 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Flamingo Next: Next-Generation Open Audio-Language Models for Speech, Sound, and Music
Apr 13, 2026We present Audio Flamingo Next (AF-Next), the next-generation and most capable large audio-language model in the Audio Flamingo series, designed to advance understanding and reasoning over speech, environmental sounds and music. Compared to Audio Flamingo 3, AF-Next introduces: (i) a stronger foundational audio-language model that significantly improves accuracy across diverse audio understanding tasks; (ii) scalable strategies for constructing large-scale audio understanding and reasoning data beyond existing academic benchmarks; (iii) support for long and complex audio inputs up to 30 minutes; and (iv) Temporal Audio Chain-of-Thought, a new reasoning paradigm that explicitly grounds intermediate reasoning steps to timestamps in long audio, enabling fine-grained temporal alignment and improved interpretability. To enable these capabilities, we first conduct a systematic analysis of Audio Flamingo 3 to identify key gaps in audio understanding and reasoning. We then curate and scale new large-scale datasets totaling over 1 million hours to address these limitations and expand the existing AudioSkills-XL, LongAudio-XL, AF-Think and AF-Chat datasets. AF-Next is trained using a curriculum-based strategy spanning pre-training, mid-training and post-training stages. Extensive experiments across 20 audio understanding and reasoning benchmarks, including challenging long-audio tasks, show that AF-Next outperforms similarly sized open models by large margins and remains highly competitive with and sometimes surpasses, much larger open-weight and closed models. Beyond benchmark performance, AF-Next exhibits strong real-world utility and transfers well to unseen tasks, highlighting its robustness and generalization ability. In addition to all data, code and methods, we open-source 3 variants of AF-Next, including AF-Next-Instruct, AF-Next-Think and AF-Next-Captioner.
Miniature Testbed for Validating Multi-Agent Cooperative Autonomous Driving
Nov 14, 2025



Cooperative autonomous driving, which extends vehicle autonomy by enabling real-time collaboration between vehicles and smart roadside infrastructure, remains a challenging yet essential problem. However, none of the existing testbeds employ smart infrastructure equipped with sensing, edge computing, and communication capabilities. To address this gap, we design and implement a 1:15-scale miniature testbed, CIVAT, for validating cooperative autonomous driving, consisting of a scaled urban map, autonomous vehicles with onboard sensors, and smart infrastructure. The proposed testbed integrates V2V and V2I communication with the publish-subscribe pattern through a shared Wi-Fi and ROS2 framework, enabling information exchange between vehicles and infrastructure to realize cooperative driving functionality. As a case study, we validate the system through infrastructure-based perception and intersection management experiments.
How to Move Your Dragon: Text-to-Motion Synthesis for Large-Vocabulary Objects
Mar 06, 2025



Motion synthesis for diverse object categories holds great potential for 3D content creation but remains underexplored due to two key challenges: (1) the lack of comprehensive motion datasets that include a wide range of high-quality motions and annotations, and (2) the absence of methods capable of handling heterogeneous skeletal templates from diverse objects. To address these challenges, we contribute the following: First, we augment the Truebones Zoo dataset, a high-quality animal motion dataset covering over 70 species, by annotating it with detailed text descriptions, making it suitable for text-based motion synthesis. Second, we introduce rig augmentation techniques that generate diverse motion data while preserving consistent dynamics, enabling models to adapt to various skeletal configurations. Finally, we redesign existing motion diffusion models to dynamically adapt to arbitrary skeletal templates, enabling motion synthesis for a diverse range of objects with varying structures. Experiments show that our method learns to generate high-fidelity motions from textual descriptions for diverse and even unseen objects, setting a strong foundation for motion synthesis across diverse object categories and skeletal templates. Qualitative results are available on this link: t2m4lvo.github.io
Audio Flamingo 2: An Audio-Language Model with Long-Audio Understanding and Expert Reasoning Abilities
Mar 06, 2025



Understanding and reasoning over non-speech sounds and music are crucial for both humans and AI agents to interact effectively with their environments. In this paper, we introduce Audio Flamingo 2 (AF2), an Audio-Language Model (ALM) with advanced audio understanding and reasoning capabilities. AF2 leverages (i) a custom CLAP model, (ii) synthetic Audio QA data for fine-grained audio reasoning, and (iii) a multi-stage curriculum learning strategy. AF2 achieves state-of-the-art performance with only a 3B parameter small language model, surpassing large open-source and proprietary models across over 20 benchmarks. Next, for the first time, we extend audio understanding to long audio segments (30 secs to 5 mins) and propose LongAudio, a large and novel dataset for training ALMs on long audio captioning and question-answering tasks. Fine-tuning AF2 on LongAudio leads to exceptional performance on our proposed LongAudioBench, an expert annotated benchmark for evaluating ALMs on long audio understanding capabilities. We conduct extensive ablation studies to confirm the efficacy of our approach. Project Website: https://research.nvidia.com/labs/adlr/AF2/.
Efficient Generative Modeling with Residual Vector Quantization-Based Tokens
Dec 13, 2024



We explore the use of Residual Vector Quantization (RVQ) for high-fidelity generation in vector-quantized generative models. This quantization technique maintains higher data fidelity by employing more in-depth tokens. However, increasing the token number in generative models leads to slower inference speeds. To this end, we introduce ResGen, an efficient RVQ-based discrete diffusion model that generates high-fidelity samples without compromising sampling speed. Our key idea is a direct prediction of vector embedding of collective tokens rather than individual ones. Moreover, we demonstrate that our proposed token masking and multi-token prediction method can be formulated within a principled probabilistic framework using a discrete diffusion process and variational inference. We validate the efficacy and generalizability of the proposed method on two challenging tasks across different modalities: conditional image generation} on ImageNet 256x256 and zero-shot text-to-speech synthesis. Experimental results demonstrate that ResGen outperforms autoregressive counterparts in both tasks, delivering superior performance without compromising sampling speed. Furthermore, as we scale the depth of RVQ, our generative models exhibit enhanced generation fidelity or faster sampling speeds compared to similarly sized baseline models. The project page can be found at https://resgen-genai.github.io
Practical and Reproducible Symbolic Music Generation by Large Language Models with Structural Embeddings
Jul 29, 2024



Music generation introduces challenging complexities to large language models. Symbolic structures of music often include vertical harmonization as well as horizontal counterpoint, urging various adaptations and enhancements for large-scale Transformers. However, existing works share three major drawbacks: 1) their tokenization requires domain-specific annotations, such as bars and beats, that are typically missing in raw MIDI data; 2) the pure impact of enhancing token embedding methods is hardly examined without domain-specific annotations; and 3) existing works to overcome the aforementioned drawbacks, such as MuseNet, lack reproducibility. To tackle such limitations, we develop a MIDI-based music generation framework inspired by MuseNet, empirically studying two structural embeddings that do not rely on domain-specific annotations. We provide various metrics and insights that can guide suitable encoding to deploy. We also verify that multiple embedding configurations can selectively boost certain musical aspects. By providing open-source implementations via HuggingFace, our findings shed light on leveraging large language models toward practical and reproducible music generation.
DiTTo-TTS: Efficient and Scalable Zero-Shot Text-to-Speech with Diffusion Transformer
Jun 17, 2024Large-scale diffusion models have shown outstanding generative abilities across multiple modalities including images, videos, and audio. However, text-to-speech (TTS) systems typically involve domain-specific modeling factors (e.g., phonemes and phoneme-level durations) to ensure precise temporal alignments between text and speech, which hinders the efficiency and scalability of diffusion models for TTS. In this work, we present an efficient and scalable Diffusion Transformer (DiT) that utilizes off-the-shelf pre-trained text and speech encoders. Our approach addresses the challenge of text-speech alignment via cross-attention mechanisms with the prediction of the total length of speech representations. To achieve this, we enhance the DiT architecture to suit TTS and improve the alignment by incorporating semantic guidance into the latent space of speech. We scale the training dataset and the model size to 82K hours and 790M parameters, respectively. Our extensive experiments demonstrate that the large-scale diffusion model for TTS without domain-specific modeling not only simplifies the training pipeline but also yields superior or comparable zero-shot performance to state-of-the-art TTS models in terms of naturalness, intelligibility, and speaker similarity. Our speech samples are available at https://ditto-tts.github.io.
CLaM-TTS: Improving Neural Codec Language Model for Zero-Shot Text-to-Speech
Apr 03, 2024



With the emergence of neural audio codecs, which encode multiple streams of discrete tokens from audio, large language models have recently gained attention as a promising approach for zero-shot Text-to-Speech (TTS) synthesis. Despite the ongoing rush towards scaling paradigms, audio tokenization ironically amplifies the scalability challenge, stemming from its long sequence length and the complexity of modelling the multiple sequences. To mitigate these issues, we present CLaM-TTS that employs a probabilistic residual vector quantization to (1) achieve superior compression in the token length, and (2) allow a language model to generate multiple tokens at once, thereby eliminating the need for cascaded modeling to handle the number of token streams. Our experimental results demonstrate that CLaM-TTS is better than or comparable to state-of-the-art neural codec-based TTS models regarding naturalness, intelligibility, speaker similarity, and inference speed. In addition, we examine the impact of the pretraining extent of the language models and their text tokenization strategies on performances.
Progressive Deblurring of Diffusion Models for Coarse-to-Fine Image Synthesis
Jul 16, 2022

Recently, diffusion models have shown remarkable results in image synthesis by gradually removing noise and amplifying signals. Although the simple generative process surprisingly works well, is this the best way to generate image data? For instance, despite the fact that human perception is more sensitive to the low frequencies of an image, diffusion models themselves do not consider any relative importance of each frequency component. Therefore, to incorporate the inductive bias for image data, we propose a novel generative process that synthesizes images in a coarse-to-fine manner. First, we generalize the standard diffusion models by enabling diffusion in a rotated coordinate system with different velocities for each component of the vector. We further propose a blur diffusion as a special case, where each frequency component of an image is diffused at different speeds. Specifically, the proposed blur diffusion consists of a forward process that blurs an image and adds noise gradually, after which a corresponding reverse process deblurs an image and removes noise progressively. Experiments show that the proposed model outperforms the previous method in FID on LSUN bedroom and church datasets. Code is available at https://github.com/sangyun884/blur-diffusion.
Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
Jun 11, 2021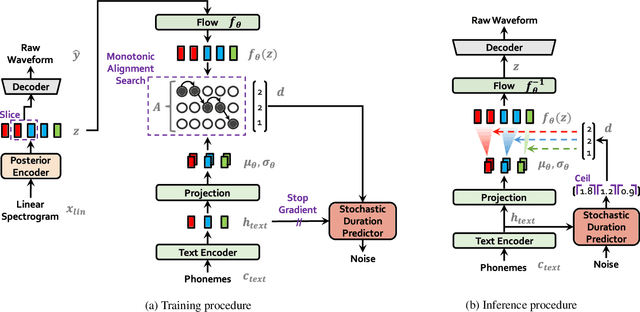
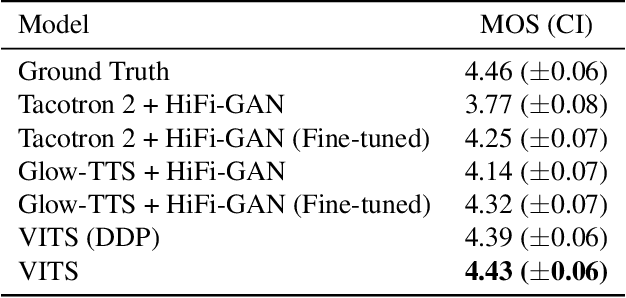

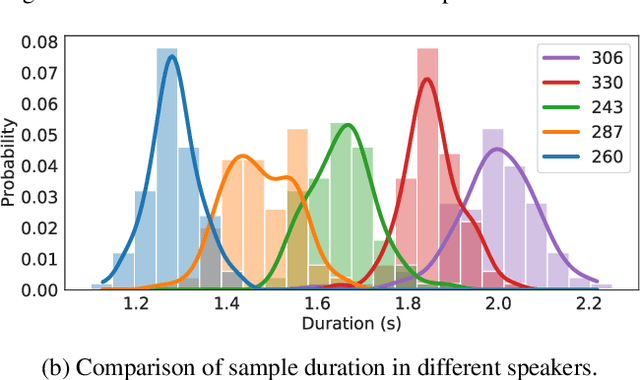
Several recent end-to-end text-to-speech (TTS) models enabling single-stage training and parallel sampling have been proposed, but their sample quality does not match that of two-stage TTS systems. In this work, we present a parallel end-to-end TTS method that generates more natural sounding audio than current two-stage models. Our method adopts variational inference augmented with normalizing flows and an adversarial training process, which improves the expressive power of generative modeling. We also propose a stochastic duration predictor to synthesize speech with diverse rhythms from input text. With the uncertainty modeling over latent variables and the stochastic duration predictor, our method expresses the natural one-to-many relationship in which a text input can be spoken in multiple ways with different pitches and rhythms. A subjective human evaluation (mean opinion score, or MOS) on the LJ Speech, a single speaker dataset, shows that our method outperforms the best publicly available TTS systems and achieves a MOS comparable to ground truth.