30, 2024



Backdoor attacks have been well-studied in visible light object detection (VLOD) in recent years. However, VLOD can not effectively work in dark and temperature-sensitive scenarios. Instead, thermal infrared object detection (TIOD) is the most accessible and practical in such environments. In this paper, our team is the first to investigate the security vulnerabilities associated with TIOD in the context of backdoor attacks, spanning both the digital and physical realms. We introduce two novel types of backdoor attacks on TIOD, each offering unique capabilities: Object-affecting Attack and Range-affecting Attack. We conduct a comprehensive analysis of key factors influencing trigger design, which include temperature, size, material, and concealment. These factors, especially temperature, significantly impact the efficacy of backdoor attacks on TIOD. A thorough understanding of these factors will serve as a foundation for designing physical triggers and temperature controlling experiments. Our study includes extensive experiments conducted in both digital and physical environments. In the digital realm, we evaluate our approach using benchmark datasets for TIOD, achieving an Attack Success Rate (ASR) of up to 98.21%. In the physical realm, we test our approach in two real-world settings: a traffic intersection and a parking lot, using a thermal infrared camera. Here, we attain an ASR of up to 98.38%.
3DHacker: Spectrum-based Decision Boundary Generation for Hard-label 3D Point Cloud Attack
Aug 15, 2023



With the maturity of depth sensors, the vulnerability of 3D point cloud models has received increasing attention in various applications such as autonomous driving and robot navigation. Previous 3D adversarial attackers either follow the white-box setting to iteratively update the coordinate perturbations based on gradients, or utilize the output model logits to estimate noisy gradients in the black-box setting. However, these attack methods are hard to be deployed in real-world scenarios since realistic 3D applications will not share any model details to users. Therefore, we explore a more challenging yet practical 3D attack setting, \textit{i.e.}, attacking point clouds with black-box hard labels, in which the attacker can only have access to the prediction label of the input. To tackle this setting, we propose a novel 3D attack method, termed \textbf{3D} \textbf{H}ard-label att\textbf{acker} (\textbf{3DHacker}), based on the developed decision boundary algorithm to generate adversarial samples solely with the knowledge of class labels. Specifically, to construct the class-aware model decision boundary, 3DHacker first randomly fuses two point clouds of different classes in the spectral domain to craft their intermediate sample with high imperceptibility, then projects it onto the decision boundary via binary search. To restrict the final perturbation size, 3DHacker further introduces an iterative optimization strategy to move the intermediate sample along the decision boundary for generating adversarial point clouds with smallest trivial perturbations. Extensive evaluations show that, even in the challenging hard-label setting, 3DHacker still competitively outperforms existing 3D attacks regarding the attack performance as well as adversary quality.
Context-aware Biaffine Localizing Network for Temporal Sentence Grounding
Mar 22, 2021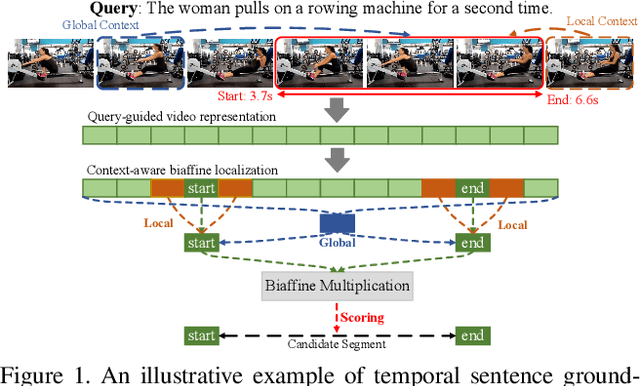
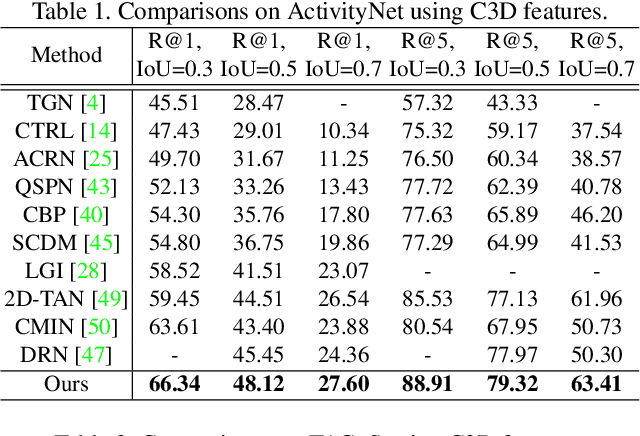
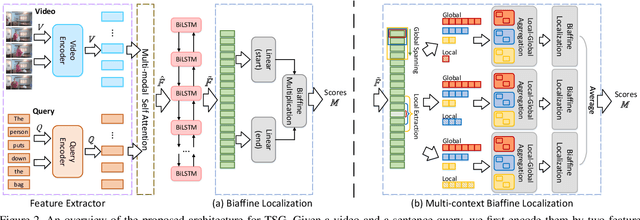
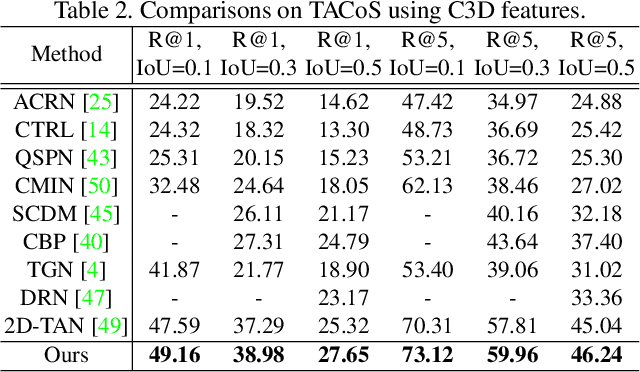
This paper addresses the problem of temporal sentence grounding (TSG), which aims to identify the temporal boundary of a specific segment from an untrimmed video by a sentence query. Previous works either compare pre-defined candidate segments with the query and select the best one by ranking, or directly regress the boundary timestamps of the target segment. In this paper, we propose a novel localization framework that scores all pairs of start and end indices within the video simultaneously with a biaffine mechanism. In particular, we present a Context-aware Biaffine Localizing Network (CBLN) which incorporates both local and global contexts into features of each start/end position for biaffine-based localization. The local contexts from the adjacent frames help distinguish the visually similar appearance, and the global contexts from the entire video contribute to reasoning the temporal relation. Besides, we also develop a multi-modal self-attention module to provide fine-grained query-guided video representation for this biaffine strategy. Extensive experiments show that our CBLN significantly outperforms state-of-the-arts on three public datasets (ActivityNet Captions, TACoS, and Charades-STA), demonstrating the effectiveness of the proposed localization framework.