 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Viewpoint Learning From Image Collections
Paper and Code
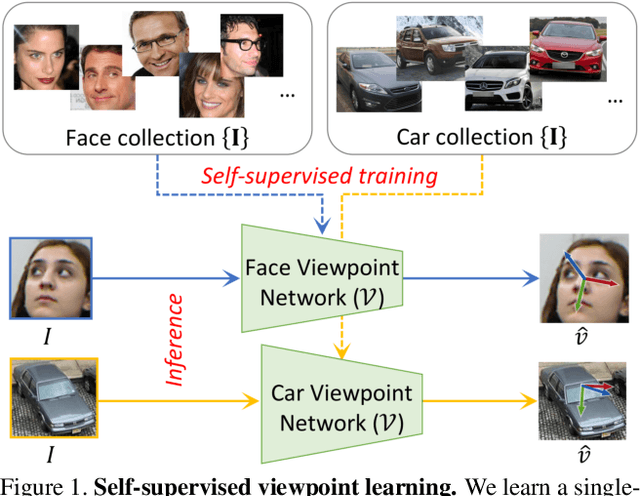
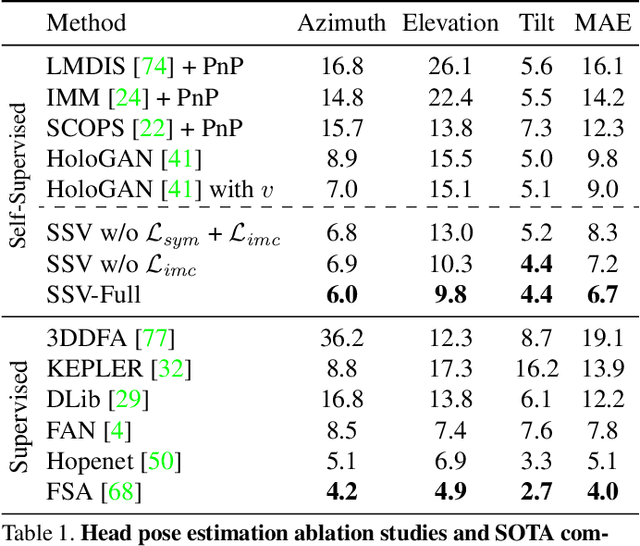
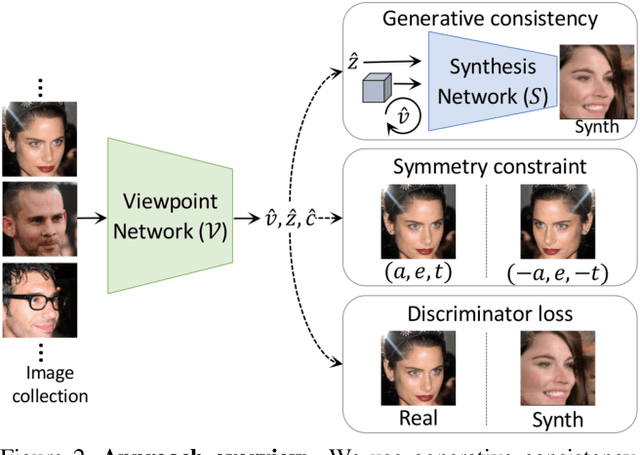
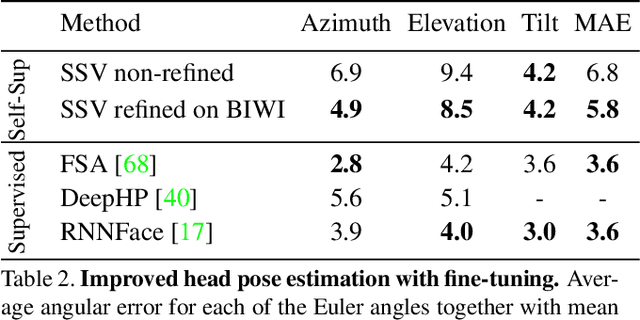
Training deep neural networks to estimate the viewpoint of objects requires large labeled training datasets. However, manually labeling viewpoints is notoriously hard, error-prone, and time-consuming. On the other hand, it is relatively easy to mine many unlabelled images of an object category from the internet, e.g., of cars or faces. We seek to answer the research question of whether such unlabeled collections of in-the-wild images can be successfully utilized to train viewpoint estimation networks for general object categories purely via self-supervision. Self-supervision here refers to the fact that the only true supervisory signal that the network has is the input image itself. We propose a novel learning framework which incorporates an analysis-by-synthesis paradigm to reconstruct images in a viewpoint aware manner with a generative network, along with symmetry and adversarial constraints to successfully supervise our viewpoint estimation network. We show that our approach performs competitively to fully-supervised approaches for several object categories like human faces, cars, buses, and trains. Our work opens up further research in self-supervised viewpoint learning and serves as a robust baseline for it. We open-source our code at https://github.com/NVlabs/SSV.