 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
From 128K to 4M: Efficient Training of Ultra-Long Context Large Language Models
Apr 08, 2025Long-context capabilities are essential for a wide range of applications, including document and video understanding, in-context learning, and inference-time scaling, all of which require models to process and reason over long sequences of text and multimodal data. In this work, we introduce a efficient training recipe for building ultra-long context LLMs from aligned instruct model, pushing the boundaries of context lengths from 128K to 1M, 2M, and 4M tokens. Our approach leverages efficient continued pretraining strategies to extend the context window and employs effective instruction tuning to maintain the instruction-following and reasoning abilities. Our UltraLong-8B, built on Llama3.1-Instruct with our recipe, achieves state-of-the-art performance across a diverse set of long-context benchmarks. Importantly, models trained with our approach maintain competitive performance on standard benchmarks, demonstrating balanced improvements for both long and short context tasks. We further provide an in-depth analysis of key design choices, highlighting the impacts of scaling strategies and data composition. Our findings establish a robust framework for efficiently scaling context lengths while preserving general model capabilities. We release all model weights at: https://ultralong.github.io/.
Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
Mar 18, 2025Physical AI systems need to perceive, understand, and perform complex actions in the physical world. In this paper, we present the Cosmos-Reason1 models that can understand the physical world and generate appropriate embodied decisions (e.g., next step action) in natural language through long chain-of-thought reasoning processes. We begin by defining key capabilities for Physical AI reasoning, with a focus on physical common sense and embodied reasoning. To represent physical common sense, we use a hierarchical ontology that captures fundamental knowledge about space, time, and physics. For embodied reasoning, we rely on a two-dimensional ontology that generalizes across different physical embodiments. Building on these capabilities, we develop two multimodal large language models, Cosmos-Reason1-8B and Cosmos-Reason1-56B. We curate data and train our models in four stages: vision pre-training, general supervised fine-tuning (SFT), Physical AI SFT, and Physical AI reinforcement learning (RL) as the post-training. To evaluate our models, we build comprehensive benchmarks for physical common sense and embodied reasoning according to our ontologies. Evaluation results show that Physical AI SFT and reinforcement learning bring significant improvements. To facilitate the development of Physical AI, we will make our code and pre-trained models available under the NVIDIA Open Model License at https://github.com/nvidia-cosmos/cosmos-reason1.
Audio Flamingo 2: An Audio-Language Model with Long-Audio Understanding and Expert Reasoning Abilities
Mar 06, 2025Understanding and reasoning over non-speech sounds and music are crucial for both humans and AI agents to interact effectively with their environments. In this paper, we introduce Audio Flamingo 2 (AF2), an Audio-Language Model (ALM) with advanced audio understanding and reasoning capabilities. AF2 leverages (i) a custom CLAP model, (ii) synthetic Audio QA data for fine-grained audio reasoning, and (iii) a multi-stage curriculum learning strategy. AF2 achieves state-of-the-art performance with only a 3B parameter small language model, surpassing large open-source and proprietary models across over 20 benchmarks. Next, for the first time, we extend audio understanding to long audio segments (30 secs to 5 mins) and propose LongAudio, a large and novel dataset for training ALMs on long audio captioning and question-answering tasks. Fine-tuning AF2 on LongAudio leads to exceptional performance on our proposed LongAudioBench, an expert annotated benchmark for evaluating ALMs on long audio understanding capabilities. We conduct extensive ablation studies to confirm the efficacy of our approach. Project Website: https://research.nvidia.com/labs/adlr/AF2/.
AceMath: Advancing Frontier Math Reasoning with Post-Training and Reward Modeling
Dec 19, 2024



In this paper, we introduce AceMath, a suite of frontier math models that excel in solving complex math problems, along with highly effective reward models capable of evaluating generated solutions and reliably identifying the correct ones. To develop the instruction-tuned math models, we propose a supervised fine-tuning (SFT) process that first achieves competitive performance across general domains, followed by targeted fine-tuning for the math domain using a carefully curated set of prompts and synthetically generated responses. The resulting model, AceMath-72B-Instruct greatly outperforms Qwen2.5-Math-72B-Instruct, GPT-4o and Claude-3.5 Sonnet. To develop math-specialized reward model, we first construct AceMath-RewardBench, a comprehensive and robust benchmark for evaluating math reward models across diverse problems and difficulty levels. After that, we present a systematic approach to build our math reward models. The resulting model, AceMath-72B-RM, consistently outperforms state-of-the-art reward models. Furthermore, when combining AceMath-72B-Instruct with AceMath-72B-RM, we achieve the highest average rm@8 score across the math reasoning benchmarks. We will release model weights, training data, and evaluation benchmarks at: https://research.nvidia.com/labs/adlr/acemath
MM-Embed: Universal Multimodal Retrieval with Multimodal LLMs
Nov 04, 2024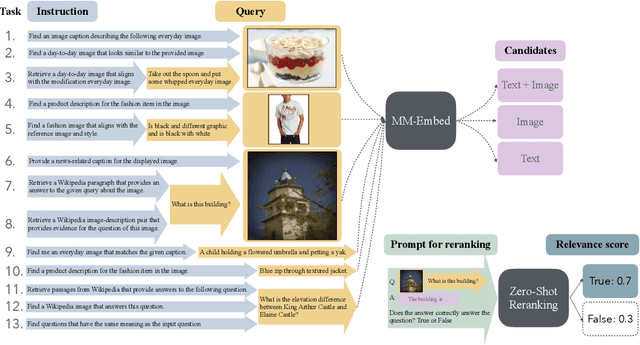
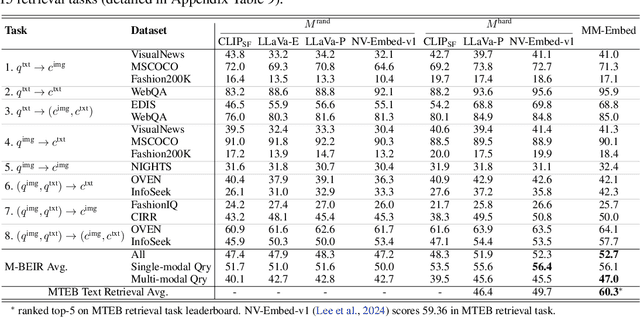
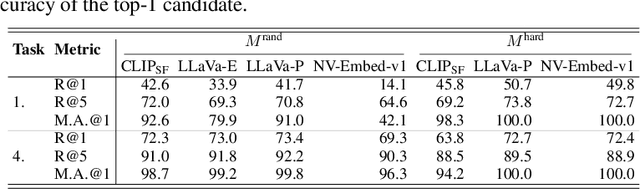

State-of-the-art retrieval models typically address a straightforward search scenario, where retrieval tasks are fixed (e.g., finding a passage to answer a specific question) and only a single modality is supported for both queries and retrieved results. This paper introduces techniques for advancing information retrieval with multimodal large language models (MLLMs), enabling a broader search scenario, termed universal multimodal retrieval, where multiple modalities and diverse retrieval tasks are accommodated. To this end, we first study fine-tuning an MLLM as a bi-encoder retriever on 10 datasets with 16 retrieval tasks. Our empirical results show that the fine-tuned MLLM retriever is capable of understanding challenging queries, composed of both text and image, but underperforms a smaller CLIP retriever in cross-modal retrieval tasks due to modality bias from MLLMs. To address the issue, we propose modality-aware hard negative mining to mitigate the modality bias exhibited by MLLM retrievers. Second, we propose to continually fine-tune the universal multimodal retriever to enhance its text retrieval capability while maintaining multimodal retrieval capability. As a result, our model, MM-Embed, achieves state-of-the-art performance on the multimodal retrieval benchmark M-BEIR, which spans multiple domains and tasks, while also surpassing the state-of-the-art text retrieval model, NV-Embed-v1, on MTEB retrieval benchmark. Finally, we explore to prompt the off-the-shelf MLLMs as the zero-shot rerankers to refine the ranking of the candidates from the multimodal retriever. We find that through prompt-and-reranking, MLLMs can further improve multimodal retrieval when the user queries (e.g., text-image composed queries) are more complex and challenging to understand. These findings also pave the way to advance universal multimodal retrieval in the future.
NVLM: Open Frontier-Class Multimodal LLMs
Sep 17, 2024



We introduce NVLM 1.0, a family of frontier-class multimodal large language models (LLMs) that achieve state-of-the-art results on vision-language tasks, rivaling the leading proprietary models (e.g., GPT-4o) and open-access models (e.g., Llama 3-V 405B and InternVL 2). Remarkably, NVLM 1.0 shows improved text-only performance over its LLM backbone after multimodal training. In terms of model design, we perform a comprehensive comparison between decoder-only multimodal LLMs (e.g., LLaVA) and cross-attention-based models (e.g., Flamingo). Based on the strengths and weaknesses of both approaches, we propose a novel architecture that enhances both training efficiency and multimodal reasoning capabilities. Furthermore, we introduce a 1-D tile-tagging design for tile-based dynamic high-resolution images, which significantly boosts performance on multimodal reasoning and OCR-related tasks. Regarding training data, we meticulously curate and provide detailed information on our multimodal pretraining and supervised fine-tuning datasets. Our findings indicate that dataset quality and task diversity are more important than scale, even during the pretraining phase, across all architectures. Notably, we develop production-grade multimodality for the NVLM-1.0 models, enabling them to excel in vision-language tasks while maintaining and even improving text-only performance compared to their LLM backbones. To achieve this, we craft and integrate a high-quality text-only dataset into multimodal training, alongside a substantial amount of multimodal math and reasoning data, leading to enhanced math and coding capabilities across modalities. To advance research in the field, we are releasing the model weights and will open-source the code for the community: https://nvlm-project.github.io/.
ChatQA 2: Bridging the Gap to Proprietary LLMs in Long Context and RAG Capabilities
Jul 19, 2024



In this work, we introduce ChatQA 2, a Llama3-based model designed to bridge the gap between open-access LLMs and leading proprietary models (e.g., GPT-4-Turbo) in long-context understanding and retrieval-augmented generation (RAG) capabilities. These two capabilities are essential for LLMs to process large volumes of information that cannot fit into a single prompt and are complementary to each other, depending on the downstream tasks and computational budgets. We present a detailed continued training recipe to extend the context window of Llama3-70B-base from 8K to 128K tokens, along with a three-stage instruction tuning process to enhance the model's instruction-following, RAG performance, and long-context understanding capabilities. Our results demonstrate that the Llama3-ChatQA-2-70B model achieves accuracy comparable to GPT-4-Turbo-2024-0409 on many long-context understanding tasks and surpasses it on the RAG benchmark. Interestingly, we find that the state-of-the-art long-context retriever can alleviate the top-k context fragmentation issue in RAG, further improving RAG-based results for long-context understanding tasks. We also provide extensive comparisons between RAG and long-context solutions using state-of-the-art long-context LLMs.
RankRAG: Unifying Context Ranking with Retrieval-Augmented Generation in LLMs
Jul 02, 2024



Large language models (LLMs) typically utilize the top-k contexts from a retriever in retrieval-augmented generation (RAG). In this work, we propose a novel instruction fine-tuning framework RankRAG, which instruction-tunes a single LLM for the dual purpose of context ranking and answer generation in RAG. In particular, the instruction-tuned LLMs work surprisingly well by adding a small fraction of ranking data into the training blend, and outperform existing expert ranking models, including the same LLM exclusively fine-tuned on a large amount of ranking data. For generation, we compare our model with many strong baselines, including GPT-4-0613, GPT-4-turbo-2024-0409, and ChatQA-1.5, an open-sourced model with the state-of-the-art performance on RAG benchmarks. Specifically, our Llama3-RankRAG significantly outperforms Llama3-ChatQA-1.5 and GPT-4 models on nine knowledge-intensive benchmarks. In addition, it also performs comparably to GPT-4 on five RAG benchmarks in the biomedical domain without instruction fine-tuning on biomedical data, demonstrating its superb capability for generalization to new domains.
Nemotron-4 340B Technical Report
Jun 17, 2024



We release the Nemotron-4 340B model family, including Nemotron-4-340B-Base, Nemotron-4-340B-Instruct, and Nemotron-4-340B-Reward. Our models are open access under the NVIDIA Open Model License Agreement, a permissive model license that allows distribution, modification, and use of the models and its outputs. These models perform competitively to open access models on a wide range of evaluation benchmarks, and were sized to fit on a single DGX H100 with 8 GPUs when deployed in FP8 precision. We believe that the community can benefit from these models in various research studies and commercial applications, especially for generating synthetic data to train smaller language models. Notably, over 98% of data used in our model alignment process is synthetically generated, showcasing the effectiveness of these models in generating synthetic data. To further support open research and facilitate model development, we are also open-sourcing the synthetic data generation pipeline used in our model alignment process.