 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeODMA: On-Demand Memory Allocation Framework for LLM Serving on LPDDR-Class Accelerators
Dec 10, 2025Serving large language models (LLMs) on accelerators with poor random-access bandwidth (e.g., LPDDR5-based) is limited by current memory managers. Static pre-allocation wastes memory, while fine-grained paging (e.g., PagedAttention) is ill-suited due to high random-access costs. Existing HBM-centric solutions do not exploit the characteristics of random-access-constrained memory (RACM) accelerators like Cambricon MLU370. We present ODMA, an on-demand memory allocation framework for RACM. ODMA addresses distribution drift and heavy-tailed requests by coupling a lightweight length predictor with dynamic bucket partitioning and a large-bucket safeguard. Boundaries are periodically updated from live traces to maximize utilization. On Alpaca and Google-NQ, ODMA improves prediction accuracy of prior work significantly (e.g., from 82.68% to 93.36%). Serving DeepSeek-R1-Distill-Qwen-7B on Cambricon MLU370-X4, ODMA raises memory utilization from 55.05% to 72.45% and improves RPS and TPS by 29% and 27% over static baselines. This demonstrates that hardware-aware allocation unlocks efficient LLM serving on RACM platforms.
Millisecond-Response Tracking and Gazing System for UAVs: A Domestic Solution Based on "Phytium + Cambricon"
Sep 04, 2025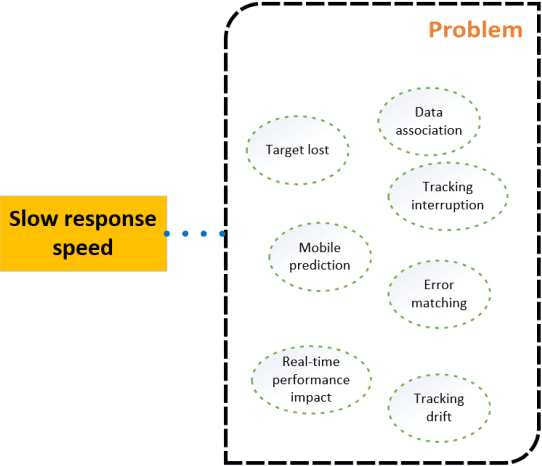

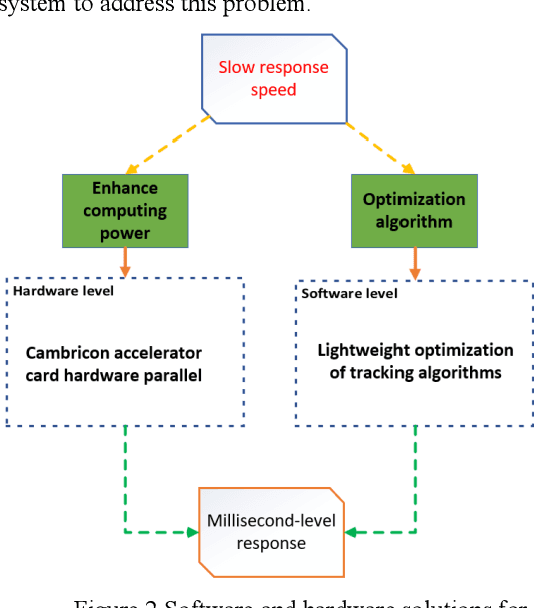

In the frontier research and application of current video surveillance technology, traditional camera systems exhibit significant limitations of response delay exceeding 200 ms in dynamic scenarios due to the insufficient deep feature extraction capability of automatic recognition algorithms and the efficiency bottleneck of computing architectures, failing to meet the real-time requirements in complex scenes. To address this issue, this study proposes a heterogeneous computing architecture based on Phytium processors and Cambricon accelerator cards, constructing a UAV tracking and gazing system with millisecond-level response capability. At the hardware level, the system adopts a collaborative computing architecture of Phytium FT-2000/4 processors and MLU220 accelerator cards, enhancing computing power through multi-card parallelism. At the software level, it innovatively integrates a lightweight YOLOv5s detection network with a DeepSORT cascaded tracking algorithm, forming a closed-loop control chain of "detection-tracking-feedback". Experimental results demonstrate that the system achieves a stable single-frame comprehensive processing delay of 50-100 ms in 1920*1080 resolution video stream processing, with a multi-scale target recognition accuracy of over 98.5%, featuring both low latency and high precision. This study provides an innovative solution for UAV monitoring and the application of domestic chips.
KAITIAN: A Unified Communication Framework for Enabling Efficient Collaboration Across Heterogeneous Accelerators in Embodied AI Systems
May 15, 2025



Embodied Artificial Intelligence (AI) systems, such as autonomous robots and intelligent vehicles, are increasingly reliant on diverse heterogeneous accelerators (e.g., GPGPUs, NPUs, FPGAs) to meet stringent real-time processing and energy-efficiency demands. However, the proliferation of vendor-specific proprietary communication libraries creates significant interoperability barriers, hindering seamless collaboration between different accelerator types and leading to suboptimal resource utilization and performance bottlenecks in distributed AI workloads. This paper introduces KAITIAN, a novel distributed communication framework designed to bridge this gap. KAITIAN provides a unified abstraction layer that intelligently integrates vendor-optimized communication libraries for intra-group efficiency with general-purpose communication protocols for inter-group interoperability. Crucially, it incorporates a load-adaptive scheduling mechanism that dynamically balances computational tasks across heterogeneous devices based on their real-time performance characteristics. Implemented as an extension to PyTorch and rigorously evaluated on a testbed featuring NVIDIA GPUs and Cambricon MLUs, KAITIAN demonstrates significant improvements in resource utilization and scalability for distributed training tasks. Experimental results show that KAITIAN can accelerate training time by up to 42% compared to baseline homogeneous systems, while incurring minimal communication overhead (2.8--4.3%) and maintaining model accuracy. KAITIAN paves the way for more flexible and powerful heterogeneous computing in complex embodied AI applications.