 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Self-Reinforcement for Improving Learnersourced Multiple-Choice Question Explanations with Large Language Models
Sep 19, 2023



Learnersourcing involves students generating and sharing learning resources with their peers. When learnersourcing multiple-choice questions, creating explanations for the generated questions is a crucial step as it facilitates a deeper understanding of the related concepts. However, it is often difficult for students to craft effective explanations due to limited subject understanding and a tendency to merely restate the question stem, distractors, and correct answer. To help scaffold this task, in this work we propose a self-reinforcement large-language-model framework, with the goal of generating and evaluating explanations automatically. Comprising three modules, the framework generates student-aligned explanations, evaluates these explanations to ensure their quality and iteratively enhances the explanations. If an explanation's evaluation score falls below a defined threshold, the framework iteratively refines and reassesses the explanation. Importantly, our framework emulates the manner in which students compose explanations at the relevant grade level. For evaluation, we had a human subject-matter expert compare the explanations generated by students with the explanations created by the open-source large language model Vicuna-13B, a version of Vicuna-13B that had been fine-tuned using our method, and by GPT-4. We observed that, when compared to other large language models, GPT-4 exhibited a higher level of creativity in generating explanations. We also found that explanations generated by GPT-4 were ranked higher by the human expert than both those created by the other models and the original student-created explanations. Our findings represent a significant advancement in enriching the learnersourcing experience for students and enhancing the capabilities of large language models in educational applications.
Aligning Large Language Models with Human: A Survey
Jul 24, 2023Large Language Models (LLMs) trained on extensive textual corpora have emerged as leading solutions for a broad array of Natural Language Processing (NLP) tasks. Despite their notable performance, these models are prone to certain limitations such as misunderstanding human instructions, generating potentially biased content, or factually incorrect (hallucinated) information. Hence, aligning LLMs with human expectations has become an active area of interest within the research community. This survey presents a comprehensive overview of these alignment technologies, including the following aspects. (1) Data collection: the methods for effectively collecting high-quality instructions for LLM alignment, including the use of NLP benchmarks, human annotations, and leveraging strong LLMs. (2) Training methodologies: a detailed review of the prevailing training methods employed for LLM alignment. Our exploration encompasses Supervised Fine-tuning, both Online and Offline human preference training, along with parameter-efficient training mechanisms. (3) Model Evaluation: the methods for evaluating the effectiveness of these human-aligned LLMs, presenting a multifaceted approach towards their assessment. In conclusion, we collate and distill our findings, shedding light on several promising future research avenues in the field. This survey, therefore, serves as a valuable resource for anyone invested in understanding and advancing the alignment of LLMs to better suit human-oriented tasks and expectations. An associated GitHub link collecting the latest papers is available at https://github.com/GaryYufei/AlignLLMHumanSurvey.
GroundNLQ @ Ego4D Natural Language Queries Challenge 2023
Jun 27, 2023



In this report, we present our champion solution for Ego4D Natural Language Queries (NLQ) Challenge in CVPR 2023. Essentially, to accurately ground in a video, an effective egocentric feature extractor and a powerful grounding model are required. Motivated by this, we leverage a two-stage pre-training strategy to train egocentric feature extractors and the grounding model on video narrations, and further fine-tune the model on annotated data. In addition, we introduce a novel grounding model GroundNLQ, which employs a multi-modal multi-scale grounding module for effective video and text fusion and various temporal intervals, especially for long videos. On the blind test set, GroundNLQ achieves 25.67 and 18.18 for R1@IoU=0.3 and R1@IoU=0.5, respectively, and surpasses all other teams by a noticeable margin. Our code will be released at\url{https://github.com/houzhijian/GroundNLQ}.
MemoryBank: Enhancing Large Language Models with Long-Term Memory
May 21, 2023



Revolutionary advancements in Large Language Models have drastically reshaped our interactions with artificial intelligence systems. Despite this, a notable hindrance remains-the deficiency of a long-term memory mechanism within these models. This shortfall becomes increasingly evident in situations demanding sustained interaction, such as personal companion systems and psychological counseling. Therefore, we propose MemoryBank, a novel memory mechanism tailored for LLMs. MemoryBank enables the models to summon relevant memories, continually evolve through continuous memory updates, comprehend, and adapt to a user personality by synthesizing information from past interactions. To mimic anthropomorphic behaviors and selectively preserve memory, MemoryBank incorporates a memory updating mechanism, inspired by the Ebbinghaus Forgetting Curve theory, which permits the AI to forget and reinforce memory based on time elapsed and the relative significance of the memory, thereby offering a human-like memory mechanism. MemoryBank is versatile in accommodating both closed-source models like ChatGPT and open-source models like ChatGLM. We exemplify application of MemoryBank through the creation of an LLM-based chatbot named SiliconFriend in a long-term AI Companion scenario. Further tuned with psychological dialogs, SiliconFriend displays heightened empathy in its interactions. Experiment involves both qualitative analysis with real-world user dialogs and quantitative analysis with simulated dialogs. In the latter, ChatGPT acts as users with diverse characteristics and generates long-term dialog contexts covering a wide array of topics. The results of our analysis reveal that SiliconFriend, equipped with MemoryBank, exhibits a strong capability for long-term companionship as it can provide emphatic response, recall relevant memories and understand user personality.
Contrastive Learning with Logic-driven Data Augmentation for Logical Reasoning over Text
May 21, 2023Pre-trained large language model (LLM) is under exploration to perform NLP tasks that may require logical reasoning. Logic-driven data augmentation for representation learning has been shown to improve the performance of tasks requiring logical reasoning, but most of these data rely on designed templates and therefore lack generalization. In this regard, we propose an AMR-based logical equivalence-driven data augmentation method (AMR-LE) for generating logically equivalent data. Specifically, we first parse a text into the form of an AMR graph, next apply four logical equivalence laws (contraposition, double negation, commutative and implication laws) on the AMR graph to construct a logically equivalent/inequivalent AMR graph, and then convert it into a logically equivalent/inequivalent sentence. To help the model to better learn these logical equivalence laws, we propose a logical equivalence-driven contrastive learning training paradigm, which aims to distinguish the difference between logical equivalence and inequivalence. Our AMR-LE (Ensemble) achieves #2 on the ReClor leaderboard https://eval.ai/web/challenges/challenge-page/503/leaderboard/1347 . Our model shows better performance on seven downstream tasks, including ReClor, LogiQA, MNLI, MRPC, RTE, QNLI, and QQP. The source code and dataset are public at https://github.com/Strong-AI-Lab/Logical-Equivalence-driven-AMR-Data-Augmentation-for-Representation-Learning .
AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models
Apr 13, 2023Evaluating the general abilities of foundation models to tackle human-level tasks is a vital aspect of their development and application in the pursuit of Artificial General Intelligence (AGI). Traditional benchmarks, which rely on artificial datasets, may not accurately represent human-level capabilities. In this paper, we introduce AGIEval, a novel benchmark specifically designed to assess foundation model in the context of human-centric standardized exams, such as college entrance exams, law school admission tests, math competitions, and lawyer qualification tests. We evaluate several state-of-the-art foundation models, including GPT-4, ChatGPT, and Text-Davinci-003, using this benchmark. Impressively, GPT-4 surpasses average human performance on SAT, LSAT, and math competitions, attaining a 95% accuracy rate on the SAT Math test and a 92.5% accuracy on the English test of the Chinese national college entrance exam. This demonstrates the extraordinary performance of contemporary foundation models. In contrast, we also find that GPT-4 is less proficient in tasks that require complex reasoning or specific domain knowledge. Our comprehensive analyses of model capabilities (understanding, knowledge, reasoning, and calculation) reveal these models' strengths and limitations, providing valuable insights into future directions for enhancing their general capabilities. By concentrating on tasks pertinent to human cognition and decision-making, our benchmark delivers a more meaningful and robust evaluation of foundation models' performance in real-world scenarios. The data, code, and all model outputs are released in https://github.com/microsoft/AGIEval.
An Efficient COarse-to-fiNE Alignment Framework @ Ego4D Natural Language Queries Challenge 2022
Nov 16, 2022



This technical report describes the CONE approach for Ego4D Natural Language Queries (NLQ) Challenge in ECCV 2022. We leverage our model CONE, an efficient window-centric COarse-to-fiNE alignment framework. Specifically, CONE dynamically slices the long video into candidate windows via a sliding window approach. Centering at windows, CONE (1) learns the inter-window (coarse-grained) semantic variance through contrastive learning and speeds up inference by pre-filtering the candidate windows relevant to the NL query, and (2) conducts intra-window (fine-grained) candidate moments ranking utilizing the powerful multi-modal alignment ability of the contrastive vision-text pre-trained model EgoVLP. On the blind test set, CONE achieves 15.26 and 9.24 for R1@IoU=0.3 and R1@IoU=0.5, respectively.
Disentangling Reasoning Capabilities from Language Models with Compositional Reasoning Transformers
Oct 20, 2022
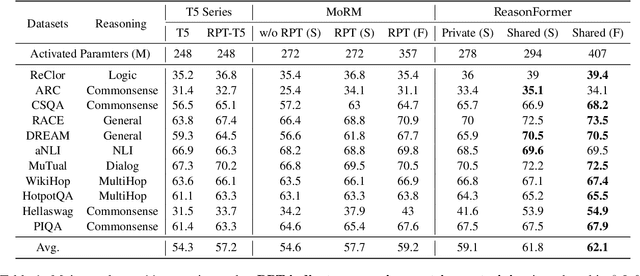
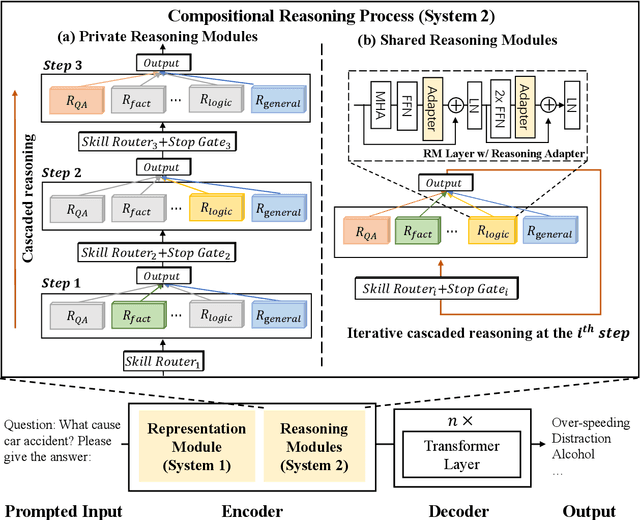
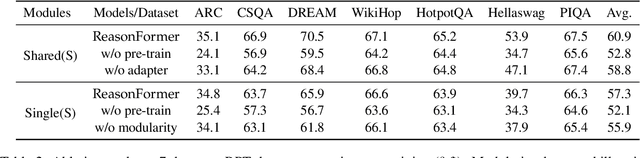
This paper presents ReasonFormer, a unified reasoning framework for mirroring the modular and compositional reasoning process of humans in complex decision making. Inspired by dual-process theory in cognitive science, the representation module (automatic thinking) and reasoning modules (controlled thinking) are disentangled to capture different levels of cognition. Upon the top of the representation module, the pre-trained reasoning modules are modular and expertise in specific and fundamental reasoning skills (e.g., logic, simple QA, etc). To mimic the controlled compositional thinking process, different reasoning modules are dynamically activated and composed in both parallel and cascaded manners to control what reasoning skills are activated and how deep the reasoning process will be reached to solve the current problems. The unified reasoning framework solves multiple tasks with a single model,and is trained and inferred in an end-to-end manner. Evaluated on 11 datasets requiring different reasoning skills and complexity, ReasonFormer demonstrates substantial performance boosts, revealing the compositional reasoning ability. Few-shot experiments exhibit better generalization ability by learning to compose pre-trained skills for new tasks with limited data,and decoupling the representation module and the reasoning modules. Further analysis shows the modularity of reasoning modules as different tasks activate distinct reasoning skills at different reasoning depths.
Mixed-modality Representation Learning and Pre-training for Joint Table-and-Text Retrieval in OpenQA
Oct 11, 2022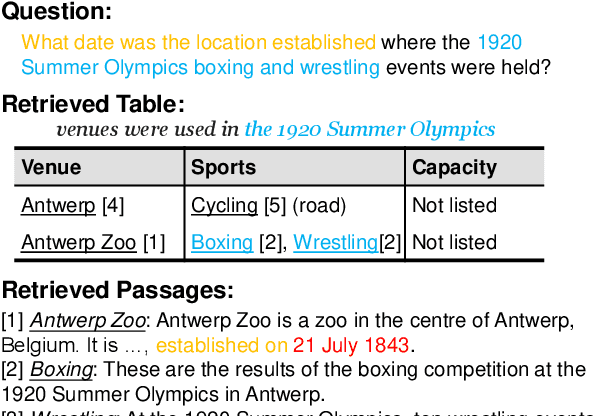

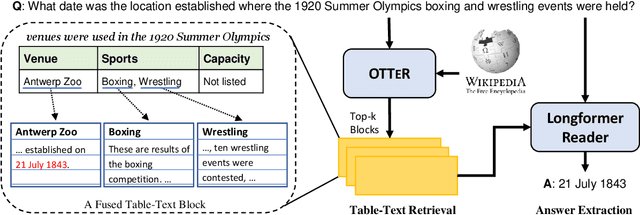
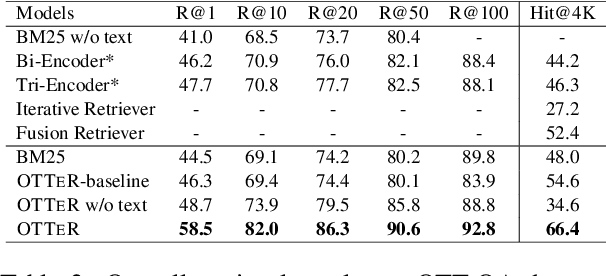
Retrieving evidences from tabular and textual resources is essential for open-domain question answering (OpenQA), which provides more comprehensive information. However, training an effective dense table-text retriever is difficult due to the challenges of table-text discrepancy and data sparsity problem. To address the above challenges, we introduce an optimized OpenQA Table-Text Retriever (OTTeR) to jointly retrieve tabular and textual evidences. Firstly, we propose to enhance mixed-modality representation learning via two mechanisms: modality-enhanced representation and mixed-modality negative sampling strategy. Secondly, to alleviate data sparsity problem and enhance the general retrieval ability, we conduct retrieval-centric mixed-modality synthetic pre-training. Experimental results demonstrate that OTTeR substantially improves the performance of table-and-text retrieval on the OTT-QA dataset. Comprehensive analyses examine the effectiveness of all the proposed mechanisms. Besides, equipped with OTTeR, our OpenQA system achieves the state-of-the-art result on the downstream QA task, with 10.1\% absolute improvement in terms of the exact match over the previous best system. \footnote{All the code and data are available at \url{https://github.com/Jun-jie-Huang/OTTeR}.}
CONE: An Efficient COarse-to-fiNE Alignment Framework for Long Video Temporal Grounding
Sep 22, 2022

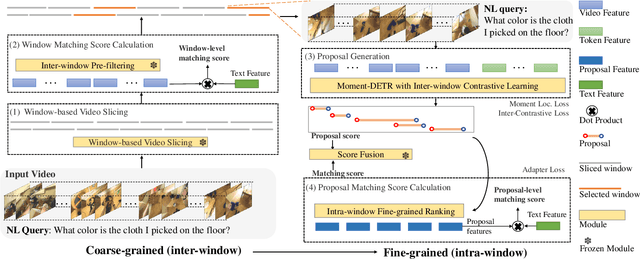
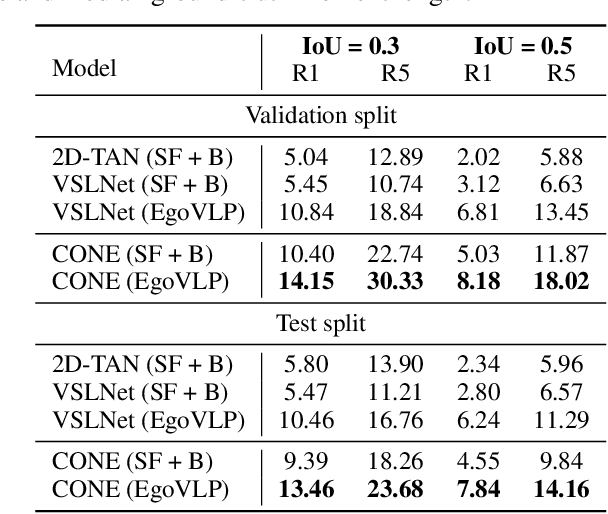
Video temporal grounding (VTG) targets to localize temporal moments in an untrimmed video according to a natural language (NL) description. Since real-world applications provide a never-ending video stream, it raises demands for temporal grounding for long-form videos, which leads to two major challenges: (1) the long video length makes it difficult to process the entire video without decreasing sample rate and leads to high computational burden; (2) the accurate multi-modal alignment is more challenging as the number of moment candidates increases. To address these challenges, we propose CONE, an efficient window-centric COarse-to-fiNE alignment framework, which flexibly handles long-form video inputs with higher inference speed, and enhances the temporal grounding via our novel coarse-to-fine multi-modal alignment framework. Specifically, we dynamically slice the long video into candidate windows via a sliding window approach. Centering at windows, CONE (1) learns the inter-window (coarse-grained) semantic variance through contrastive learning and speeds up inference by pre-filtering the candidate windows relevant to the NL query, and (2) conducts intra-window (fine-grained) candidate moments ranking utilizing the powerful multi-modal alignment ability of a contrastive vision-text pre-trained model. Extensive experiments on two large-scale VTG benchmarks for long videos consistently show a substantial performance gain (from 3.13% to 6.87% on MAD and from 10.46% to 13.46% on Ego4d-NLQ) and CONE achieves the SOTA results on both datasets. Analysis reveals the effectiveness of components and higher efficiency in long video grounding as our system improves the inference speed by 2x on Ego4d-NLQ and 15x on MAD while keeping the SOTA performance of CONE.