 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy-Based Adaptive Weighting for Self-Training
Mar 31, 2025
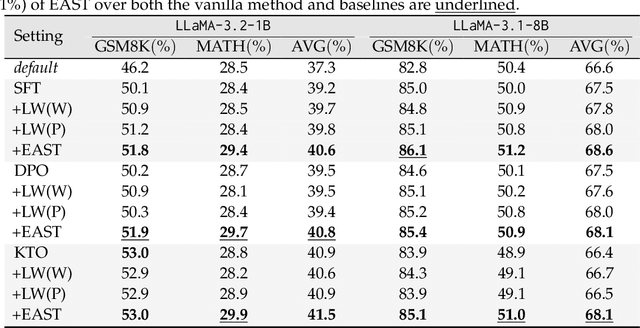
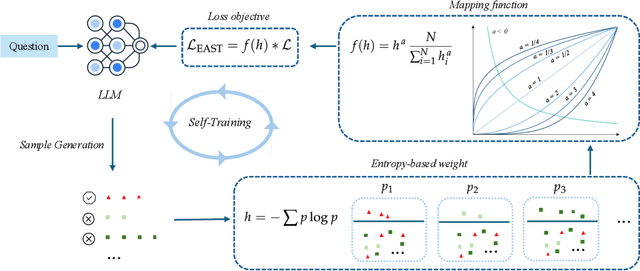

The mathematical problem-solving capabilities of large language models have become a focal point of research, with growing interests in leveraging self-generated reasoning paths as a promising way to refine and enhance these models. These paths capture step-by-step logical processes while requiring only the correct answer for supervision. The self-training method has been shown to be effective in reasoning tasks while eliminating the need for external models and manual annotations. However, optimizing the use of self-generated data for model training remains an open challenge. In this work, we propose Entropy-Based Adaptive Weighting for Self-Training (EAST), an adaptive weighting strategy designed to prioritize uncertain data during self-training. Specifically, EAST employs a mapping function with a tunable parameter that controls the sharpness of the weighting, assigning higher weights to data where the model exhibits greater uncertainty. This approach guides the model to focus on more informative and challenging examples, thereby enhancing its reasoning ability. We evaluate our approach on GSM8K and MATH benchmarks. Empirical results show that, while the vanilla method yields virtually no improvement (0%) on MATH, EAST achieves around a 1% gain over backbone model. On GSM8K, EAST attains a further 1-2% performance boost compared to the vanilla method.
Reinforcement Learning-based Token Pruning in Vision Transformers: A Markov Game Approach
Mar 30, 2025



Vision Transformers (ViTs) have computational costs scaling quadratically with the number of tokens, calling for effective token pruning policies. Most existing policies are handcrafted, lacking adaptivity to varying inputs. Moreover, they fail to consider the sequential nature of token pruning across multiple layers. In this work, for the first time (as far as we know), we exploit Reinforcement Learning (RL) to data-adaptively learn a pruning policy. Formulating token pruning as a sequential decision-making problem, we model it as a Markov Game and utilize Multi-Agent Proximal Policy Optimization (MAPPO) where each agent makes an individualized pruning decision for a single token. We also develop reward functions that enable simultaneous collaboration and competition of these agents to balance efficiency and accuracy. On the well-known ImageNet-1k dataset, our method improves the inference speed by up to 44% while incurring only a negligible accuracy drop of 0.4%. The source code is available at https://github.com/daashuai/rl4evit.
Learnable Sequence Augmenter for Triplet Contrastive Learning in Sequential Recommendation
Mar 26, 2025Most existing contrastive learning-based sequential recommendation (SR) methods rely on random operations (e.g., crop, reorder, and substitute) to generate augmented sequences. These methods often struggle to create positive sample pairs that closely resemble the representations of the raw sequences, potentially disrupting item correlations by deleting key items or introducing noisy iterac, which misguides the contrastive learning process. To address this limitation, we propose Learnable sequence Augmentor for triplet Contrastive Learning in sequential Recommendation (LACLRec). Specifically, the self-supervised learning-based augmenter can automatically delete noisy items from sequences and insert new items that better capture item transition patterns, generating a higher-quality augmented sequence. Subsequently, we randomly generate another augmented sequence and design a ranking-based triplet contrastive loss to differentiate the similarities between the raw sequence, the augmented sequence from augmenter, and the randomly augmented sequence, providing more fine-grained contrastive signals. Extensive experiments on three real-world datasets demonstrate that both the sequence augmenter and the triplet contrast contribute to improving recommendation accuracy. LACLRec significantly outperforms the baseline model CL4SRec, and demonstrates superior performance compared to several state-of-the-art sequential recommendation algorithms.
Wan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
OpenVLThinker: An Early Exploration to Complex Vision-Language Reasoning via Iterative Self-Improvement
Mar 21, 2025
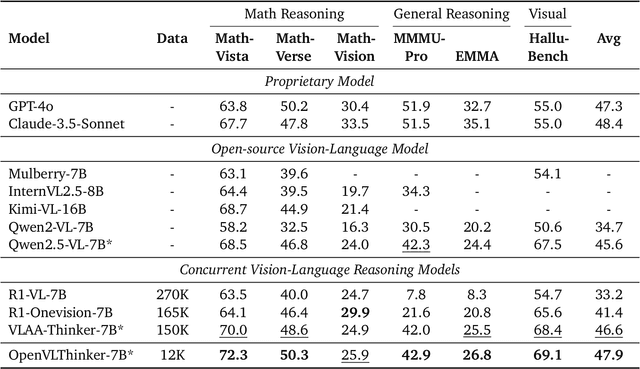
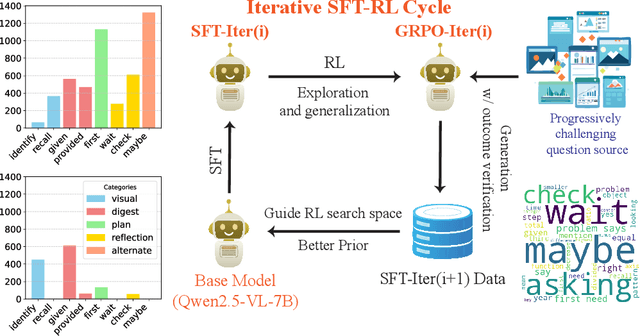
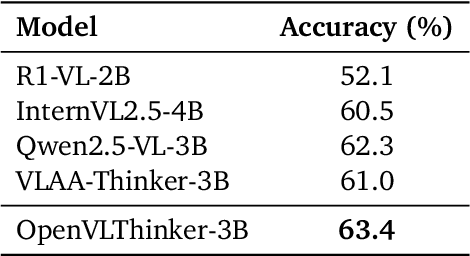
Recent advancements demonstrated by DeepSeek-R1 have shown that complex reasoning abilities in large language models (LLMs), including sophisticated behaviors such as self-verification and self-correction, can be achieved by RL with verifiable rewards and significantly improves model performance on challenging tasks such as AIME. Motivated by these findings, our study investigates whether similar reasoning capabilities can be successfully integrated into large vision-language models (LVLMs) and assesses their impact on challenging multimodal reasoning tasks. We consider an approach that iteratively leverages supervised fine-tuning (SFT) on lightweight training data and Reinforcement Learning (RL) to further improve model generalization. Initially, reasoning capabilities were distilled from pure-text R1 models by generating reasoning steps using high-quality captions of the images sourced from diverse visual datasets. Subsequently, iterative RL training further enhance reasoning skills, with each iteration's RL-improved model generating refined SFT datasets for the next round. This iterative process yielded OpenVLThinker, a LVLM exhibiting consistently improved reasoning performance on challenging benchmarks such as MathVista, MathVerse, and MathVision, demonstrating the potential of our strategy for robust vision-language reasoning. The code, model and data are held at https://github.com/yihedeng9/OpenVLThinker.
Diffusion-augmented Graph Contrastive Learning for Collaborative Filter
Mar 20, 2025



Graph-based collaborative filtering has been established as a prominent approach in recommendation systems, leveraging the inherent graph topology of user-item interactions to model high-order connectivity patterns and enhance recommendation performance. Recent advances in Graph Contrastive Learning (GCL) have demonstrated promising potential to alleviate data sparsity issues by improving representation learning through contrastive view generation and mutual information maximization. However, existing approaches lack effective data augmentation strategies. Structural augmentation risks distorting fundamental graph topology, while feature-level perturbation techniques predominantly employ uniform noise scales that fail to account for node-specific characteristics. To solve these challenges, we propose Diffusion-augmented Contrastive Learning (DGCL), an innovative framework that integrates diffusion models with contrastive learning for enhanced collaborative filtering. Our approach employs a diffusion process that learns node-specific Gaussian distributions of representations, thereby generating semantically consistent yet diversified contrastive views through reverse diffusion sampling. DGCL facilitates adaptive data augmentation based on reconstructed representations, considering both semantic coherence and node-specific features. In addition, it explores unrepresented regions of the latent sparse feature space, thereby enriching the diversity of contrastive views. Extensive experimental results demonstrate the effectiveness of DGCL on three public datasets.
Semantic-Guided Global-Local Collaborative Networks for Lightweight Image Super-Resolution
Mar 20, 2025



Single-Image Super-Resolution (SISR) plays a pivotal role in enhancing the accuracy and reliability of measurement systems, which are integral to various vision-based instrumentation and measurement applications. These systems often require clear and detailed images for precise object detection and recognition. However, images captured by visual measurement tools frequently suffer from degradation, including blurring and loss of detail, which can impede measurement accuracy.As a potential remedy, we in this paper propose a Semantic-Guided Global-Local Collaborative Network (SGGLC-Net) for lightweight SISR. Our SGGLC-Net leverages semantic priors extracted from a pre-trained model to guide the super-resolution process, enhancing image detail quality effectively. Specifically,we propose a Semantic Guidance Module that seamlessly integrates the semantic priors into the super-resolution network, enabling the network to more adeptly capture and utilize semantic priors, thereby enhancing image details. To further explore both local and non-local interactions for improved detail rendition,we propose a Global-Local Collaborative Module, which features three Global and Local Detail Enhancement Modules, as well as a Hybrid Attention Mechanism to work together to efficiently learn more useful features. Our extensive experiments show that SGGLC-Net achieves competitive PSNR and SSIM values across multiple benchmark datasets, demonstrating higher performance with the multi-adds reduction of 12.81G compared to state-of-the-art lightweight super-resolution approaches. These improvements underscore the potential of our approach to enhance the precision and effectiveness of visual measurement systems. Codes are at https://github.com/fanamber831/SGGLC-Net.
* 14 pages,13 figures, 9 tables
Iterative Optimal Attention and Local Model for Single Image Rain Streak Removal
Mar 20, 2025High-fidelity imaging is crucial for the successful safety supervision and intelligent deployment of vision-based measurement systems (VBMS). It ensures high-quality imaging in VBMS, which is fundamental for reliable visual measurement and analysis. However, imaging quality can be significantly impaired by adverse weather conditions, particularly rain, leading to blurred images and reduced contrast. Such impairments increase the risk of inaccurate evaluations and misinterpretations in VBMS. To address these limitations, we propose an Expectation Maximization Reconstruction Transformer (EMResformer) for single image rain streak removal. The EMResformer retains the key self-attention values for feature aggregation, enhancing local features to produce superior image reconstruction. Specifically, we propose an Expectation Maximization Block seamlessly integrated into the single image rain streak removal network, enhancing its ability to eliminate superfluous information and restore a cleaner background image. Additionally, to further enhance local information for improved detail rendition, we introduce a Local Model Residual Block, which integrates two local model blocks along with a sequence of convolutions and activation functions. This integration synergistically facilitates the extraction of more pertinent features for enhanced single image rain streak removal. Extensive experiments validate that our proposed EMResformer surpasses current state-of-the-art single image rain streak removal methods on both synthetic and real-world datasets, achieving an improved balance between model complexity and single image deraining performance. Furthermore, we evaluate the effectiveness of our method in VBMS scenarios, demonstrating that high-quality imaging significantly improves the accuracy and reliability of VBMS tasks.
Intra and Inter Parser-Prompted Transformers for Effective Image Restoration
Mar 18, 2025We propose Intra and Inter Parser-Prompted Transformers (PPTformer) that explore useful features from visual foundation models for image restoration. Specifically, PPTformer contains two parts: an Image Restoration Network (IRNet) for restoring images from degraded observations and a Parser-Prompted Feature Generation Network (PPFGNet) for providing IRNet with reliable parser information to boost restoration. To enhance the integration of the parser within IRNet, we propose Intra Parser-Prompted Attention (IntraPPA) and Inter Parser-Prompted Attention (InterPPA) to implicitly and explicitly learn useful parser features to facilitate restoration. The IntraPPA re-considers cross attention between parser and restoration features, enabling implicit perception of the parser from a long-range and intra-layer perspective. Conversely, the InterPPA initially fuses restoration features with those of the parser, followed by formulating these fused features within an attention mechanism to explicitly perceive parser information. Further, we propose a parser-prompted feed-forward network to guide restoration within pixel-wise gating modulation. Experimental results show that PPTformer achieves state-of-the-art performance on image deraining, defocus deblurring, desnowing, and low-light enhancement.
DatawiseAgent: A Notebook-Centric LLM Agent Framework for Automated Data Science
Mar 10, 2025



Data Science tasks are multifaceted, dynamic, and often domain-specific. Existing LLM-based approaches largely concentrate on isolated phases, neglecting the interdependent nature of many data science tasks and limiting their capacity for comprehensive end-to-end support. We propose DatawiseAgent, a notebook-centric LLM agent framework that unifies interactions among user, agent and the computational environment through markdown and executable code cells, supporting flexible and adaptive automated data science. Built on a Finite State Transducer(FST), DatawiseAgent orchestrates four stages, including DSF-like planning, incremental execution, self-debugging, and post-filtering. Specifically, the DFS-like planning stage systematically explores the solution space, while incremental execution harnesses real-time feedback and accommodates LLM's limited capabilities to progressively complete tasks. The self-debugging and post-filtering modules further enhance reliability by diagnosing and correcting errors and pruning extraneous information. Extensive experiments on diverse tasks, including data analysis, visualization, and data modeling, show that DatawiseAgent consistently outperforms or matches state-of-the-art methods across multiple model settings. These results highlight its potential to generalize across data science scenarios and lay the groundwork for more efficient, fully automated workflows.