 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWords at Play: Benchmarking Audio Pun Understanding in Large Audio-Language Models
Mar 19, 2026Puns represent a typical linguistic phenomenon that exploits polysemy and phonetic ambiguity to generate humour, posing unique challenges for natural language understanding. Within pun research, audio plays a central role in human communication except text and images, while datasets and systematic resources for spoken puns remain scarce, leaving this crucial modality largely underexplored. In this paper, we present APUN-Bench, the first benchmark dedicated to evaluating large audio language models (LALMs) on audio pun understanding. Our benchmark contains 4,434 audio samples annotated across three stages: pun recognition, pun word location and pun meaning inference. We conduct a deep analysis of APUN-Bench by systematically evaluating 10 state-of-the-art LALMs, uncovering substantial performance gaps in recognizing, localizing, and interpreting audio puns. This analysis reveals key challenges, such as positional biases in audio pun location and error cases in meaning inference, offering actionable insights for advancing humour-aware audio intelligence.
Global-Graph Guided and Local-Graph Weighted Contrastive Learning for Unified Clustering on Incomplete and Noise Multi-View Data
Dec 25, 2025Recently, contrastive learning (CL) plays an important role in exploring complementary information for multi-view clustering (MVC) and has attracted increasing attention. Nevertheless, real-world multi-view data suffer from data incompleteness or noise, resulting in rare-paired samples or mis-paired samples which significantly challenges the effectiveness of CL-based MVC. That is, rare-paired issue prevents MVC from extracting sufficient multi-view complementary information, and mis-paired issue causes contrastive learning to optimize the model in the wrong direction. To address these issues, we propose a unified CL-based MVC framework for enhancing clustering effectiveness on incomplete and noise multi-view data. First, to overcome the rare-paired issue, we design a global-graph guided contrastive learning, where all view samples construct a global-view affinity graph to form new sample pairs for fully exploring complementary information. Second, to mitigate the mis-paired issue, we propose a local-graph weighted contrastive learning, which leverages local neighbors to generate pair-wise weights to adaptively strength or weaken the pair-wise contrastive learning. Our method is imputation-free and can be integrated into a unified global-local graph-guided contrastive learning framework. Extensive experiments on both incomplete and noise settings of multi-view data demonstrate that our method achieves superior performance compared with state-of-the-art approaches.
Contrastive Learning with Logic-driven Data Augmentation for Logical Reasoning over Text
May 21, 2023Pre-trained large language model (LLM) is under exploration to perform NLP tasks that may require logical reasoning. Logic-driven data augmentation for representation learning has been shown to improve the performance of tasks requiring logical reasoning, but most of these data rely on designed templates and therefore lack generalization. In this regard, we propose an AMR-based logical equivalence-driven data augmentation method (AMR-LE) for generating logically equivalent data. Specifically, we first parse a text into the form of an AMR graph, next apply four logical equivalence laws (contraposition, double negation, commutative and implication laws) on the AMR graph to construct a logically equivalent/inequivalent AMR graph, and then convert it into a logically equivalent/inequivalent sentence. To help the model to better learn these logical equivalence laws, we propose a logical equivalence-driven contrastive learning training paradigm, which aims to distinguish the difference between logical equivalence and inequivalence. Our AMR-LE (Ensemble) achieves #2 on the ReClor leaderboard https://eval.ai/web/challenges/challenge-page/503/leaderboard/1347 . Our model shows better performance on seven downstream tasks, including ReClor, LogiQA, MNLI, MRPC, RTE, QNLI, and QQP. The source code and dataset are public at https://github.com/Strong-AI-Lab/Logical-Equivalence-driven-AMR-Data-Augmentation-for-Representation-Learning .
Prompt-based Conservation Learning for Multi-hop Question Answering
Sep 14, 2022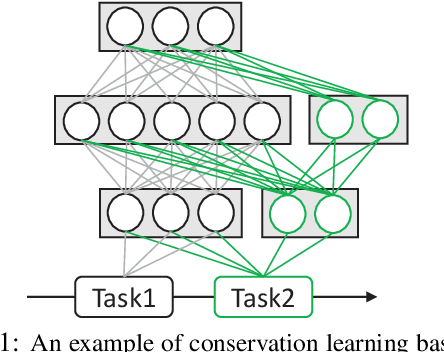
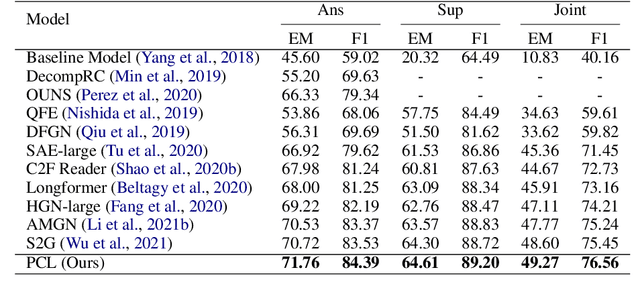
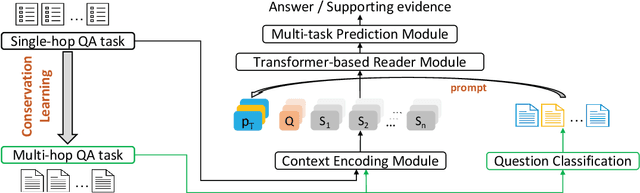
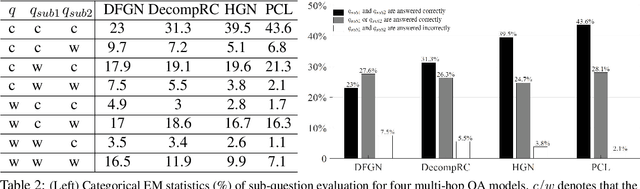
Multi-hop question answering (QA) requires reasoning over multiple documents to answer a complex question and provide interpretable supporting evidence. However, providing supporting evidence is not enough to demonstrate that a model has performed the desired reasoning to reach the correct answer. Most existing multi-hop QA methods fail to answer a large fraction of sub-questions, even if their parent questions are answered correctly. In this paper, we propose the Prompt-based Conservation Learning (PCL) framework for multi-hop QA, which acquires new knowledge from multi-hop QA tasks while conserving old knowledge learned on single-hop QA tasks, mitigating forgetting. Specifically, we first train a model on existing single-hop QA tasks, and then freeze this model and expand it by allocating additional sub-networks for the multi-hop QA task. Moreover, to condition pre-trained language models to stimulate the kind of reasoning required for specific multi-hop questions, we learn soft prompts for the novel sub-networks to perform type-specific reasoning. Experimental results on the HotpotQA benchmark show that PCL is competitive for multi-hop QA and retains good performance on the corresponding single-hop sub-questions, demonstrating the efficacy of PCL in mitigating knowledge loss by forgetting.
Interpretable AMR-Based Question Decomposition for Multi-hop Question Answering
Jun 16, 2022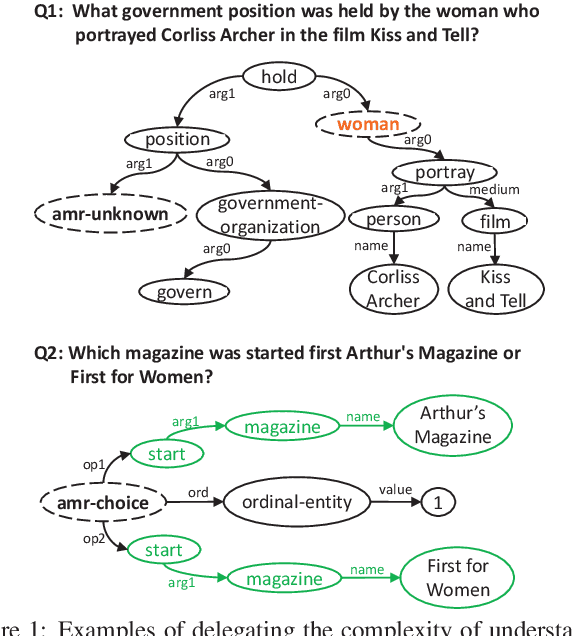
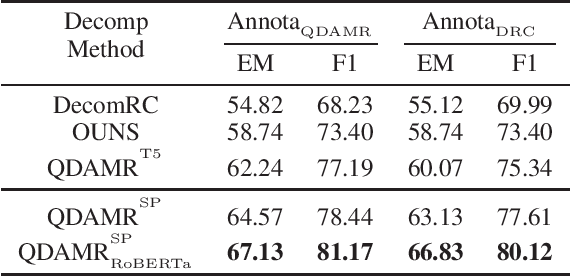
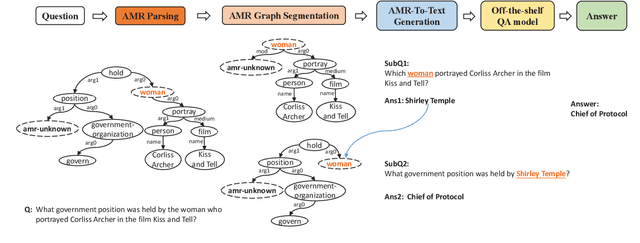
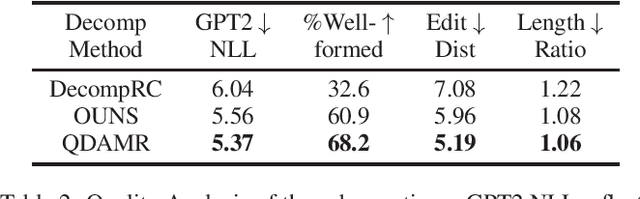
Effective multi-hop question answering (QA) requires reasoning over multiple scattered paragraphs and providing explanations for answers. Most existing approaches cannot provide an interpretable reasoning process to illustrate how these models arrive at an answer. In this paper, we propose a Question Decomposition method based on Abstract Meaning Representation (QDAMR) for multi-hop QA, which achieves interpretable reasoning by decomposing a multi-hop question into simpler sub-questions and answering them in order. Since annotating the decomposition is expensive, we first delegate the complexity of understanding the multi-hop question to an AMR parser. We then achieve the decomposition of a multi-hop question via segmentation of the corresponding AMR graph based on the required reasoning type. Finally, we generate sub-questions using an AMR-to-Text generation model and answer them with an off-the-shelf QA model. Experimental results on HotpotQA demonstrate that our approach is competitive for interpretable reasoning and that the sub-questions generated by QDAMR are well-formed, outperforming existing question-decomposition-based multi-hop QA approaches.