 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAPA: Neural Art Human Pose Amplifier
Dec 15, 2020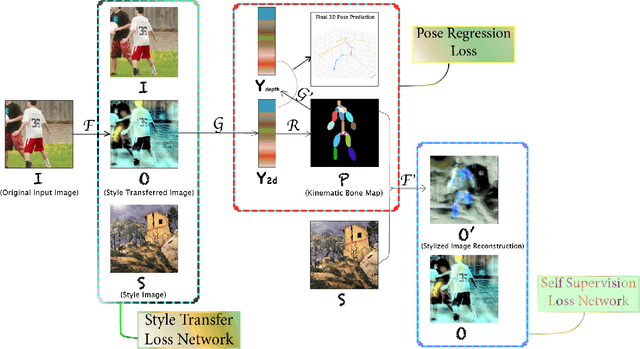
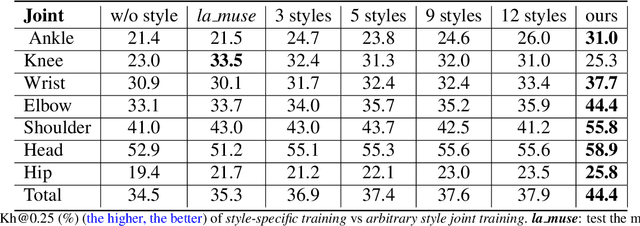


This is the project report for CSCI-GA.2271-001. We target human pose estimation in artistic images. For this goal, we design an end-to-end system that uses neural style transfer for pose regression. We collect a 277-style set for arbitrary style transfer and build an artistic 281-image test set. We directly run pose regression on the test set and show promising results. For pose regression, we propose a 2d-induced bone map from which pose is lifted. To help such a lifting, we additionally annotate the pseudo 3d labels of the full in-the-wild MPII dataset. Further, we append another style transfer as self supervision to improve 2d. We perform extensive ablation studies to analyze the introduced features. We also compare end-to-end with per-style training and allude to the tradeoff between style transfer and pose regression. Lastly, we generalize our model to the real-world human dataset and show its potentiality as a generic pose model. We explain the theoretical foundation in Appendix. We release code at https://github.com/strawberryfg/NAPA-NST-HPE, data, and video.
Measuring Generalisation to Unseen Viewpoints, Articulations, Shapes and Objects for 3D Hand Pose Estimation under Hand-Object Interaction
Mar 30, 2020
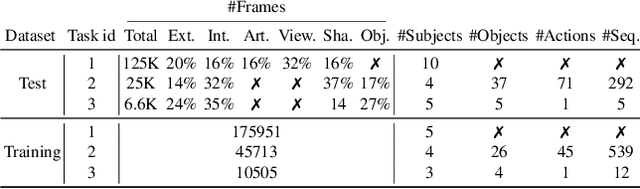
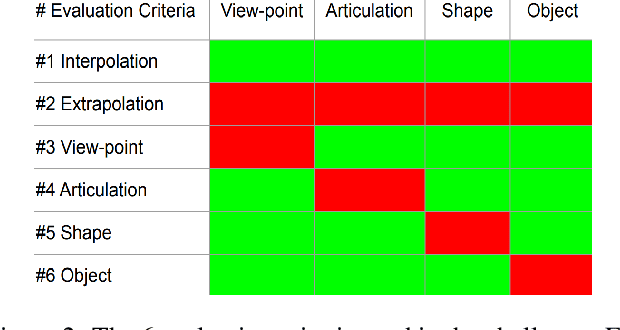
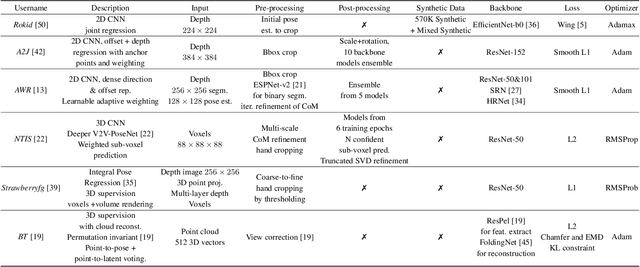
In this work, we study how well different type of approaches generalise in the task of 3D hand pose estimation under hand-object interaction and single hand scenarios. We show that the accuracy of state-of-the-art methods can drop, and that they fail mostly on poses absent from the training set. Unfortunately, since the space of hand poses is highly dimensional, it is inherently not feasible to cover the whole space densely, despite recent efforts in collecting large-scale training datasets. This sampling problem is even more severe when hands are interacting with objects and/or inputs are RGB rather than depth images, as RGB images also vary with lighting conditions and colors. To address these issues, we designed a public challenge to evaluate the abilities of current 3D hand pose estimators~(HPEs) to interpolate and extrapolate the poses of a training set. More exactly, our challenge is designed (a) to evaluate the influence of both depth and color modalities on 3D hand pose estimation, under the presence or absence of objects; (b) to assess the generalisation abilities \wrt~four main axes: shapes, articulations, viewpoints, and objects; (c) to explore the use of a synthetic hand model to fill the gaps of current datasets. Through the challenge, the overall accuracy has dramatically improved over the baseline, especially on extrapolation tasks, from 27mm to 13mm mean joint error. Our analyses highlight the impacts of: Data pre-processing, ensemble approaches, the use of MANO model, and different HPE methods/backbones.
Patch-based 3D Human Pose Refinement
May 20, 2019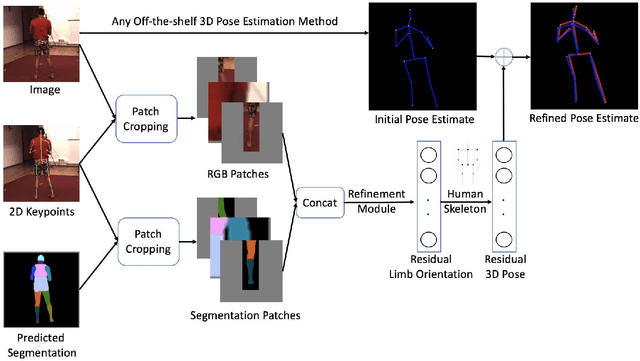
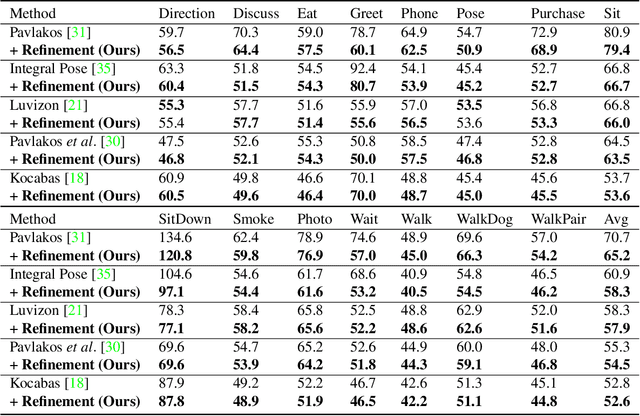


State-of-the-art 3D human pose estimation approaches typically estimate pose from the entire RGB image in a single forward run. In this paper, we develop a post-processing step to refine 3D human pose estimation from body part patches. Using local patches as input has two advantages. First, the fine details around body parts are zoomed in to high resolution for preciser 3D pose prediction. Second, it enables the part appearance to be shared between poses to benefit rare poses. In order to acquire informative representation of patches, we explore different input modalities and validate the superiority of fusing predicted segmentation with RGB. We show that our method consistently boosts the accuracy of state-of-the-art 3D human pose methods.
Depth-Based 3D Hand Pose Estimation: From Current Achievements to Future Goals
Mar 29, 2018
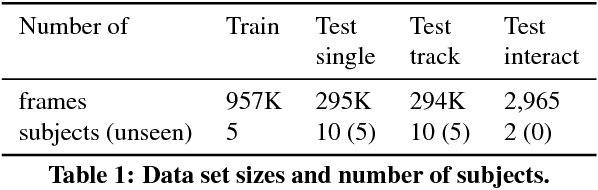
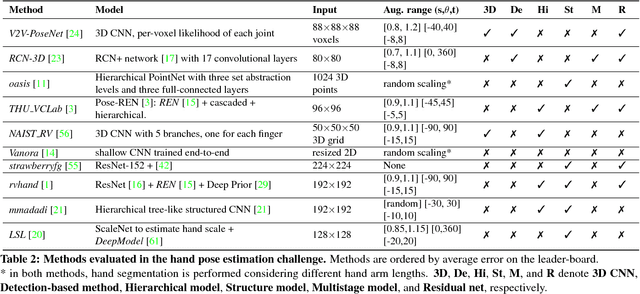
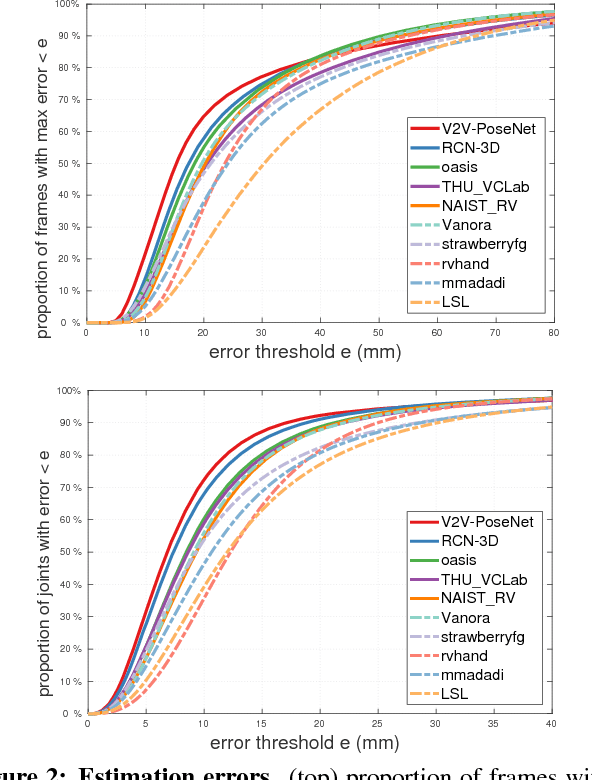
In this paper, we strive to answer two questions: What is the current state of 3D hand pose estimation from depth images? And, what are the next challenges that need to be tackled? Following the successful Hands In the Million Challenge (HIM2017), we investigate the top 10 state-of-the-art methods on three tasks: single frame 3D pose estimation, 3D hand tracking, and hand pose estimation during object interaction. We analyze the performance of different CNN structures with regard to hand shape, joint visibility, view point and articulation distributions. Our findings include: (1) isolated 3D hand pose estimation achieves low mean errors (10 mm) in the view point range of [70, 120] degrees, but it is far from being solved for extreme view points; (2) 3D volumetric representations outperform 2D CNNs, better capturing the spatial structure of the depth data; (3) Discriminative methods still generalize poorly to unseen hand shapes; (4) While joint occlusions pose a challenge for most methods, explicit modeling of structure constraints can significantly narrow the gap between errors on visible and occluded joints.
DeepSkeleton: Skeleton Map for 3D Human Pose Regression
Nov 29, 2017
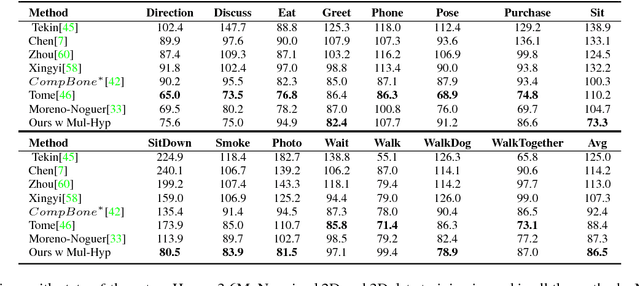
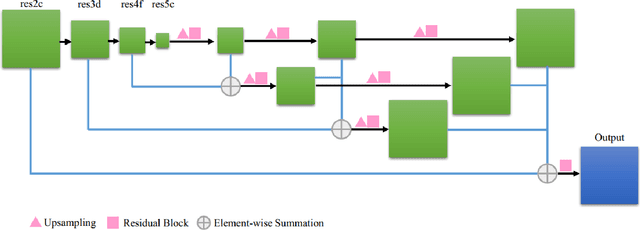
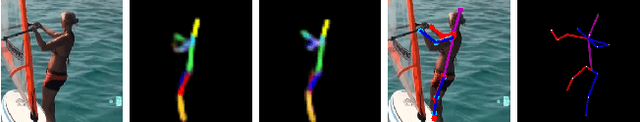
Despite recent success on 2D human pose estimation, 3D human pose estimation still remains an open problem. A key challenge is the ill-posed depth ambiguity nature. This paper presents a novel intermediate feature representation named skeleton map for regression. It distills structural context from irrelavant properties of RGB image e.g. illumination and texture. It is simple, clean and can be easily generated via deconvolution network. For the first time, we show that training regression network from skeleton map alone is capable of meeting the performance of state-of-theart 3D human pose estimation works. We further exploit the power of multiple 3D hypothesis generation to obtain reasonbale 3D pose in consistent with 2D pose detection. The effectiveness of our approach is validated on challenging in-the-wild dataset MPII and indoor dataset Human3.6M.
Model-based Deep Hand Pose Estimation
Jun 22, 2016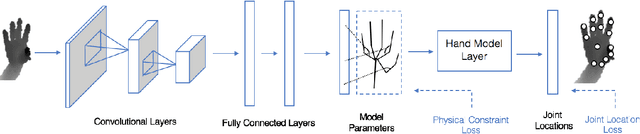
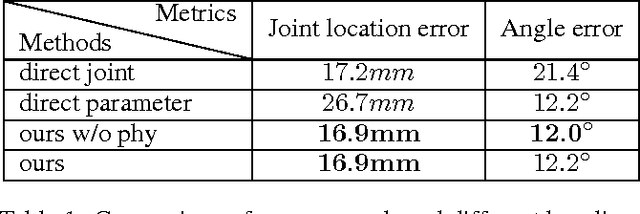
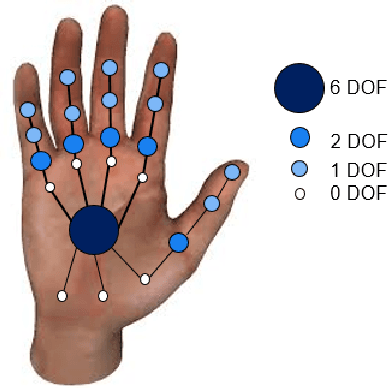
Previous learning based hand pose estimation methods does not fully exploit the prior information in hand model geometry. Instead, they usually rely a separate model fitting step to generate valid hand poses. Such a post processing is inconvenient and sub-optimal. In this work, we propose a model based deep learning approach that adopts a forward kinematics based layer to ensure the geometric validity of estimated poses. For the first time, we show that embedding such a non-linear generative process in deep learning is feasible for hand pose estimation. Our approach is verified on challenging public datasets and achieves state-of-the-art performance.