 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
Nemotron-Cascade 2: Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation
Mar 19, 2026We introduce Nemotron-Cascade 2, an open 30B MoE model with 3B activated parameters that delivers best-in-class reasoning and strong agentic capabilities. Despite its compact size, its mathematical and coding reasoning performance approaches that of frontier open models. It is the second open-weight LLM, after DeepSeekV3.2-Speciale-671B-A37B, to achieve Gold Medal-level performance in the 2025 International Mathematical Olympiad (IMO), the International Olympiad in Informatics (IOI), and the ICPC World Finals, demonstrating remarkably high intelligence density with 20x fewer parameters. In contrast to Nemotron-Cascade 1, the key technical advancements are as follows. After SFT on a meticulously curated dataset, we substantially expand Cascade RL to cover a much broader spectrum of reasoning and agentic domains. Furthermore, we introduce multi-domain on-policy distillation from the strongest intermediate teacher models for each domain throughout the Cascade RL process, allowing us to efficiently recover benchmark regressions and sustain strong performance gains along the way. We release the collection of model checkpoint and training data.
Hidden costs for inference with deep network on embedded system devices
Jan 05, 2026This study evaluates the inference performance of various deep learning models under an embedded system environment. In previous works, Multiply-Accumulate operation is typically used to measure computational load of a deep model. According to this study, however, this metric has a limitation to estimate inference time on embedded devices. This paper poses the question of what aspects are overlooked when expressed in terms of Multiply-Accumulate operations. In experiments, an image classification task is performed on an embedded system device using the CIFAR-100 dataset to compare and analyze the inference times of ten deep models with the theoretically calculated Multiply-Accumulate operations for each model. The results highlight the importance of considering additional computations between tensors when optimizing deep learning models for real-time performing in embedded systems.
Nemotron-Cascade: Scaling Cascaded Reinforcement Learning for General-Purpose Reasoning Models
Dec 15, 2025



Building general-purpose reasoning models with reinforcement learning (RL) entails substantial cross-domain heterogeneity, including large variation in inference-time response lengths and verification latency. Such variability complicates the RL infrastructure, slows training, and makes training curriculum (e.g., response length extension) and hyperparameter selection challenging. In this work, we propose cascaded domain-wise reinforcement learning (Cascade RL) to develop general-purpose reasoning models, Nemotron-Cascade, capable of operating in both instruct and deep thinking modes. Departing from conventional approaches that blend heterogeneous prompts from different domains, Cascade RL orchestrates sequential, domain-wise RL, reducing engineering complexity and delivering state-of-the-art performance across a wide range of benchmarks. Notably, RLHF for alignment, when used as a pre-step, boosts the model's reasoning ability far beyond mere preference optimization, and subsequent domain-wise RLVR stages rarely degrade the benchmark performance attained in earlier domains and may even improve it (see an illustration in Figure 1). Our 14B model, after RL, outperforms its SFT teacher, DeepSeek-R1-0528, on LiveCodeBench v5/v6/Pro and achieves silver-medal performance in the 2025 International Olympiad in Informatics (IOI). We transparently share our training and data recipes.
AceReason-Nemotron 1.1: Advancing Math and Code Reasoning through SFT and RL Synergy
Jun 16, 2025In this work, we investigate the synergy between supervised fine-tuning (SFT) and reinforcement learning (RL) in developing strong reasoning models. We begin by curating the SFT training data through two scaling strategies: increasing the number of collected prompts and the number of generated responses per prompt. Both approaches yield notable improvements in reasoning performance, with scaling the number of prompts resulting in more substantial gains. We then explore the following questions regarding the synergy between SFT and RL: (i) Does a stronger SFT model consistently lead to better final performance after large-scale RL training? (ii) How can we determine an appropriate sampling temperature during RL training to effectively balance exploration and exploitation for a given SFT initialization? Our findings suggest that (i) holds true, provided effective RL training is conducted, particularly when the sampling temperature is carefully chosen to maintain the temperature-adjusted entropy around 0.3, a setting that strikes a good balance between exploration and exploitation. Notably, the performance gap between initial SFT models narrows significantly throughout the RL process. Leveraging a strong SFT foundation and insights into the synergistic interplay between SFT and RL, our AceReason-Nemotron-1.1 7B model significantly outperforms AceReason-Nemotron-1.0 and achieves new state-of-the-art performance among Qwen2.5-7B-based reasoning models on challenging math and code benchmarks, thereby demonstrating the effectiveness of our post-training recipe. We release the model and data at: https://huggingface.co/nvidia/AceReason-Nemotron-1.1-7B
AceReason-Nemotron: Advancing Math and Code Reasoning through Reinforcement Learning
May 22, 2025Despite recent progress in large-scale reinforcement learning (RL) for reasoning, the training recipe for building high-performing reasoning models remains elusive. Key implementation details of frontier models, such as DeepSeek-R1, including data curation strategies and RL training recipe, are often omitted. Moreover, recent research indicates distillation remains more effective than RL for smaller models. In this work, we demonstrate that large-scale RL can significantly enhance the reasoning capabilities of strong, small- and mid-sized models, achieving results that surpass those of state-of-the-art distillation-based models. We systematically study the RL training process through extensive ablations and propose a simple yet effective approach: first training on math-only prompts, then on code-only prompts. Notably, we find that math-only RL not only significantly enhances the performance of strong distilled models on math benchmarks (e.g., +14.6% / +17.2% on AIME 2025 for the 7B / 14B models), but also code reasoning tasks (e.g., +6.8% / +5.8% on LiveCodeBench for the 7B / 14B models). In addition, extended code-only RL iterations further improve performance on code benchmarks with minimal or no degradation in math results. We develop a robust data curation pipeline to collect challenging prompts with high-quality, verifiable answers and test cases to enable verification-based RL across both domains. Finally, we identify key experimental insights, including curriculum learning with progressively increasing response lengths and the stabilizing effect of on-policy parameter updates. We find that RL not only elicits the foundational reasoning capabilities acquired during pretraining and supervised fine-tuning (e.g., distillation), but also pushes the limits of the model's reasoning ability, enabling it to solve problems that were previously unsolvable.
MM-Embed: Universal Multimodal Retrieval with Multimodal LLMs
Nov 04, 2024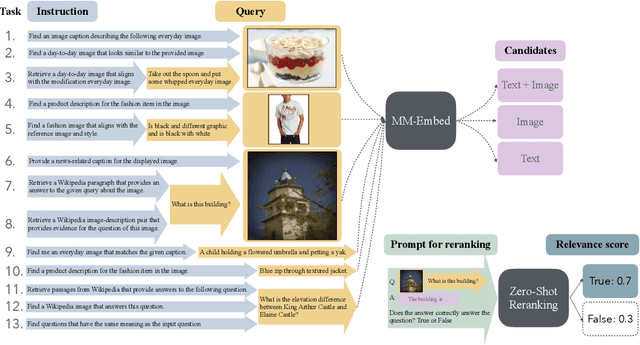
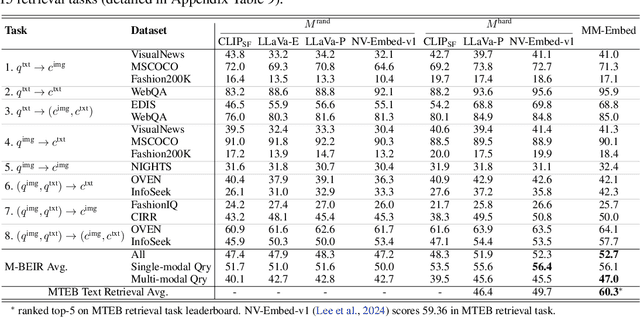
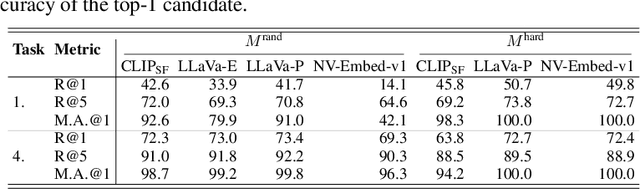

State-of-the-art retrieval models typically address a straightforward search scenario, where retrieval tasks are fixed (e.g., finding a passage to answer a specific question) and only a single modality is supported for both queries and retrieved results. This paper introduces techniques for advancing information retrieval with multimodal large language models (MLLMs), enabling a broader search scenario, termed universal multimodal retrieval, where multiple modalities and diverse retrieval tasks are accommodated. To this end, we first study fine-tuning an MLLM as a bi-encoder retriever on 10 datasets with 16 retrieval tasks. Our empirical results show that the fine-tuned MLLM retriever is capable of understanding challenging queries, composed of both text and image, but underperforms a smaller CLIP retriever in cross-modal retrieval tasks due to modality bias from MLLMs. To address the issue, we propose modality-aware hard negative mining to mitigate the modality bias exhibited by MLLM retrievers. Second, we propose to continually fine-tune the universal multimodal retriever to enhance its text retrieval capability while maintaining multimodal retrieval capability. As a result, our model, MM-Embed, achieves state-of-the-art performance on the multimodal retrieval benchmark M-BEIR, which spans multiple domains and tasks, while also surpassing the state-of-the-art text retrieval model, NV-Embed-v1, on MTEB retrieval benchmark. Finally, we explore to prompt the off-the-shelf MLLMs as the zero-shot rerankers to refine the ranking of the candidates from the multimodal retriever. We find that through prompt-and-reranking, MLLMs can further improve multimodal retrieval when the user queries (e.g., text-image composed queries) are more complex and challenging to understand. These findings also pave the way to advance universal multimodal retrieval in the future.
NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models
May 27, 2024



Decoder-only large language model (LLM)-based embedding models are beginning to outperform BERT or T5-based embedding models in general-purpose text embedding tasks, including dense vector-based retrieval. In this work, we introduce the NV-Embed model with a variety of architectural designs and training procedures to significantly enhance the performance of LLM as a versatile embedding model, while maintaining its simplicity and reproducibility. For model architecture, we propose a latent attention layer to obtain pooled embeddings, which consistently improves retrieval and downstream task accuracy compared to mean pooling or using the last <EOS> token embedding from LLMs. To enhance representation learning, we remove the causal attention mask of LLMs during contrastive training. For model training, we introduce a two-stage contrastive instruction-tuning method. It first applies contrastive training with instructions on retrieval datasets, utilizing in-batch negatives and curated hard negative examples. At stage-2, it blends various non-retrieval datasets into instruction tuning, which not only enhances non-retrieval task accuracy but also improves retrieval performance. Combining these techniques, our NV-Embed model, using only publicly available data, has achieved a record-high score of 69.32, ranking No. 1 on the Massive Text Embedding Benchmark (MTEB) (as of May 24, 2024), with 56 tasks, encompassing retrieval, reranking, classification, clustering, and semantic textual similarity tasks. Notably, our model also attains the highest score of 59.36 on 15 retrieval tasks in the MTEB benchmark (also known as BEIR). We will open-source the model at: https://huggingface.co/nvidia/NV-Embed-v1.
ChatQA: Building GPT-4 Level Conversational QA Models
Jan 23, 2024



In this work, we introduce ChatQA, a family of conversational question answering (QA) models that obtain GPT-4 level accuracies. Specifically, we propose a two-stage instruction tuning method that can significantly improve the zero-shot conversational QA results from large language models (LLMs). To handle retrieval-augmented generation in conversational QA, we fine-tune a dense retriever on a multi-turn QA dataset, which provides comparable results to using the state-of-the-art query rewriting model while largely reducing deployment cost. Notably, our ChatQA-70B can outperform GPT-4 in terms of average score on 10 conversational QA datasets (54.14 vs. 53.90), without relying on any synthetic data from OpenAI GPT models.
Fusion-FlowNet: Energy-Efficient Optical Flow Estimation using Sensor Fusion and Deep Fused Spiking-Analog Network Architectures
Mar 19, 2021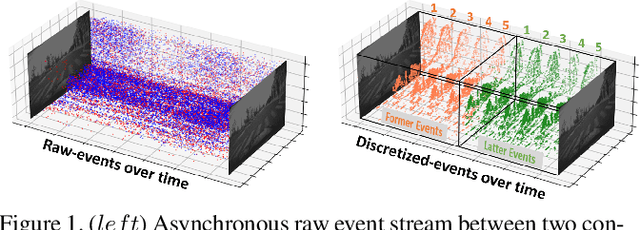
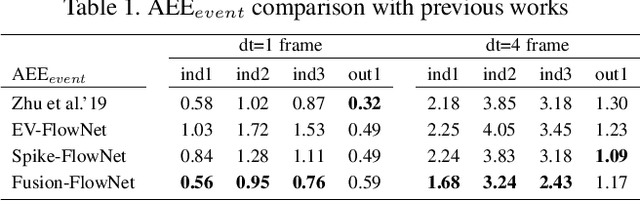
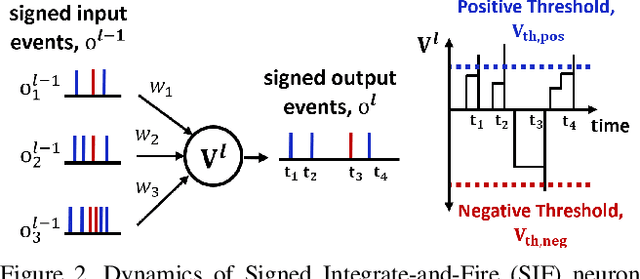
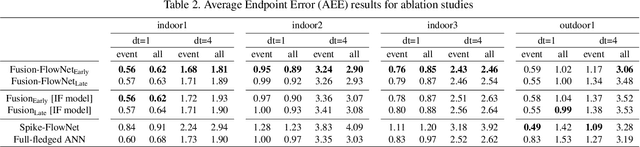
Standard frame-based cameras that sample light intensity frames are heavily impacted by motion blur for high-speed motion and fail to perceive scene accurately when the dynamic range is high. Event-based cameras, on the other hand, overcome these limitations by asynchronously detecting the variation in individual pixel intensities. However, event cameras only provide information about pixels in motion, leading to sparse data. Hence, estimating the overall dense behavior of pixels is difficult. To address such issues associated with the sensors, we present Fusion-FlowNet, a sensor fusion framework for energy-efficient optical flow estimation using both frame- and event-based sensors, leveraging their complementary characteristics. Our proposed network architecture is also a fusion of Spiking Neural Networks (SNNs) and Analog Neural Networks (ANNs) where each network is designed to simultaneously process asynchronous event streams and regular frame-based images, respectively. Our network is end-to-end trained using unsupervised learning to avoid expensive video annotations. The method generalizes well across distinct environments (rapid motion and challenging lighting conditions) and demonstrates state-of-the-art optical flow prediction on the Multi-Vehicle Stereo Event Camera (MVSEC) dataset. Furthermore, our network offers substantial savings in terms of the number of network parameters and computational energy cost.