 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Shot Implicit Morphable Faces with Consistent Texture Parameterization
May 04, 2023There is a growing demand for the accessible creation of high-quality 3D avatars that are animatable and customizable. Although 3D morphable models provide intuitive control for editing and animation, and robustness for single-view face reconstruction, they cannot easily capture geometric and appearance details. Methods based on neural implicit representations, such as signed distance functions (SDF) or neural radiance fields, approach photo-realism, but are difficult to animate and do not generalize well to unseen data. To tackle this problem, we propose a novel method for constructing implicit 3D morphable face models that are both generalizable and intuitive for editing. Trained from a collection of high-quality 3D scans, our face model is parameterized by geometry, expression, and texture latent codes with a learned SDF and explicit UV texture parameterization. Once trained, we can reconstruct an avatar from a single in-the-wild image by leveraging the learned prior to project the image into the latent space of our model. Our implicit morphable face models can be used to render an avatar from novel views, animate facial expressions by modifying expression codes, and edit textures by directly painting on the learned UV-texture maps. We demonstrate quantitatively and qualitatively that our method improves upon photo-realism, geometry, and expression accuracy compared to state-of-the-art methods.
PhysDiff: Physics-Guided Human Motion Diffusion Model
Dec 09, 2022Denoising diffusion models hold great promise for generating diverse and realistic human motions. However, existing motion diffusion models largely disregard the laws of physics in the diffusion process and often generate physically-implausible motions with pronounced artifacts such as floating, foot sliding, and ground penetration. This seriously impacts the quality of generated motions and limits their real-world application. To address this issue, we present a novel physics-guided motion diffusion model (PhysDiff), which incorporates physical constraints into the diffusion process. Specifically, we propose a physics-based motion projection module that uses motion imitation in a physics simulator to project the denoised motion of a diffusion step to a physically-plausible motion. The projected motion is further used in the next diffusion step to guide the denoising diffusion process. Intuitively, the use of physics in our model iteratively pulls the motion toward a physically-plausible space. Experiments on large-scale human motion datasets show that our approach achieves state-of-the-art motion quality and improves physical plausibility drastically (>78% for all datasets).
RANA: Relightable Articulated Neural Avatars
Dec 06, 2022



We propose RANA, a relightable and articulated neural avatar for the photorealistic synthesis of humans under arbitrary viewpoints, body poses, and lighting. We only require a short video clip of the person to create the avatar and assume no knowledge about the lighting environment. We present a novel framework to model humans while disentangling their geometry, texture, and also lighting environment from monocular RGB videos. To simplify this otherwise ill-posed task we first estimate the coarse geometry and texture of the person via SMPL+D model fitting and then learn an articulated neural representation for photorealistic image generation. RANA first generates the normal and albedo maps of the person in any given target body pose and then uses spherical harmonics lighting to generate the shaded image in the target lighting environment. We also propose to pretrain RANA using synthetic images and demonstrate that it leads to better disentanglement between geometry and texture while also improving robustness to novel body poses. Finally, we also present a new photorealistic synthetic dataset, Relighting Humans, to quantitatively evaluate the performance of the proposed approach.
DRaCoN -- Differentiable Rasterization Conditioned Neural Radiance Fields for Articulated Avatars
Mar 29, 2022
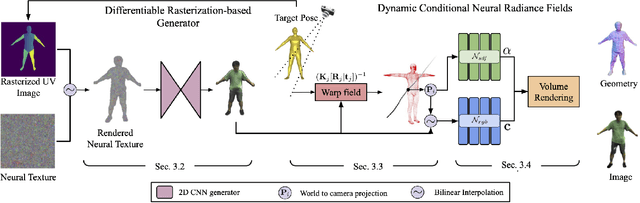
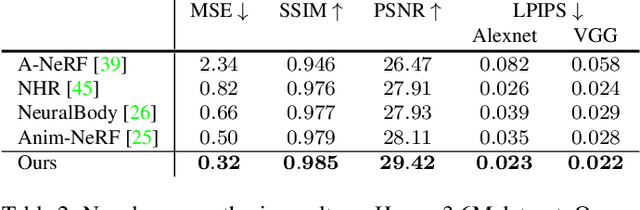
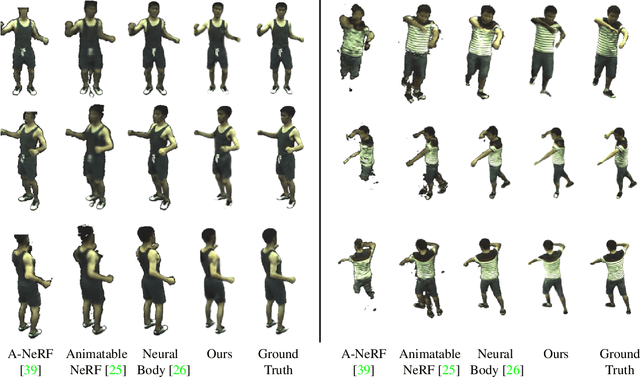
Acquisition and creation of digital human avatars is an important problem with applications to virtual telepresence, gaming, and human modeling. Most contemporary approaches for avatar generation can be viewed either as 3D-based methods, which use multi-view data to learn a 3D representation with appearance (such as a mesh, implicit surface, or volume), or 2D-based methods which learn photo-realistic renderings of avatars but lack accurate 3D representations. In this work, we present, DRaCoN, a framework for learning full-body volumetric avatars which exploits the advantages of both the 2D and 3D neural rendering techniques. It consists of a Differentiable Rasterization module, DiffRas, that synthesizes a low-resolution version of the target image along with additional latent features guided by a parametric body model. The output of DiffRas is then used as conditioning to our conditional neural 3D representation module (c-NeRF) which generates the final high-res image along with body geometry using volumetric rendering. While DiffRas helps in obtaining photo-realistic image quality, c-NeRF, which employs signed distance fields (SDF) for 3D representations, helps to obtain fine 3D geometric details. Experiments on the challenging ZJU-MoCap and Human3.6M datasets indicate that DRaCoN outperforms state-of-the-art methods both in terms of error metrics and visual quality.
Watch It Move: Unsupervised Discovery of 3D Joints for Re-Posing of Articulated Objects
Dec 21, 2021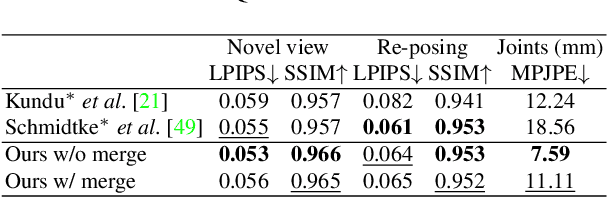
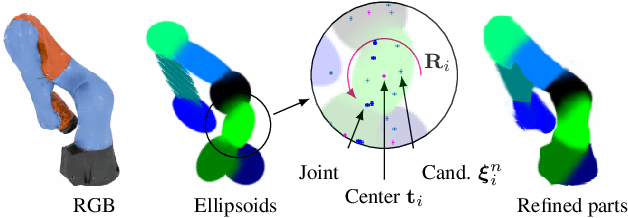
Rendering articulated objects while controlling their poses is critical to applications such as virtual reality or animation for movies. Manipulating the pose of an object, however, requires the understanding of its underlying structure, that is, its joints and how they interact with each other. Unfortunately, assuming the structure to be known, as existing methods do, precludes the ability to work on new object categories. We propose to learn both the appearance and the structure of previously unseen articulated objects by observing them move from multiple views, with no additional supervision, such as joints annotations, or information about the structure. Our insight is that adjacent parts that move relative to each other must be connected by a joint. To leverage this observation, we model the object parts in 3D as ellipsoids, which allows us to identify joints. We combine this explicit representation with an implicit one that compensates for the approximation introduced. We show that our method works for different structures, from quadrupeds, to single-arm robots, to humans.
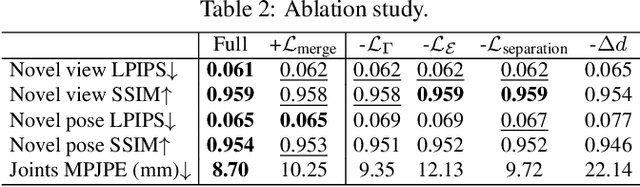
GLAMR: Global Occlusion-Aware Human Mesh Recovery with Dynamic Cameras
Dec 02, 2021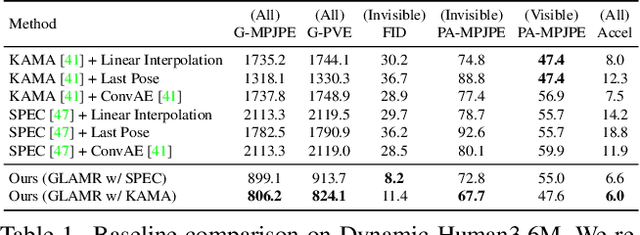
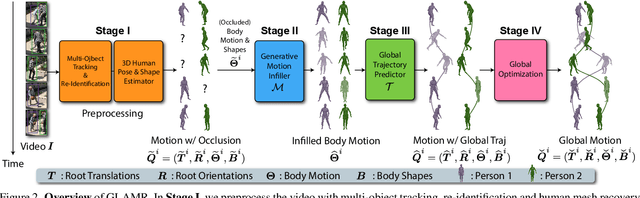
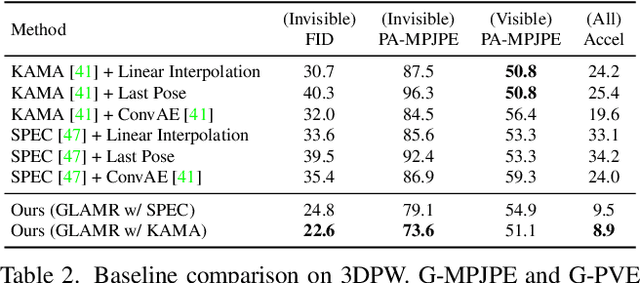
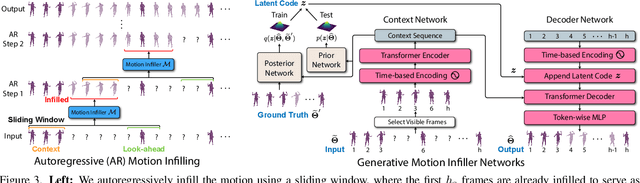
We present an approach for 3D global human mesh recovery from monocular videos recorded with dynamic cameras. Our approach is robust to severe and long-term occlusions and tracks human bodies even when they go outside the camera's field of view. To achieve this, we first propose a deep generative motion infiller, which autoregressively infills the body motions of occluded humans based on visible motions. Additionally, in contrast to prior work, our approach reconstructs human meshes in consistent global coordinates even with dynamic cameras. Since the joint reconstruction of human motions and camera poses is underconstrained, we propose a global trajectory predictor that generates global human trajectories based on local body movements. Using the predicted trajectories as anchors, we present a global optimization framework that refines the predicted trajectories and optimizes the camera poses to match the video evidence such as 2D keypoints. Experiments on challenging indoor and in-the-wild datasets with dynamic cameras demonstrate that the proposed approach outperforms prior methods significantly in terms of motion infilling and global mesh recovery.
Self-Supervised Object Detection via Generative Image Synthesis
Oct 19, 2021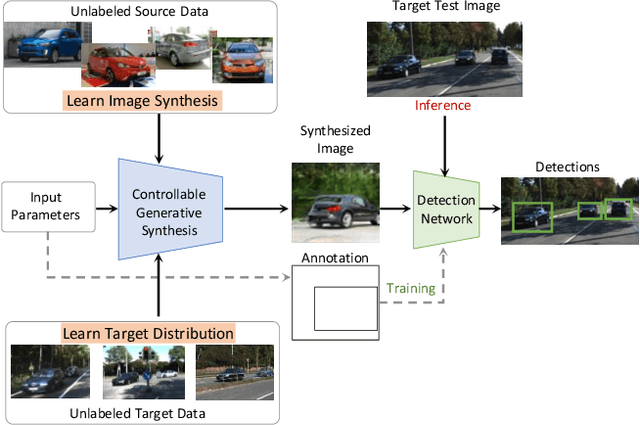
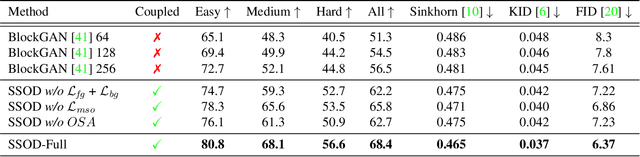
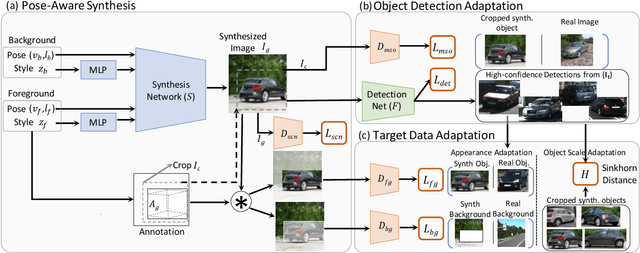
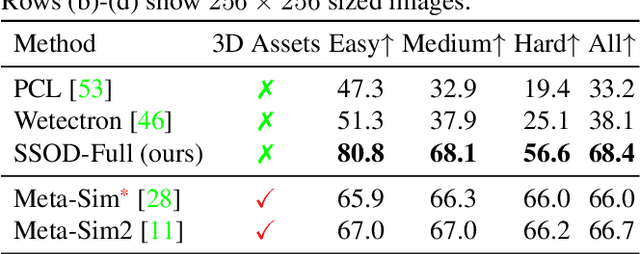
We present SSOD, the first end-to-end analysis-by synthesis framework with controllable GANs for the task of self-supervised object detection. We use collections of real world images without bounding box annotations to learn to synthesize and detect objects. We leverage controllable GANs to synthesize images with pre-defined object properties and use them to train object detectors. We propose a tight end-to-end coupling of the synthesis and detection networks to optimally train our system. Finally, we also propose a method to optimally adapt SSOD to an intended target data without requiring labels for it. For the task of car detection, on the challenging KITTI and Cityscapes datasets, we show that SSOD outperforms the prior state-of-the-art purely image-based self-supervised object detection method Wetectron. Even without requiring any 3D CAD assets, it also surpasses the state-of-the-art rendering based method Meta-Sim2. Our work advances the field of self-supervised object detection by introducing a successful new paradigm of using controllable GAN-based image synthesis for it and by significantly improving the baseline accuracy of the task. We open-source our code at https://github.com/NVlabs/SSOD.
Physics-based Human Motion Estimation and Synthesis from Videos
Sep 21, 2021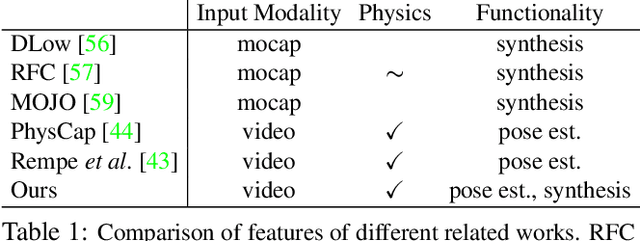
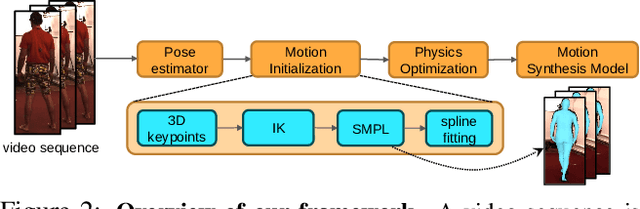


Human motion synthesis is an important problem with applications in graphics, gaming and simulation environments for robotics. Existing methods require accurate motion capture data for training, which is costly to obtain. Instead, we propose a framework for training generative models of physically plausible human motion directly from monocular RGB videos, which are much more widely available. At the core of our method is a novel optimization formulation that corrects imperfect image-based pose estimations by enforcing physics constraints and reasons about contacts in a differentiable way. This optimization yields corrected 3D poses and motions, as well as their corresponding contact forces. Results show that our physically-corrected motions significantly outperform prior work on pose estimation. We can then use these to train a generative model to synthesize future motion. We demonstrate both qualitatively and quantitatively significantly improved motion estimation, synthesis quality and physical plausibility achieved by our method on the large scale Human3.6m dataset \cite{h36m_pami} as compared to prior kinematic and physics-based methods. By enabling learning of motion synthesis from video, our method paves the way for large-scale, realistic and diverse motion synthesis.
Adversarial Motion Modelling helps Semi-supervised Hand Pose Estimation
Jun 10, 2021
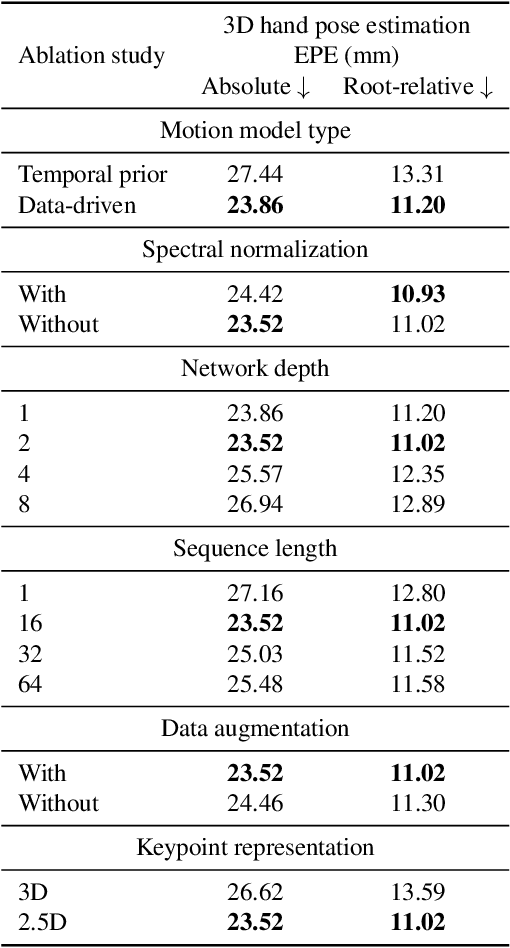
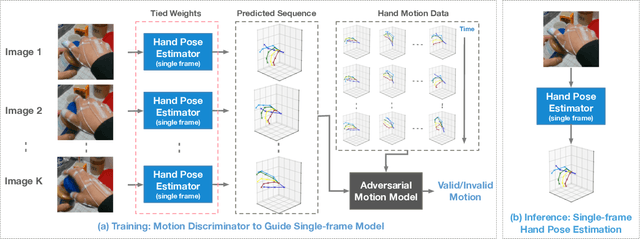

Hand pose estimation is difficult due to different environmental conditions, object- and self-occlusion as well as diversity in hand shape and appearance. Exhaustively covering this wide range of factors in fully annotated datasets has remained impractical, posing significant challenges for generalization of supervised methods. Embracing this challenge, we propose to combine ideas from adversarial training and motion modelling to tap into unlabeled videos. To this end we propose what to the best of our knowledge is the first motion model for hands and show that an adversarial formulation leads to better generalization properties of the hand pose estimator via semi-supervised training on unlabeled video sequences. In this setting, the pose predictor must produce a valid sequence of hand poses, as determined by a discriminative adversary. This adversary reasons both on the structural as well as temporal domain, effectively exploiting the spatio-temporal structure in the task. The main advantage of our approach is that we can make use of unpaired videos and joint sequence data both of which are much easier to attain than paired training data. We perform extensive evaluation, investigating essential components needed for the proposed framework and empirically demonstrate in two challenging settings that the proposed approach leads to significant improvements in pose estimation accuracy. In the lowest label setting, we attain an improvement of $40\%$ in absolute mean joint error.
Weakly-Supervised Physically Unconstrained Gaze Estimation
May 20, 2021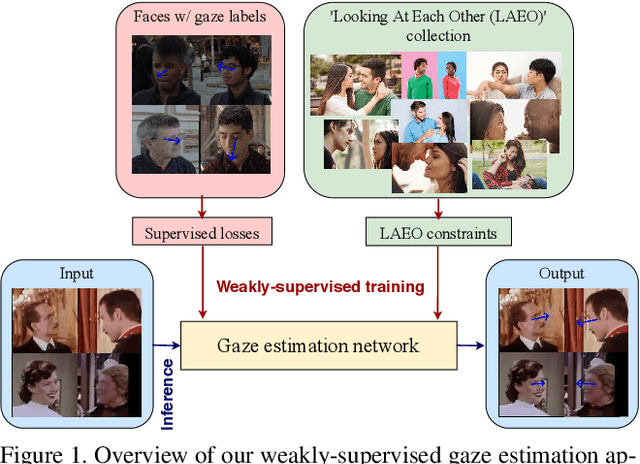
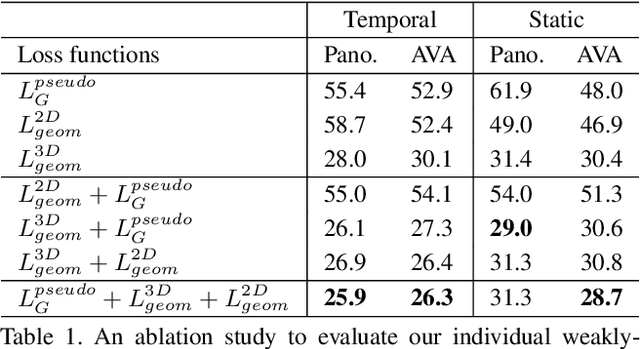
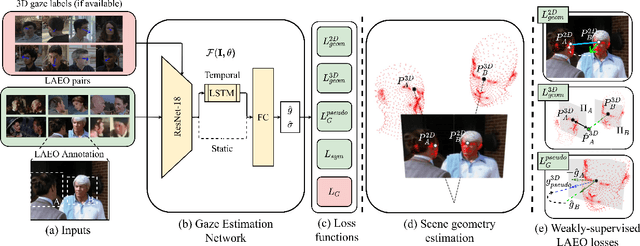
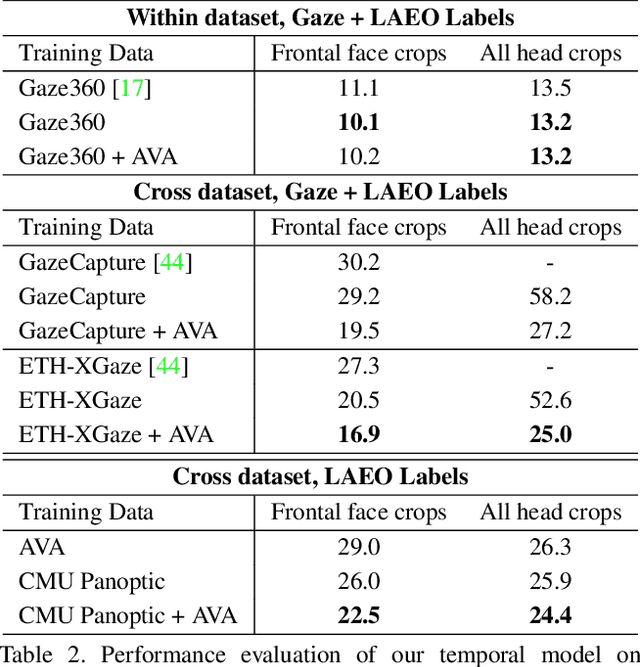
A major challenge for physically unconstrained gaze estimation is acquiring training data with 3D gaze annotations for in-the-wild and outdoor scenarios. In contrast, videos of human interactions in unconstrained environments are abundantly available and can be much more easily annotated with frame-level activity labels. In this work, we tackle the previously unexplored problem of weakly-supervised gaze estimation from videos of human interactions. We leverage the insight that strong gaze-related geometric constraints exist when people perform the activity of "looking at each other" (LAEO). To acquire viable 3D gaze supervision from LAEO labels, we propose a training algorithm along with several novel loss functions especially designed for the task. With weak supervision from two large scale CMU-Panoptic and AVA-LAEO activity datasets, we show significant improvements in (a) the accuracy of semi-supervised gaze estimation and (b) cross-domain generalization on the state-of-the-art physically unconstrained in-the-wild Gaze360 gaze estimation benchmark. We open source our code at https://github.com/NVlabs/weakly-supervised-gaze.