 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRiemannian Optimization in Modular Systems
Mar 04, 2026Understanding how systems built out of modular components can be jointly optimized is an important problem in biology, engineering, and machine learning. The backpropagation algorithm is one such solution and has been instrumental in the success of neural networks. Despite its empirical success, a strong theoretical understanding of it is lacking. Here, we combine tools from Riemannian geometry, optimal control theory, and theoretical physics to advance this understanding. We make three key contributions: First, we revisit the derivation of backpropagation as a constrained optimization problem and combine it with the insight that Riemannian gradient descent trajectories can be understood as the minimum of an action. Second, we introduce a recursively defined layerwise Riemannian metric that exploits the modular structure of neural networks and can be efficiently computed using the Woodbury matrix identity, avoiding the $O(n^3)$ cost of full metric inversion. Third, we develop a framework of composable ``Riemannian modules'' whose convergence properties can be quantified using nonlinear contraction theory, providing algorithmic stability guarantees of order $O(κ^2 L/(ξμ\sqrt{n}))$ where $κ$ and $L$ are Lipschitz constants, $μ$ is the mass matrix scale, and $ξ$ bounds the condition number. Our layerwise metric approach provides a practical alternative to natural gradient descent. While we focus here on studying neural networks, our approach more generally applies to the study of systems made of modules that are optimized over time, as it occurs in biology during both evolution and development.
Unlocked Backpropagation using Wave Scattering
Feb 11, 2026Both the backpropagation algorithm in machine learning and the maximum principle in optimal control theory are posed as a two-point boundary problem, resulting in a "forward-backward" lock. We derive a reformulation of the maximum principle in optimal control theory as a hyperbolic initial value problem by introducing an additional "optimization time" dimension. We introduce counter-propagating wave variables with finite propagation speed and recast the optimization problem in terms of scattering relationships between them. This relaxation of the original problem can be interpreted as a physical system that equilibrates and changes its physical properties in order to minimize reflections. We discretize this continuum theory to derive a family of fully unlocked algorithms suitable for training neural networks. Different parameter dynamics, including gradient descent, can be derived by demanding dissipation and minimization of reflections at parameter ports. These results also imply that any physical substrate that supports the scattering and dissipation of waves can be interpreted as solving an optimization problem.
NRGPT: An Energy-based Alternative for GPT
Dec 18, 2025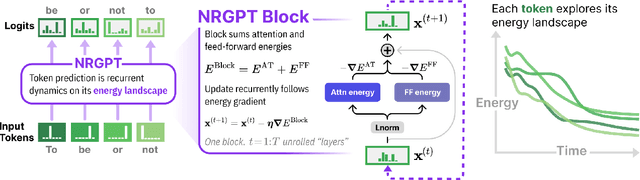
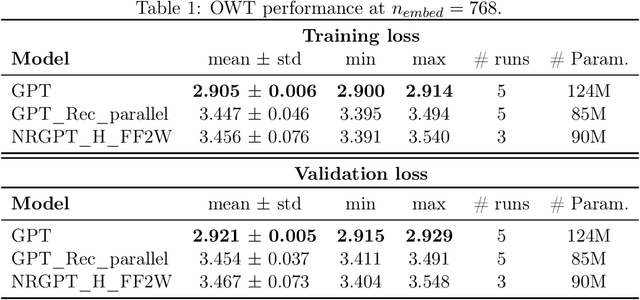
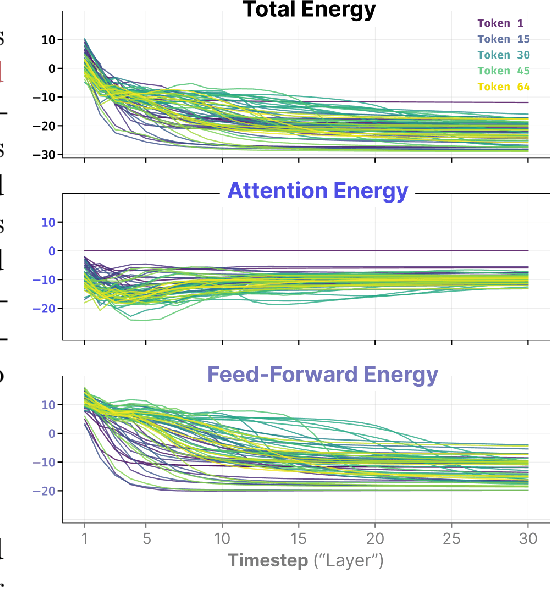

Generative Pre-trained Transformer (GPT) architectures are the most popular design for language modeling. Energy-based modeling is a different paradigm that views inference as a dynamical process operating on an energy landscape. We propose a minimal modification of the GPT setting to unify it with the EBM framework. The inference step of our model, which we call eNeRgy-GPT (NRGPT), is conceptualized as an exploration of the tokens on the energy landscape. We prove, and verify empirically, that under certain circumstances this exploration becomes gradient descent, although they don't necessarily lead to the best performing models. We demonstrate that our model performs well for simple language (Shakespeare dataset), algebraic ListOPS tasks, and richer settings such as OpenWebText language modeling. We also observe that our models may be more resistant to overfitting, doing so only during very long training.
Contraction and entropy production in continuous-time Sinkhorn dynamics
Oct 14, 2025Recently, the vanishing-step-size limit of the Sinkhorn algorithm at finite regularization parameter $\varepsilon$ was shown to be a mirror descent in the space of probability measures. We give $L^2$ contraction criteria in two time-dependent metrics induced by the mirror Hessian, which reduce to the coercivity of certain conditional expectation operators. We then give an exact identity for the entropy production rate of the Sinkhorn flow, which was previously known only to be nonpositive. Examining this rate shows that the standard semigroup analysis of diffusion processes extends systematically to the Sinkhorn flow. We show that the flow induces a reversible Markov dynamics on the target marginal as an Onsager gradient flow. We define the Dirichlet form associated to its (nonlocal) infinitesimal generator, prove a Poincar\'e inequality for it, and show that the spectral gap is strictly positive along the Sinkhorn flow whenever $\varepsilon > 0$. Lastly, we show that the entropy decay is exponential if and only if a logarithmic Sobolev inequality (LSI) holds. We give for illustration two immediate practical use-cases for the Sinkhorn LSI: as a design principle for the latent space in which generative models are trained, and as a stopping heuristic for discrete-time algorithms.
Combining Movement Primitives with Contraction Theory
Jan 15, 2025This paper presents a modular framework for motion planning using movement primitives. Central to the approach is Contraction Theory, a modular stability tool for nonlinear dynamical systems. The approach extends prior methods by achieving parallel and sequential combinations of both discrete and rhythmic movements, while enabling independent modulation of each movement. This modular framework enables a divide-and-conquer strategy to simplify the programming of complex robot motion planning. Simulation examples illustrate the flexibility and versatility of the framework, highlighting its potential to address diverse challenges in robot motion planning.
Quaternion Sliding Variables in Manipulator Control
Dec 25, 2024We present two quaternion-based sliding variables for controlling the orientation of a manipulator's end-effector. Both sliding variables are free of singularities and represent global exponentially convergent error dynamics that do not exhibit unwinding when used in feedback. The choice of sliding variable is dictated by whether the end-effector's angular velocity vector is expressed in a local or global frame, and is a matter of convenience. Using quaternions allows the end-effector to move in its full operational envelope, which is not possible with other representations, e.g., Euler angles, that introduce representation-specific singularities. Further, the presented stability results are global rather than almost global, where the latter is often the best one can achieve when using rotation matrices to represent orientation.
URDF+: An Enhanced URDF for Robots with Kinematic Loops
Nov 29, 2024



Designs incorporating kinematic loops are becoming increasingly prevalent in the robotics community. Despite the existence of dynamics algorithms to deal with the effects of such loops, many modern simulators rely on dynamics libraries that require robots to be represented as kinematic trees. This requirement is reflected in the de facto standard format for describing robots, the Universal Robot Description Format (URDF), which does not support kinematic loops resulting in closed chains. This paper introduces an enhanced URDF, termed URDF+, which addresses this key shortcoming of URDF while retaining the intuitive design philosophy and low barrier to entry that the robotics community values. The URDF+ keeps the elements used by URDF to describe open chains and incorporates new elements to encode loop joints. We also offer an accompanying parser that processes the system models coming from URDF+ so that they can be used with recursive rigid-body dynamics algorithms for closed-chain systems that group bodies into local, decoupled loops. This parsing process is fully automated, ensuring optimal grouping of constrained bodies without requiring manual specification from the user. We aim to advance the robotics community towards this elegant solution by developing efficient and easy-to-use software tools.
Passive Obstacle Aware Control to Follow Desired Velocities
May 09, 2024



Evaluating and updating the obstacle avoidance velocity for an autonomous robot in real-time ensures robustness against noise and disturbances. A passive damping controller can obtain the desired motion with a torque-controlled robot, which remains compliant and ensures a safe response to external perturbations. Here, we propose a novel approach for designing the passive control policy. Our algorithm complies with obstacle-free zones while transitioning to increased damping near obstacles to ensure collision avoidance. This approach ensures stability across diverse scenarios, effectively mitigating disturbances. Validation on a 7DoF robot arm demonstrates superior collision rejection capabilities compared to the baseline, underlining its practicality for real-world applications. Our obstacle-aware damping controller represents a substantial advancement in secure robot control within complex and uncertain environments.
Dynamic Adaptation Gains for Nonlinear Systems with Unmatched Uncertainties
Nov 09, 2023We present a new direct adaptive control approach for nonlinear systems with unmatched and matched uncertainties. The method relies on adjusting the adaptation gains of individual unmatched parameters whose adaptation transients would otherwise destabilize the closed-loop system. The approach also guarantees the restoration of the adaptation gains to their nominal values and can readily incorporate direct adaptation laws for matched uncertainties. The proposed framework is general as it only requires stabilizability for all possible models.
Stable Modular Control via Contraction Theory for Reinforcement Learning
Nov 07, 2023



We propose a novel way to integrate control techniques with reinforcement learning (RL) for stability, robustness, and generalization: leveraging contraction theory to realize modularity in neural control, which ensures that combining stable subsystems can automatically preserve the stability. We realize such modularity via signal composition and dynamic decomposition. Signal composition creates the latent space, within which RL applies to maximizing rewards. Dynamic decomposition is realized by coordinate transformation that creates an auxiliary space, within which the latent signals are coupled in the way that their combination can preserve stability provided each signal, that is, each subsystem, has stable self-feedbacks. Leveraging modularity, the nonlinear stability problem is deconstructed into algebraically solvable ones, the stability of the subsystems in the auxiliary space, yielding linear constraints on the input gradients of control networks that can be as simple as switching the signs of network weights. This minimally invasive method for stability allows arguably easy integration into the modular neural architectures in machine learning, like hierarchical RL, and improves their performance. We demonstrate in simulation the necessity and the effectiveness of our method: the necessity for robustness and generalization, and the effectiveness in improving hierarchical RL for manipulation learning.