 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey of Reward Models: Taxonomy, Applications, Challenges, and Future
Apr 12, 2025Reward Model (RM) has demonstrated impressive potential for enhancing Large Language Models (LLM), as RM can serve as a proxy for human preferences, providing signals to guide LLMs' behavior in various tasks. In this paper, we provide a comprehensive overview of relevant research, exploring RMs from the perspectives of preference collection, reward modeling, and usage. Next, we introduce the applications of RMs and discuss the benchmarks for evaluation. Furthermore, we conduct an in-depth analysis of the challenges existing in the field and dive into the potential research directions. This paper is dedicated to providing beginners with a comprehensive introduction to RMs and facilitating future studies. The resources are publicly available at github\footnote{https://github.com/JLZhong23/awesome-reward-models}.
Generalized Tensor-based Parameter-Efficient Fine-Tuning via Lie Group Transformations
Apr 01, 2025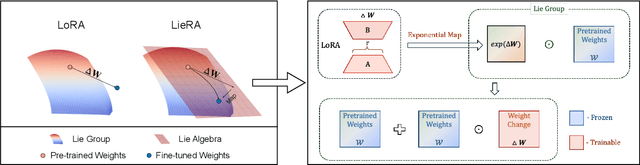
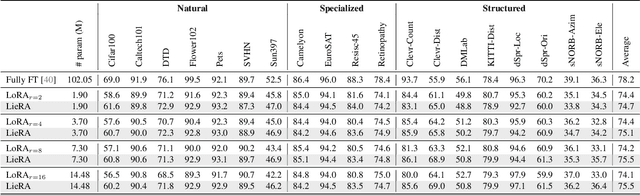
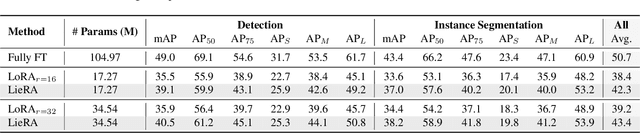

Adapting pre-trained foundation models for diverse downstream tasks is a core practice in artificial intelligence. However, the wide range of tasks and high computational costs make full fine-tuning impractical. To overcome this, parameter-efficient fine-tuning (PEFT) methods like LoRA have emerged and are becoming a growing research focus. Despite the success of these methods, they are primarily designed for linear layers, focusing on two-dimensional matrices while largely ignoring higher-dimensional parameter spaces like convolutional kernels. Moreover, directly applying these methods to higher-dimensional parameter spaces often disrupts their structural relationships. Given the rapid advancements in matrix-based PEFT methods, rather than designing a specialized strategy, we propose a generalization that extends matrix-based PEFT methods to higher-dimensional parameter spaces without compromising their structural properties. Specifically, we treat parameters as elements of a Lie group, with updates modeled as perturbations in the corresponding Lie algebra. These perturbations are mapped back to the Lie group through the exponential map, ensuring smooth, consistent updates that preserve the inherent structure of the parameter space. Extensive experiments on computer vision and natural language processing validate the effectiveness and versatility of our approach, demonstrating clear improvements over existing methods.
Exploring Data Scaling Trends and Effects in Reinforcement Learning from Human Feedback
Mar 31, 2025Reinforcement Learning from Human Feedback (RLHF) is crucial for aligning large language models with human preferences. While recent research has focused on algorithmic improvements, the importance of prompt-data construction has been overlooked. This paper addresses this gap by exploring data-driven bottlenecks in RLHF performance scaling, particularly reward hacking and decreasing response diversity. We introduce a hybrid reward system combining reasoning task verifiers (RTV) and a generative reward model (GenRM) to mitigate reward hacking. We also propose a novel prompt-selection method, Pre-PPO, to maintain response diversity and enhance learning effectiveness. Additionally, we find that prioritizing mathematical and coding tasks early in RLHF training significantly improves performance. Experiments across two model sizes validate our methods' effectiveness and scalability. Results show that RTV is most resistant to reward hacking, followed by GenRM with ground truth, and then GenRM with SFT Best-of-N responses. Our strategies enable rapid capture of subtle task-specific distinctions, leading to substantial improvements in overall RLHF performance. This work highlights the importance of careful data construction and provides practical methods to overcome performance barriers in RLHF.
Dereflection Any Image with Diffusion Priors and Diversified Data
Mar 21, 2025Reflection removal of a single image remains a highly challenging task due to the complex entanglement between target scenes and unwanted reflections. Despite significant progress, existing methods are hindered by the scarcity of high-quality, diverse data and insufficient restoration priors, resulting in limited generalization across various real-world scenarios. In this paper, we propose Dereflection Any Image, a comprehensive solution with an efficient data preparation pipeline and a generalizable model for robust reflection removal. First, we introduce a dataset named Diverse Reflection Removal (DRR) created by randomly rotating reflective mediums in target scenes, enabling variation of reflection angles and intensities, and setting a new benchmark in scale, quality, and diversity. Second, we propose a diffusion-based framework with one-step diffusion for deterministic outputs and fast inference. To ensure stable learning, we design a three-stage progressive training strategy, including reflection-invariant finetuning to encourage consistent outputs across varying reflection patterns that characterize our dataset. Extensive experiments show that our method achieves SOTA performance on both common benchmarks and challenging in-the-wild images, showing superior generalization across diverse real-world scenes.
Marten: Visual Question Answering with Mask Generation for Multi-modal Document Understanding
Mar 18, 2025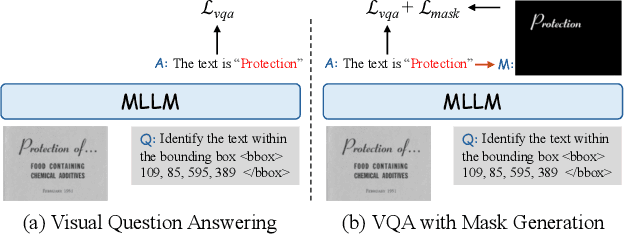
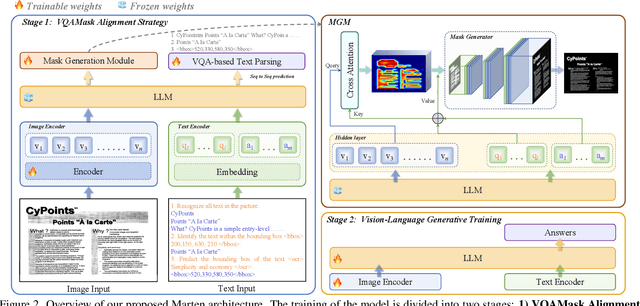

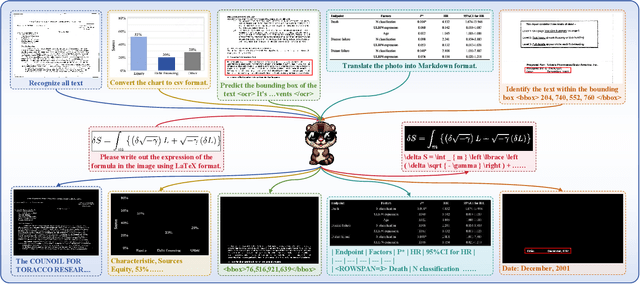
Multi-modal Large Language Models (MLLMs) have introduced a novel dimension to document understanding, i.e., they endow large language models with visual comprehension capabilities; however, how to design a suitable image-text pre-training task for bridging the visual and language modality in document-level MLLMs remains underexplored. In this study, we introduce a novel visual-language alignment method that casts the key issue as a Visual Question Answering with Mask generation (VQAMask) task, optimizing two tasks simultaneously: VQA-based text parsing and mask generation. The former allows the model to implicitly align images and text at the semantic level. The latter introduces an additional mask generator (discarded during inference) to explicitly ensure alignment between visual texts within images and their corresponding image regions at a spatially-aware level. Together, they can prevent model hallucinations when parsing visual text and effectively promote spatially-aware feature representation learning. To support the proposed VQAMask task, we construct a comprehensive image-mask generation pipeline and provide a large-scale dataset with 6M data (MTMask6M). Subsequently, we demonstrate that introducing the proposed mask generation task yields competitive document-level understanding performance. Leveraging the proposed VQAMask, we introduce Marten, a training-efficient MLLM tailored for document-level understanding. Extensive experiments show that our Marten consistently achieves significant improvements among 8B-MLLMs in document-centric tasks. Code and datasets are available at https://github.com/PriNing/Marten.
A Token-level Text Image Foundation Model for Document Understanding
Mar 04, 2025



In recent years, general visual foundation models (VFMs) have witnessed increasing adoption, particularly as image encoders for popular multi-modal large language models (MLLMs). However, without semantically fine-grained supervision, these models still encounter fundamental prediction errors in the context of downstream text-image-related tasks, i.e., perception, understanding and reasoning with images containing small and dense texts. To bridge this gap, we develop TokenOCR, the first token-level visual foundation model specifically tailored for text-image-related tasks, designed to support a variety of traditional downstream applications. To facilitate the pretraining of TokenOCR, we also devise a high-quality data production pipeline that constructs the first token-level image text dataset, TokenIT, comprising 20 million images and 1.8 billion token-mask pairs. Furthermore, leveraging this foundation with exceptional image-as-text capability, we seamlessly replace previous VFMs with TokenOCR to construct a document-level MLLM, TokenVL, for VQA-based document understanding tasks. Finally, extensive experiments demonstrate the effectiveness of TokenOCR and TokenVL. Code, datasets, and weights will be available at https://token-family.github.io/TokenOCR_project.
MDN: Mamba-Driven Dualstream Network For Medical Hyperspectral Image Segmentation
Feb 24, 2025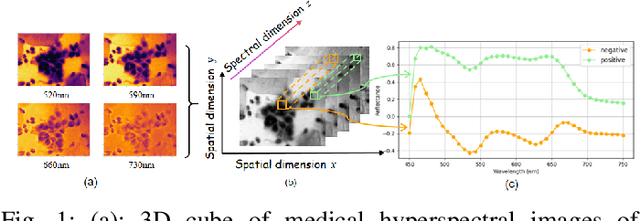
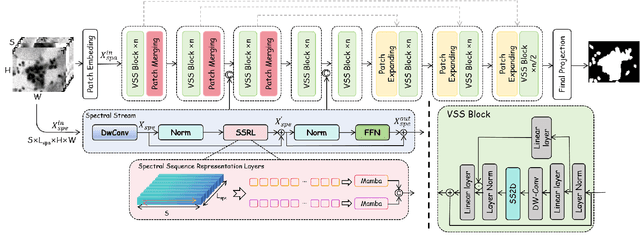
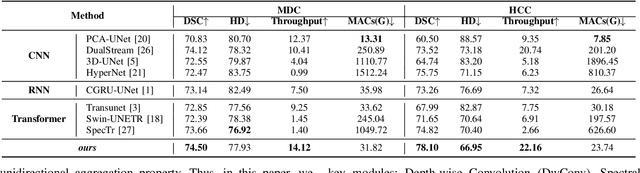
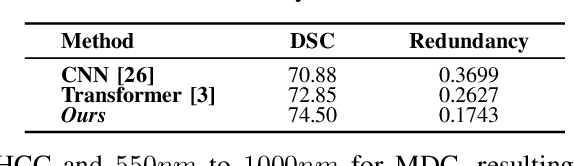
Medical Hyperspectral Imaging (MHSI) offers potential for computational pathology and precision medicine. However, existing CNN and Transformer struggle to balance segmentation accuracy and speed due to high spatial-spectral dimensionality. In this study, we leverage Mamba's global context modeling to propose a dual-stream architecture for joint spatial-spectral feature extraction. To address the limitation of Mamba's unidirectional aggregation, we introduce a recurrent spectral sequence representation to capture low-redundancy global spectral features. Experiments on a public Multi-Dimensional Choledoch dataset and a private Cervical Cancer dataset show that our method outperforms state-of-the-art approaches in segmentation accuracy while minimizing resource usage and achieving the fastest inference speed. Our code will be available at https://github.com/DeepMed-Lab-ECNU/MDN.
AdaptiveStep: Automatically Dividing Reasoning Step through Model Confidence
Feb 19, 2025Current approaches for training Process Reward Models (PRMs) often involve breaking down responses into multiple reasoning steps using rule-based techniques, such as using predefined placeholder tokens or setting the reasoning step's length into a fixed size. These approaches overlook the fact that specific words do not typically mark true decision points in a text. To address this, we propose AdaptiveStep, a method that divides reasoning steps based on the model's confidence in predicting the next word. This division method provides more decision-making information at each step, enhancing downstream tasks, such as reward model learning. Moreover, our method does not require manual annotation. We demonstrate its effectiveness through experiments with AdaptiveStep-trained PRMs in mathematical reasoning and code generation tasks. Experimental results indicate that the outcome PRM achieves state-of-the-art Best-of-N performance, surpassing greedy search strategy with token-level value-guided decoding, while also reducing construction costs by over 30% compared to existing open-source PRMs. In addition, we provide a thorough analysis and case study on the PRM's performance, transferability, and generalization capabilities.
Unveiling the Mystery of Weight in Large Foundation Models: Gaussian Distribution Never Fades
Jan 18, 2025



This paper presents a pioneering exploration of the mechanisms underlying large foundation models' (LFMs) weights, aiming to simplify AI research. Through extensive observation and analysis on prevailing LFMs, we find that regardless of initialization strategies, their weights predominantly follow a Gaussian distribution, with occasional sharp, inverted T-shaped, or linear patterns. We further discover that the weights share the i.i.d. properties of Gaussian noise, and explore their direct relationship. We find that transformation weights can be derived from Gaussian noise, and they primarily serve to increase the standard deviation of pre-trained weights, with their standard deviation growing with layer depth. In other words, transformation weights broaden the acceptable deviation from the optimal weights, facilitating adaptation to downstream tasks. Building upon the above conclusions, we thoroughly discussed the nature of optimal weights, ultimately concluding that they should exhibit zero-mean, symmetry, and sparsity, with the sparse values being a truncated Gaussian distribution and a few outliers. Our experiments in LFM adaptation and editing demonstrate the effectiveness of these insights. We hope these findings can provide a foundational understanding to pave the way for future advancements in the LFM community.
Enhancing Visual Representation for Text-based Person Searching
Dec 30, 2024



Text-based person search aims to retrieve the matched pedestrians from a large-scale image database according to the text description. The core difficulty of this task is how to extract effective details from pedestrian images and texts, and achieve cross-modal alignment in a common latent space. Prior works adopt image and text encoders pre-trained on unimodal data to extract global and local features from image and text respectively, and then global-local alignment is achieved explicitly. However, these approaches still lack the ability of understanding visual details, and the retrieval accuracy is still limited by identity confusion. In order to alleviate the above problems, we rethink the importance of visual features for text-based person search, and propose VFE-TPS, a Visual Feature Enhanced Text-based Person Search model. It introduces a pre-trained multimodal backbone CLIP to learn basic multimodal features and constructs Text Guided Masked Image Modeling task to enhance the model's ability of learning local visual details without explicit annotation. In addition, we design Identity Supervised Global Visual Feature Calibration task to guide the model learn identity-aware global visual features. The key finding of our study is that, with the help of our proposed auxiliary tasks, the knowledge embedded in the pre-trained CLIP model can be successfully adapted to text-based person search task, and the model's visual understanding ability is significantly enhanced. Experimental results on three benchmarks demonstrate that our proposed model exceeds the existing approaches, and the Rank-1 accuracy is significantly improved with a notable margin of about $1\%\sim9\%$. Our code can be found at https://github.com/zhangweifeng1218/VFE_TPS.