 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Stability Certificates from Data
Sep 14, 2020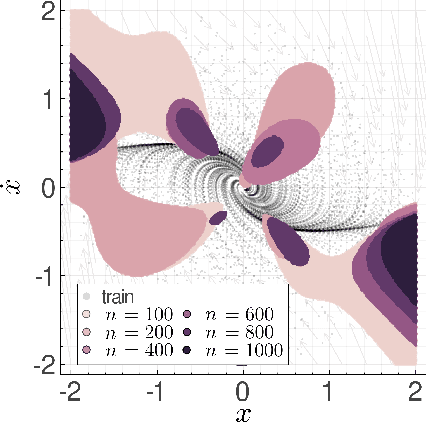
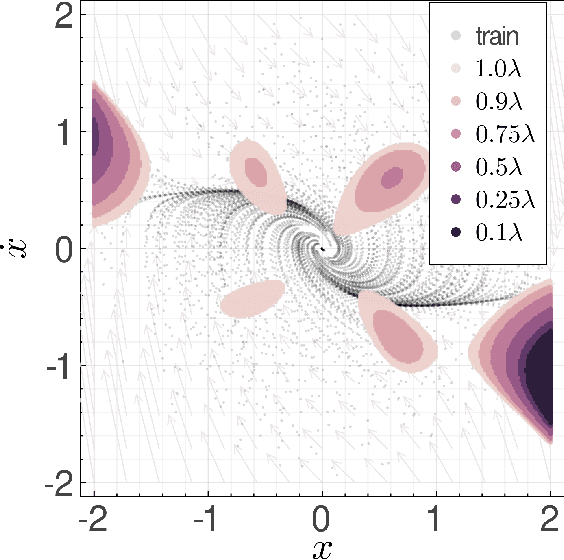
Many existing tools in nonlinear control theory for establishing stability or safety of a dynamical system can be distilled to the construction of a certificate function that guarantees a desired property. However, algorithms for synthesizing certificate functions typically require a closed-form analytical expression of the underlying dynamics, which rules out their use on many modern robotic platforms. To circumvent this issue, we develop algorithms for learning certificate functions only from trajectory data. We establish bounds on the generalization error - the probability that a certificate will not certify a new, unseen trajectory - when learning from trajectories, and we convert such generalization error bounds into global stability guarantees. We demonstrate empirically that certificates for complex dynamics can be efficiently learned, and that the learned certificates can be used for downstream tasks such as adaptive control.
An Ode to an ODE
Jun 23, 2020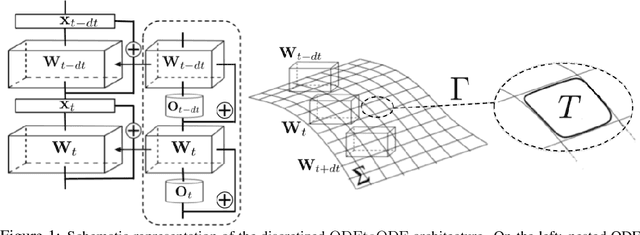
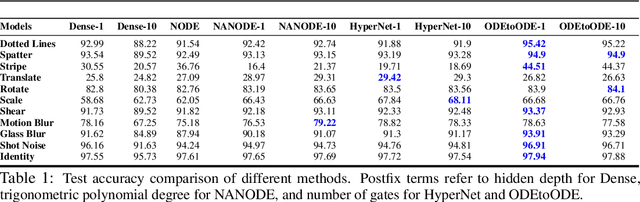
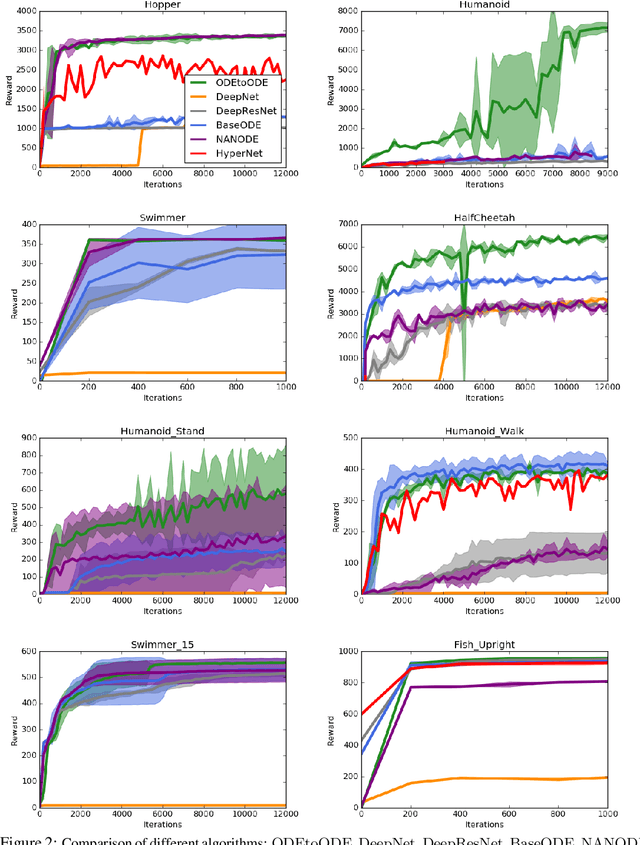
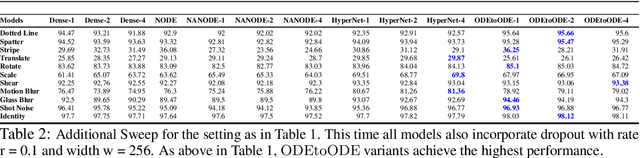
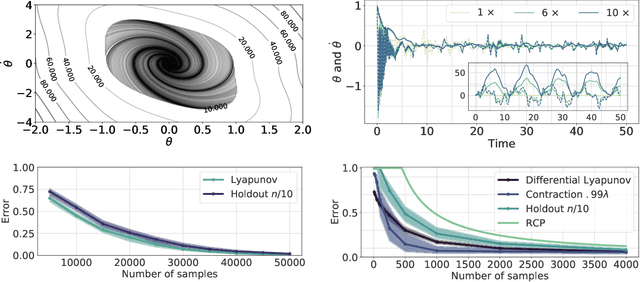
We present a new paradigm for Neural ODE algorithms, called ODEtoODE, where time-dependent parameters of the main flow evolve according to a matrix flow on the orthogonal group O(d). This nested system of two flows, where the parameter-flow is constrained to lie on the compact manifold, provides stability and effectiveness of training and provably solves the gradient vanishing-explosion problem which is intrinsically related to training deep neural network architectures such as Neural ODEs. Consequently, it leads to better downstream models, as we show on the example of training reinforcement learning policies with evolution strategies, and in the supervised learning setting, by comparing with previous SOTA baselines. We provide strong convergence results for our proposed mechanism that are independent of the depth of the network, supporting our empirical studies. Our results show an intriguing connection between the theory of deep neural networks and the field of matrix flows on compact manifolds.
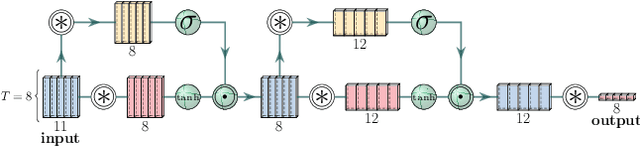
Time Dependence in Non-Autonomous Neural ODEs
May 06, 2020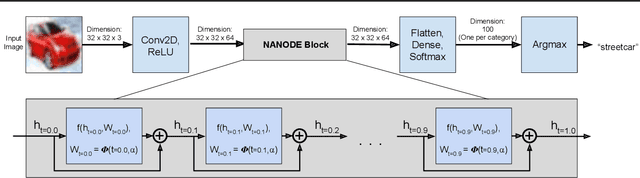
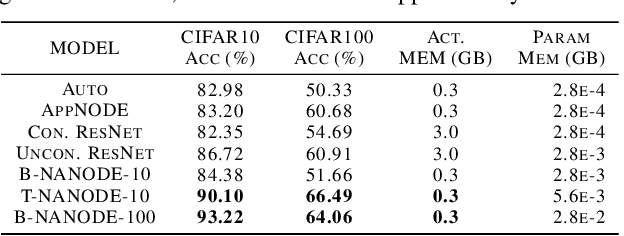
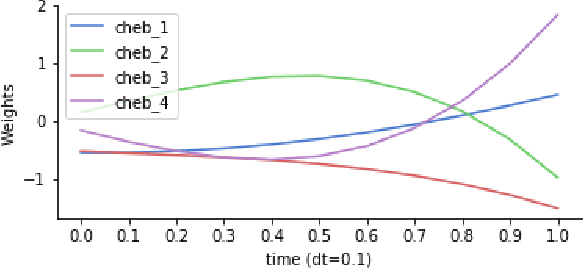
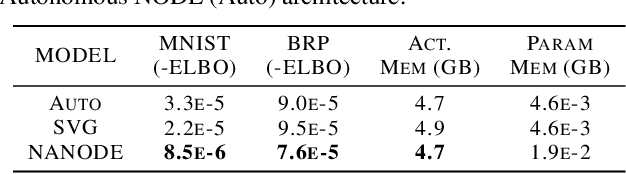
Neural Ordinary Differential Equations (ODEs) are elegant reinterpretations of deep networks where continuous time can replace the discrete notion of depth, ODE solvers perform forward propagation, and the adjoint method enables efficient, constant memory backpropagation. Neural ODEs are universal approximators only when they are non-autonomous, that is, the dynamics depends explicitly on time. We propose a novel family of Neural ODEs with time-varying weights, where time-dependence is non-parametric, and the smoothness of weight trajectories can be explicitly controlled to allow a tradeoff between expressiveness and efficiency. Using this enhanced expressiveness, we outperform previous Neural ODE variants in both speed and representational capacity, ultimately outperforming standard ResNet and CNN models on select image classification and video prediction tasks.
Robotic Table Tennis with Model-Free Reinforcement Learning
Mar 31, 2020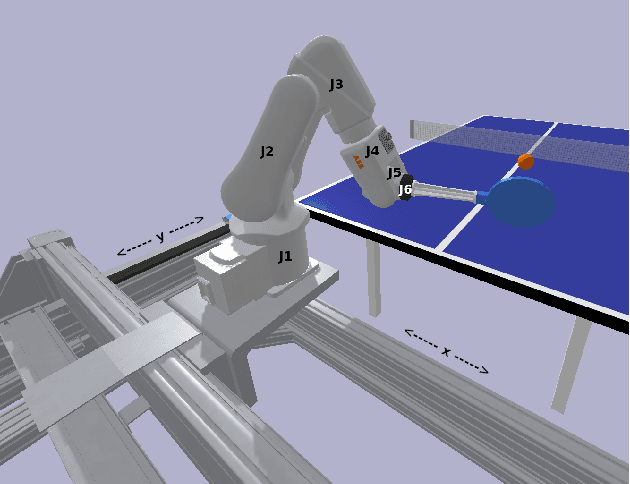
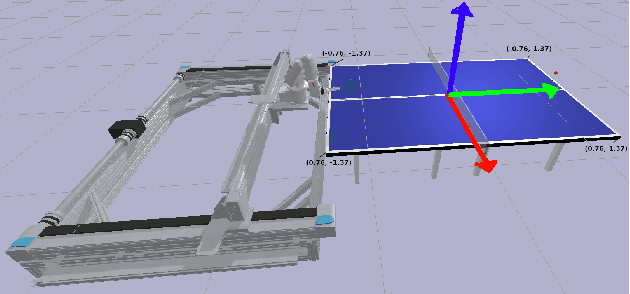

We propose a model-free algorithm for learning efficient policies capable of returning table tennis balls by controlling robot joints at a rate of 100Hz. We demonstrate that evolutionary search (ES) methods acting on CNN-based policy architectures for non-visual inputs and convolving across time learn compact controllers leading to smooth motions. Furthermore, we show that with appropriately tuned curriculum learning on the task and rewards, policies are capable of developing multi-modal styles, specifically forehand and backhand stroke, whilst achieving 80\% return rate on a wide range of ball throws. We observe that multi-modality does not require any architectural priors, such as multi-head architectures or hierarchical policies.
Stochastic Flows and Geometric Optimization on the Orthogonal Group
Mar 30, 2020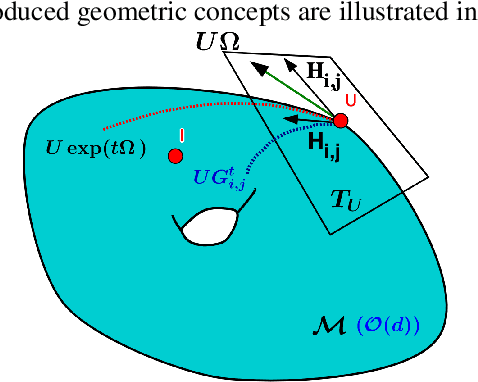
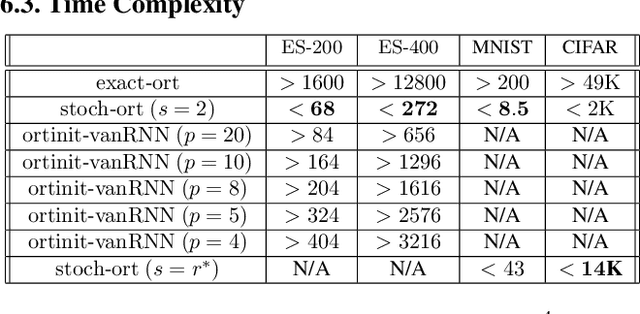


We present a new class of stochastic, geometrically-driven optimization algorithms on the orthogonal group $O(d)$ and naturally reductive homogeneous manifolds obtained from the action of the rotation group $SO(d)$. We theoretically and experimentally demonstrate that our methods can be applied in various fields of machine learning including deep, convolutional and recurrent neural networks, reinforcement learning, normalizing flows and metric learning. We show an intriguing connection between efficient stochastic optimization on the orthogonal group and graph theory (e.g. matching problem, partition functions over graphs, graph-coloring). We leverage the theory of Lie groups and provide theoretical results for the designed class of algorithms. We demonstrate broad applicability of our methods by showing strong performance on the seemingly unrelated tasks of learning world models to obtain stable policies for the most difficult $\mathrm{Humanoid}$ agent from $\mathrm{OpenAI}$ $\mathrm{Gym}$ and improving convolutional neural networks.
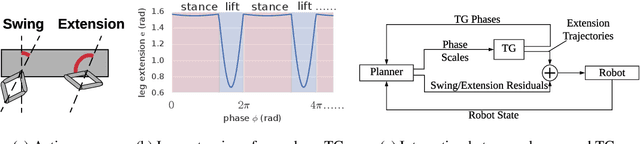
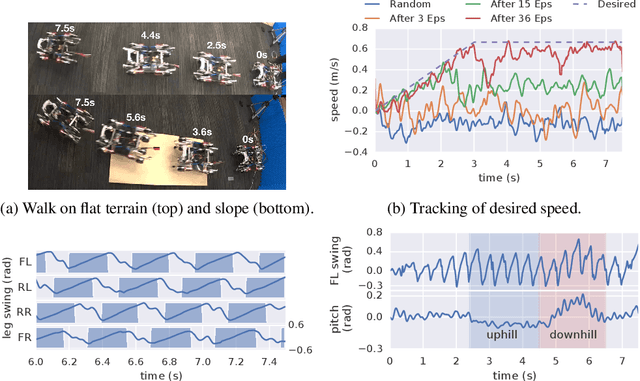
Policies Modulating Trajectory Generators
Oct 07, 2019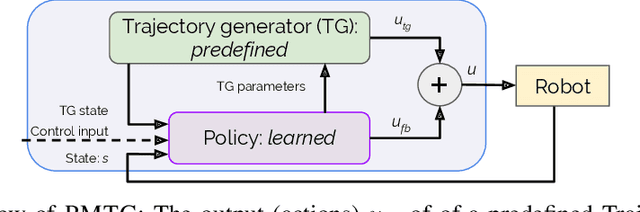
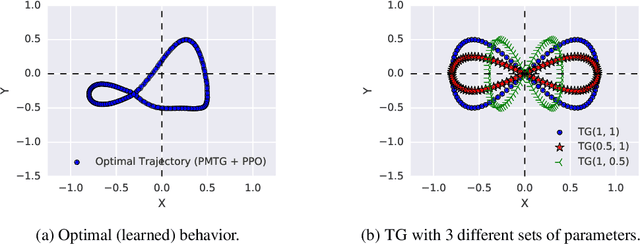
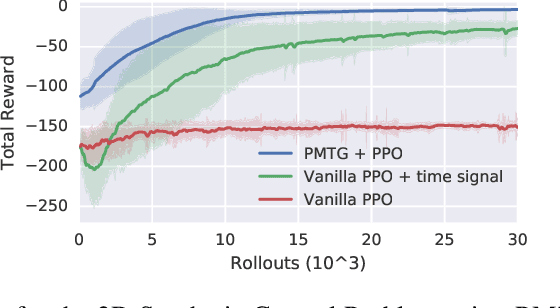
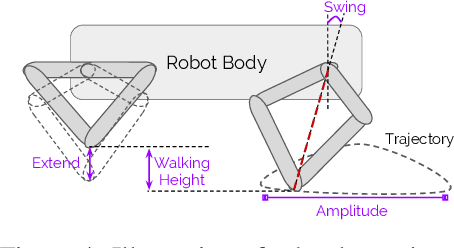
We propose an architecture for learning complex controllable behaviors by having simple Policies Modulate Trajectory Generators (PMTG), a powerful combination that can provide both memory and prior knowledge to the controller. The result is a flexible architecture that is applicable to a class of problems with periodic motion for which one has an insight into the class of trajectories that might lead to a desired behavior. We illustrate the basics of our architecture using a synthetic control problem, then go on to learn speed-controlled locomotion for a quadrupedal robot by using Deep Reinforcement Learning and Evolutionary Strategies. We demonstrate that a simple linear policy, when paired with a parametric Trajectory Generator for quadrupedal gaits, can induce walking behaviors with controllable speed from 4-dimensional IMU observations alone, and can be learned in under 1000 rollouts. We also transfer these policies to a real robot and show locomotion with controllable forward velocity.
Learning Stabilizable Nonlinear Dynamics with Contraction-Based Regularization
Jul 29, 2019
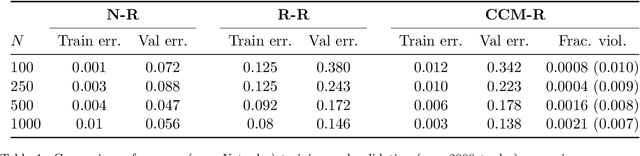
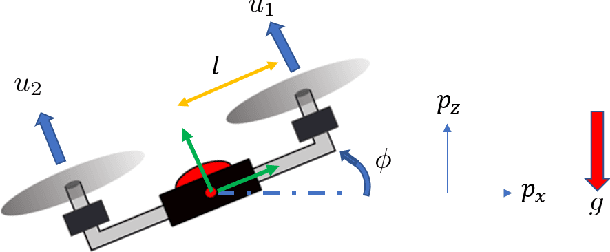

We propose a novel framework for learning stabilizable nonlinear dynamical systems for continuous control tasks in robotics. The key contribution is a control-theoretic regularizer for dynamics fitting rooted in the notion of stabilizability, a constraint which guarantees the existence of robust tracking controllers for arbitrary open-loop trajectories generated with the learned system. Leveraging tools from contraction theory and statistical learning in Reproducing Kernel Hilbert Spaces, we formulate stabilizable dynamics learning as a functional optimization with convex objective and bi-convex functional constraints. Under a mild structural assumption and relaxation of the functional constraints to sampling-based constraints, we derive the optimal solution with a modified Representer theorem. Finally, we utilize random matrix feature approximations to reduce the dimensionality of the search parameters and formulate an iterative convex optimization algorithm that jointly fits the dynamics functions and searches for a certificate of stabilizability. We validate the proposed algorithm in simulation for a planar quadrotor, and on a quadrotor hardware testbed emulating planar dynamics. We verify, both in simulation and on hardware, significantly improved trajectory generation and tracking performance with the control-theoretic regularized model over models learned using traditional regression techniques, especially when learning from small supervised datasets. The results support the conjecture that the use of stabilizability constraints as a form of regularization can help prune the hypothesis space in a manner that is tailored to the downstream task of trajectory generation and feedback control, resulting in models that are not only dramatically better conditioned, but also data efficient.
Data Efficient Reinforcement Learning for Legged Robots
Jul 08, 2019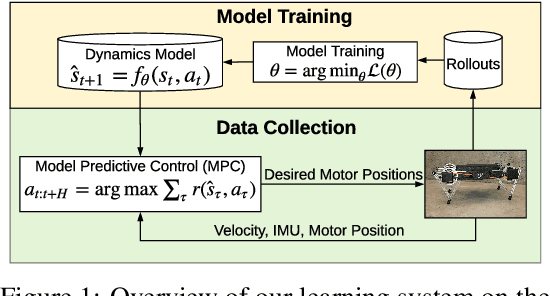
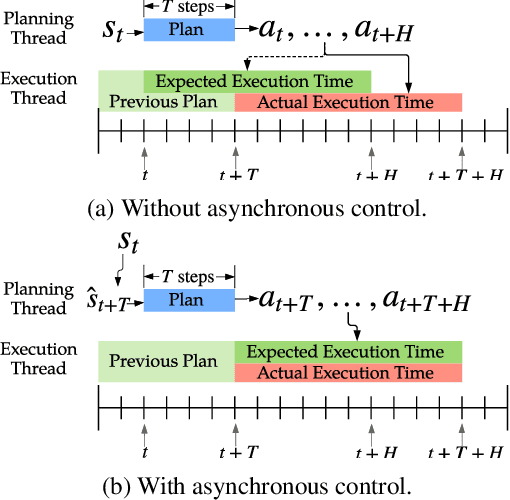
We present a model-based framework for robot locomotion that achieves walking based on only 4.5 minutes (45,000 control steps) of data collected on a quadruped robot. To accurately model the robot's dynamics over a long horizon, we introduce a loss function that tracks the model's prediction over multiple timesteps. We adapt model predictive control to account for planning latency, which allows the learned model to be used for real time control. Additionally, to ensure safe exploration during model learning, we embed prior knowledge of leg trajectories into the action space. The resulting system achieves fast and robust locomotion. Unlike model-free methods, which optimize for a particular task, our planner can use the same learned dynamics for various tasks, simply by changing the reward function. To the best of our knowledge, our approach is more than an order of magnitude more sample efficient than current model-free methods.
Teleoperator Imitation with Continuous-time Safety
May 23, 2019

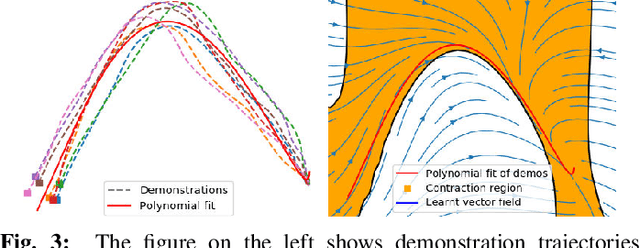
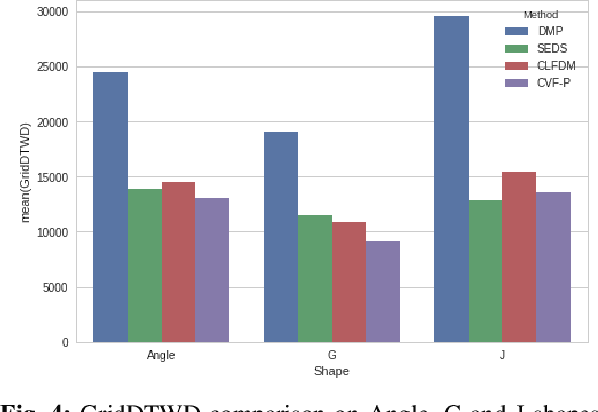
Learning to effectively imitate human teleoperators, with generalization to unseen and dynamic environments, is a promising path to greater autonomy enabling robots to steadily acquire complex skills from supervision. We propose a new motion learning technique rooted in contraction theory and sum-of-squares programming for estimating a control law in the form of a polynomial vector field from a given set of demonstrations. Notably, this vector field is provably optimal for the problem of minimizing imitation loss while providing continuous-time guarantees on the induced imitation behavior. Our method generalizes to new initial and goal poses of the robot and can adapt in real-time to dynamic obstacles during execution, with convergence to teleoperator behavior within a well-defined safety tube. We present an application of our framework for pick-and-place tasks in the presence of moving obstacles on a 7-DOF KUKA IIWA arm. The method compares favorably to other learning-from-demonstration approaches on benchmark handwriting imitation tasks.
When random search is not enough: Sample-Efficient and Noise-Robust Blackbox Optimization of RL Policies
Mar 07, 2019
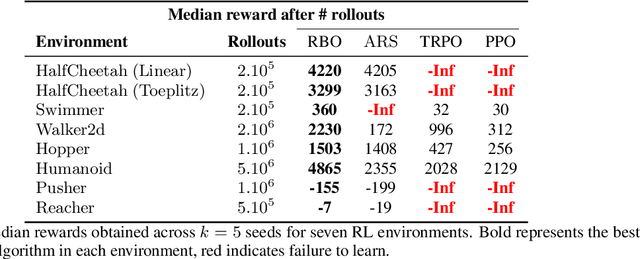
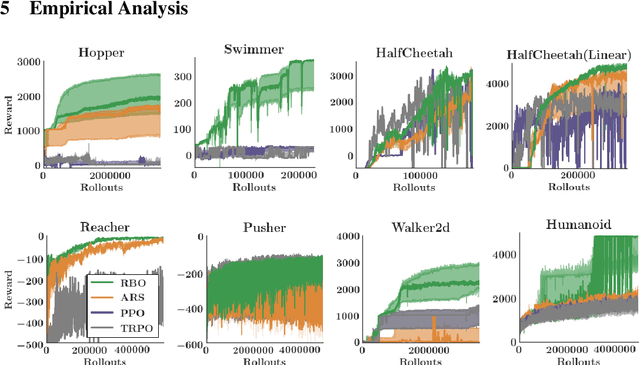

Interest in derivative-free optimization (DFO) and "evolutionary strategies" (ES) has recently surged in the Reinforcement Learning (RL) community, with growing evidence that they match state of the art methods for policy optimization tasks. However, blackbox DFO methods suffer from high sampling complexity since they require a substantial number of policy rollouts for reliable updates. They can also be very sensitive to noise in the rewards, actuators or the dynamics of the environment. In this paper we propose to replace the standard ES derivative-free paradigm for RL based on simple reward-weighted averaged random perturbations for policy updates, that has recently become a subject of voluminous research, by an algorithm where gradients of blackbox RL functions are estimated via regularized regression methods. In particular, we propose to use L1/L2 regularized regression-based gradient estimation to exploit sparsity and smoothness, as well as LP decoding techniques for handling adversarial stochastic and deterministic noise. Our methods can be naturally aligned with sliding trust region techniques for efficient samples reuse to further reduce sampling complexity. This is not the case for standard ES methods requiring independent sampling in each epoch. We show that our algorithms can be applied in locomotion tasks, where training is conducted in the presence of substantial noise, e.g. for learning in sim transferable stable walking behaviors for quadruped robots or training quadrupeds how to follow a path. We further demonstrate our methods on several $\mathrm{OpenAI}$ $\mathrm{Gym}$ $\mathrm{Mujoco}$ RL tasks. We manage to train effective policies even if up to $25\%$ of all measurements are arbitrarily corrupted, where standard ES methods produce sub-optimal policies or do not manage to learn at all. Our empirical results are backed by theoretical guarantees.