 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparating Diagnosis from Control: Auditable Policy Adaptation in Agent-Based Simulations with LLM-Based Diagnostics
Mar 24, 2026Mitigating elderly loneliness requires policy interventions that achieve both adaptability and auditability. Existing methods struggle to reconcile these objectives: traditional agent-based models suffer from static rigidity, while direct large language model (LLM) controllers lack essential traceability. This work proposes a three-layer framework that separates diagnosis from control to achieve both properties simultaneously. LLMs operate strictly as diagnostic instruments that assess population state and generate structured risk evaluations, while deterministic formulas with explicit bounds translate these assessments into traceable parameter updates. This separation ensures that every policy decision can be attributed to inspectable rules while maintaining adaptive response to emergent needs. We validate the framework through systematic ablation across five experimental conditions in elderly care simulation. Results demonstrate that explicit control rules outperform end-to-end black-box LLM approaches by 11.7\% while preserving full auditability, confirming that transparency need not compromise adaptive performance.
Words at Play: Benchmarking Audio Pun Understanding in Large Audio-Language Models
Mar 19, 2026Puns represent a typical linguistic phenomenon that exploits polysemy and phonetic ambiguity to generate humour, posing unique challenges for natural language understanding. Within pun research, audio plays a central role in human communication except text and images, while datasets and systematic resources for spoken puns remain scarce, leaving this crucial modality largely underexplored. In this paper, we present APUN-Bench, the first benchmark dedicated to evaluating large audio language models (LALMs) on audio pun understanding. Our benchmark contains 4,434 audio samples annotated across three stages: pun recognition, pun word location and pun meaning inference. We conduct a deep analysis of APUN-Bench by systematically evaluating 10 state-of-the-art LALMs, uncovering substantial performance gaps in recognizing, localizing, and interpreting audio puns. This analysis reveals key challenges, such as positional biases in audio pun location and error cases in meaning inference, offering actionable insights for advancing humour-aware audio intelligence.
Meta-Inverse Reinforcement Learning for Mean Field Games via Probabilistic Context Variables
Sep 04, 2025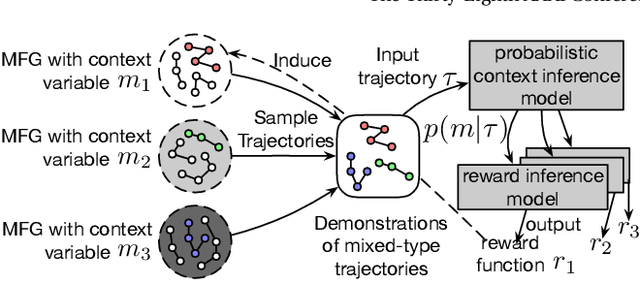
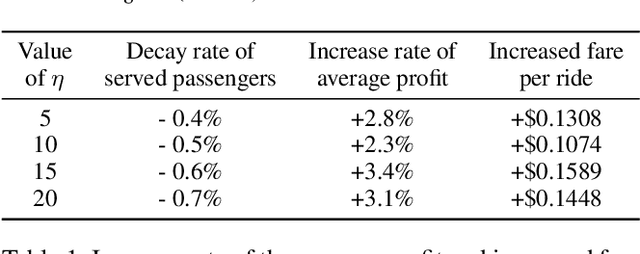
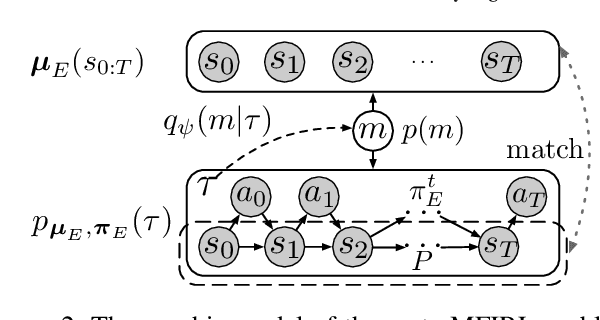
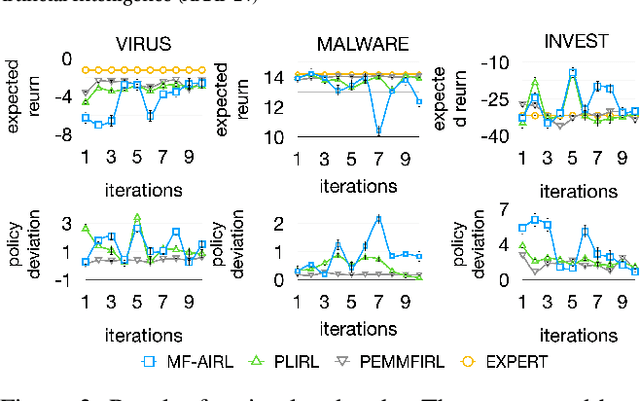
Designing suitable reward functions for numerous interacting intelligent agents is challenging in real-world applications. Inverse reinforcement learning (IRL) in mean field games (MFGs) offers a practical framework to infer reward functions from expert demonstrations. While promising, the assumption of agent homogeneity limits the capability of existing methods to handle demonstrations with heterogeneous and unknown objectives, which are common in practice. To this end, we propose a deep latent variable MFG model and an associated IRL method. Critically, our method can infer rewards from different yet structurally similar tasks without prior knowledge about underlying contexts or modifying the MFG model itself. Our experiments, conducted on simulated scenarios and a real-world spatial taxi-ride pricing problem, demonstrate the superiority of our approach over state-of-the-art IRL methods in MFGs.
Causal Cartographer: From Mapping to Reasoning Over Counterfactual Worlds
May 20, 2025Causal world models are systems that can answer counterfactual questions about an environment of interest, i.e. predict how it would have evolved if an arbitrary subset of events had been realized differently. It requires understanding the underlying causes behind chains of events and conducting causal inference for arbitrary unseen distributions. So far, this task eludes foundation models, notably large language models (LLMs), which do not have demonstrated causal reasoning capabilities beyond the memorization of existing causal relationships. Furthermore, evaluating counterfactuals in real-world applications is challenging since only the factual world is observed, limiting evaluation to synthetic datasets. We address these problems by explicitly extracting and modeling causal relationships and propose the Causal Cartographer framework. First, we introduce a graph retrieval-augmented generation agent tasked to retrieve causal relationships from data. This approach allows us to construct a large network of real-world causal relationships that can serve as a repository of causal knowledge and build real-world counterfactuals. In addition, we create a counterfactual reasoning agent constrained by causal relationships to perform reliable step-by-step causal inference. We show that our approach can extract causal knowledge and improve the robustness of LLMs for causal reasoning tasks while reducing inference costs and spurious correlations.
Robust Domain Generalisation with Causal Invariant Bayesian Neural Networks
Oct 08, 2024



Deep neural networks can obtain impressive performance on various tasks under the assumption that their training domain is identical to their target domain. Performance can drop dramatically when this assumption does not hold. One explanation for this discrepancy is the presence of spurious domain-specific correlations in the training data that the network exploits. Causal mechanisms, in the other hand, can be made invariant under distribution changes as they allow disentangling the factors of distribution underlying the data generation. Yet, learning causal mechanisms to improve out-of-distribution generalisation remains an under-explored area. We propose a Bayesian neural architecture that disentangles the learning of the the data distribution from the inference process mechanisms. We show theoretically and experimentally that our model approximates reasoning under causal interventions. We demonstrate the performance of our method, outperforming point estimate-counterparts, on out-of-distribution image recognition tasks where the data distribution acts as strong adversarial confounders.
Counterfactual Causal Inference in Natural Language with Large Language Models
Oct 08, 2024



Causal structure discovery methods are commonly applied to structured data where the causal variables are known and where statistical testing can be used to assess the causal relationships. By contrast, recovering a causal structure from unstructured natural language data such as news articles contains numerous challenges due to the absence of known variables or counterfactual data to estimate the causal links. Large Language Models (LLMs) have shown promising results in this direction but also exhibit limitations. This work investigates LLM's abilities to build causal graphs from text documents and perform counterfactual causal inference. We propose an end-to-end causal structure discovery and causal inference method from natural language: we first use an LLM to extract the instantiated causal variables from text data and build a causal graph. We merge causal graphs from multiple data sources to represent the most exhaustive set of causes possible. We then conduct counterfactual inference on the estimated graph. The causal graph conditioning allows reduction of LLM biases and better represents the causal estimands. We use our method to show that the limitations of LLMs in counterfactual causal reasoning come from prediction errors and propose directions to mitigate them. We demonstrate the applicability of our method on real-world news articles.
Neural Fourier Modelling: A Highly Compact Approach to Time-Series Analysis
Oct 07, 2024



Neural time-series analysis has traditionally focused on modeling data in the time domain, often with some approaches incorporating equivalent Fourier domain representations as auxiliary spectral features. In this work, we shift the main focus to frequency representations, modeling time-series data fully and directly in the Fourier domain. We introduce Neural Fourier Modelling (NFM), a compact yet powerful solution for time-series analysis. NFM is grounded in two key properties of the Fourier transform (FT): (i) the ability to model finite-length time series as functions in the Fourier domain, treating them as continuous-time elements in function space, and (ii) the capacity for data manipulation (such as resampling and timespan extension) within the Fourier domain. We reinterpret Fourier-domain data manipulation as frequency extrapolation and interpolation, incorporating this as a core learning mechanism in NFM, applicable across various tasks. To support flexible frequency extension with spectral priors and effective modulation of frequency representations, we propose two learning modules: Learnable Frequency Tokens (LFT) and Implicit Neural Fourier Filters (INFF). These modules enable compact and expressive modeling in the Fourier domain. Extensive experiments demonstrate that NFM achieves state-of-the-art performance on a wide range of tasks (forecasting, anomaly detection, and classification), including challenging time-series scenarios with previously unseen sampling rates at test time. Moreover, NFM is highly compact, requiring fewer than 40K parameters in each task, with time-series lengths ranging from 100 to 16K.
Transformers As Approximations of Solomonoff Induction
Aug 22, 2024Solomonoff Induction is an optimal-in-the-limit unbounded algorithm for sequence prediction, representing a Bayesian mixture of every computable probability distribution and performing close to optimally in predicting any computable sequence. Being an optimal form of computational sequence prediction, it seems plausible that it may be used as a model against which other methods of sequence prediction might be compared. We put forth and explore the hypothesis that Transformer models - the basis of Large Language Models - approximate Solomonoff Induction better than any other extant sequence prediction method. We explore evidence for and against this hypothesis, give alternate hypotheses that take this evidence into account, and outline next steps for modelling Transformers and other kinds of AI in this way.
Using Large Language Models for the Interpretation of Building Regulations
Jul 26, 2024



Compliance checking is an essential part of a construction project. The recent rapid uptake of building information models (BIM) in the construction industry has created more opportunities for automated compliance checking (ACC). BIM enables sharing of digital building design data that can be used for compliance checking with legal requirements, which are conventionally conveyed in natural language and not intended for machine processing. Creating a computable representation of legal requirements suitable for ACC is complex, costly, and time-consuming. Large language models (LLMs) such as the generative pre-trained transformers (GPT), GPT-3.5 and GPT-4, powering OpenAI's ChatGPT, can generate logically coherent text and source code responding to user prompts. This capability could be used to automate the conversion of building regulations into a semantic and computable representation. This paper evaluates the performance of LLMs in translating building regulations into LegalRuleML in a few-shot learning setup. By providing GPT-3.5 with only a few example translations, it can learn the basic structure of the format. Using a system prompt, we further specify the LegalRuleML representation and explore the existence of expert domain knowledge in the model. Such domain knowledge might be ingrained in GPT-3.5 through the broad pre-training but needs to be brought forth by careful contextualisation. Finally, we investigate whether strategies such as chain-of-thought reasoning and self-consistency could apply to this use case. As LLMs become more sophisticated, the increased common sense, logical coherence, and means to domain adaptation can significantly support ACC, leading to more efficient and effective checking processes.
Recurrence over Video Frames for the Re-identification of Meerkats
Jun 18, 2024



Deep learning approaches for animal re-identification have had a major impact on conservation, significantly reducing the time required for many downstream tasks, such as well-being monitoring. We propose a method called Recurrence over Video Frames (RoVF), which uses a recurrent head based on the Perceiver architecture to iteratively construct an embedding from a video clip. RoVF is trained using triplet loss based on the co-occurrence of individuals in the video frames, where the individual IDs are unavailable. We tested this method and various models based on the DINOv2 transformer architecture on a dataset of meerkats collected at the Wellington Zoo. Our method achieves a top-1 re-identification accuracy of $49\%$, which is higher than that of the best DINOv2 model ($42\%$). We found that the model can match observations of individuals where humans cannot, and our model (RoVF) performs better than the comparisons with minimal fine-tuning. In future work, we plan to improve these models by using pre-text tasks, apply them to animal behaviour classification, and perform a hyperparameter search to optimise the models further.