 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnny-Fit: All-Age Human Mesh Recovery
May 06, 2026Recovering 3D human pose and shape from a single image remains a cornerstone of human-centric vision, yet most methods assume adult subjects and optimize each person independently. These assumptions fail in real-world, all-age scenes, where body proportions and depth must be resolved jointly. We introduce Anny-Fit, a multi-person, camera-space optimization framework for all-age 3D human mesh recovery (HMR). Unlike existing per-person fitting methods, Anny-Fit jointly optimizes all individuals directly in the camera coordinate system, enforcing global spatial consistency. At the core of our approach is the use of multiple forms of expert knowledge -- including metric depth maps, instance segmentation, 2D keypoints, and, VLM-derived semantic attributes such as age and gender -- each obtained from dedicated off-the-shelf networks. These complementary signals jointly guide the optimization, constraining the depth-scale ambiguity characteristic of all-age scenes. Across diverse datasets, Anny-Fit consistently improves 2D reprojection accuracy (+13 to 16), relative depth ordering (+6 to 7), 3D estimation error (-9 to -29) and shape estimation (+25 to +82), producing more coherent scenes. Finally, we show that VLM-based semantic knowledge can be distilled into an HMR model via the pseudo-ground-truth annotations produced by Anny-Fit on training data, enabling it to learn semantically meaningful shape parameters while improving HMR performance. Our approach bridges adult-only and all-age modeling by enabling zero-shot adaptation of adult-trained HMR pipelines to the full age spectrum without retraining. Code is publicly available at https://github.com/naver/anny-fit.
Human Mesh Modeling for Anny Body
Nov 05, 2025Parametric body models are central to many human-centric tasks, yet existing models often rely on costly 3D scans and learned shape spaces that are proprietary and demographically narrow. We introduce Anny, a simple, fully differentiable, and scan-free human body model grounded in anthropometric knowledge from the MakeHuman community. Anny defines a continuous, interpretable shape space, where phenotype parameters (e.g. gender, age, height, weight) control blendshapes spanning a wide range of human forms -- across ages (from infants to elders), body types, and proportions. Calibrated using WHO population statistics, it provides realistic and demographically grounded human shape variation within a single unified model. Thanks to its openness and semantic control, Anny serves as a versatile foundation for 3D human modeling -- supporting millimeter-accurate scan fitting, controlled synthetic data generation, and Human Mesh Recovery (HMR). We further introduce Anny-One, a collection of 800k photorealistic humans generated with Anny, showing that despite its simplicity, HMR models trained with Anny can match the performance of those trained with scan-based body models, while remaining interpretable and broadly representative. The Anny body model and its code are released under the Apache 2.0 license, making Anny an accessible foundation for human-centric 3D modeling.
Disentangled Object-Centric Image Representation for Robotic Manipulation
Mar 14, 2025Learning robotic manipulation skills from vision is a promising approach for developing robotics applications that can generalize broadly to real-world scenarios. As such, many approaches to enable this vision have been explored with fruitful results. Particularly, object-centric representation methods have been shown to provide better inductive biases for skill learning, leading to improved performance and generalization. Nonetheless, we show that object-centric methods can struggle to learn simple manipulation skills in multi-object environments. Thus, we propose DOCIR, an object-centric framework that introduces a disentangled representation for objects of interest, obstacles, and robot embodiment. We show that this approach leads to state-of-the-art performance for learning pick and place skills from visual inputs in multi-object environments and generalizes at test time to changing objects of interest and distractors in the scene. Furthermore, we show its efficacy both in simulation and zero-shot transfer to the real world.
Multi-HMR: Multi-Person Whole-Body Human Mesh Recovery in a Single Shot
Feb 22, 2024



We present Multi-HMR, a strong single-shot model for multi-person 3D human mesh recovery from a single RGB image. Predictions encompass the whole body, i.e, including hands and facial expressions, using the SMPL-X parametric model and spatial location in the camera coordinate system. Our model detects people by predicting coarse 2D heatmaps of person centers, using features produced by a standard Vision Transformer (ViT) backbone. It then predicts their whole-body pose, shape and spatial location using a new cross-attention module called the Human Prediction Head (HPH), with one query per detected center token, attending to the entire set of features. As direct prediction of SMPL-X parameters yields suboptimal results, we introduce CUFFS; the Close-Up Frames of Full-Body Subjects dataset, containing humans close to the camera with diverse hand poses. We show that incorporating this dataset into training further enhances predictions, particularly for hands, enabling us to achieve state-of-the-art performance. Multi-HMR also optionally accounts for camera intrinsics, if available, by encoding camera ray directions for each image token. This simple design achieves strong performance on whole-body and body-only benchmarks simultaneously. We train models with various backbone sizes and input resolutions. In particular, using a ViT-S backbone and $448\times448$ input images already yields a fast and competitive model with respect to state-of-the-art methods, while considering larger models and higher resolutions further improve performance.
Cross-view and Cross-pose Completion for 3D Human Understanding
Nov 15, 2023



Human perception and understanding is a major domain of computer vision which, like many other vision subdomains recently, stands to gain from the use of large models pre-trained on large datasets. We hypothesize that the most common pre-training strategy of relying on general purpose, object-centric image datasets such as ImageNet, is limited by an important domain shift. On the other hand, collecting domain specific ground truth such as 2D or 3D labels does not scale well. Therefore, we propose a pre-training approach based on self-supervised learning that works on human-centric data using only images. Our method uses pairs of images of humans: the first is partially masked and the model is trained to reconstruct the masked parts given the visible ones and a second image. It relies on both stereoscopic (cross-view) pairs, and temporal (cross-pose) pairs taken from videos, in order to learn priors about 3D as well as human motion. We pre-train a model for body-centric tasks and one for hand-centric tasks. With a generic transformer architecture, these models outperform existing self-supervised pre-training methods on a wide set of human-centric downstream tasks, and obtain state-of-the-art performance for instance when fine-tuning for model-based and model-free human mesh recovery.
MFOS: Model-Free & One-Shot Object Pose Estimation
Oct 03, 2023



Existing learning-based methods for object pose estimation in RGB images are mostly model-specific or category based. They lack the capability to generalize to new object categories at test time, hence severely hindering their practicability and scalability. Notably, recent attempts have been made to solve this issue, but they still require accurate 3D data of the object surface at both train and test time. In this paper, we introduce a novel approach that can estimate in a single forward pass the pose of objects never seen during training, given minimum input. In contrast to existing state-of-the-art approaches, which rely on task-specific modules, our proposed model is entirely based on a transformer architecture, which can benefit from recently proposed 3D-geometry general pretraining. We conduct extensive experiments and report state-of-the-art one-shot performance on the challenging LINEMOD benchmark. Finally, extensive ablations allow us to determine good practices with this relatively new type of architecture in the field.
SACReg: Scene-Agnostic Coordinate Regression for Visual Localization
Jul 28, 2023Scene coordinates regression (SCR), i.e., predicting 3D coordinates for every pixel of a given image, has recently shown promising potential. However, existing methods remain mostly scene-specific or limited to small scenes and thus hardly scale to realistic datasets. In this paper, we propose a new paradigm where a single generic SCR model is trained once to be then deployed to new test scenes, regardless of their scale and without further finetuning. For a given query image, it collects inputs from off-the-shelf image retrieval techniques and Structure-from-Motion databases: a list of relevant database images with sparse pointwise 2D-3D annotations. The model is based on the transformer architecture and can take a variable number of images and sparse 2D-3D annotations as input. It is trained on a few diverse datasets and significantly outperforms other scene regression approaches on several benchmarks, including scene-specific models, for visual localization. In particular, we set a new state of the art on the Cambridge localization benchmark, even outperforming feature-matching-based approaches.
Improved Cross-view Completion Pre-training for Stereo Matching
Nov 18, 2022



Despite impressive performance for high-level downstream tasks, self-supervised pre-training methods have not yet fully delivered on dense geometric vision tasks such as stereo matching. The application of self-supervised learning concepts, such as instance discrimination or masked image modeling, to geometric tasks is an active area of research. In this work we build on the recent cross-view completion framework: this variation of masked image modeling leverages a second view from the same scene, which is well suited for binocular downstream tasks. However, the applicability of this concept has so far been limited in at least two ways: (a) by the difficulty of collecting real-world image pairs - in practice only synthetic data had been used - and (b) by the lack of generalization of vanilla transformers to dense downstream tasks for which relative position is more meaningful than absolute position. We explore three avenues of improvement: first, we introduce a method to collect suitable real-world image pairs at large scale. Second, we experiment with relative positional embeddings and demonstrate that they enable vision transformers to perform substantially better. Third, we scale up vision transformer based cross-completion architectures, which is made possible by the use of large amounts of data. With these improvements, we show for the first time that state-of-the-art results on deep stereo matching can be reached without using any standard task-specific techniques like correlation volume, iterative estimation or multi-scale reasoning.
Multi-Finger Grasping Like Humans
Nov 14, 2022Robots with multi-fingered grippers could perform advanced manipulation tasks for us if we were able to properly specify to them what to do. In this study, we take a step in that direction by making a robot grasp an object like a grasping demonstration performed by a human. We propose a novel optimization-based approach for transferring human grasp demonstrations to any multi-fingered grippers, which produces robotic grasps that mimic the human hand orientation and the contact area with the object, while alleviating interpenetration. Extensive experiments with the Allegro and BarrettHand grippers show that our method leads to grasps more similar to the human demonstration than existing approaches, without requiring any gripper-specific tuning. We confirm these findings through a user study and validate the applicability of our approach on a real robot.
* presented at IROS 2022 conference
CroCo: Self-Supervised Pre-training for 3D Vision Tasks by Cross-View Completion
Oct 19, 2022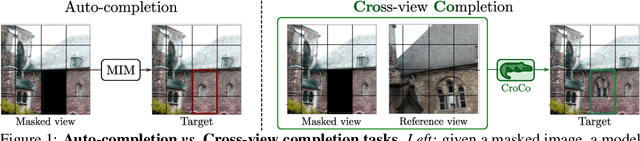
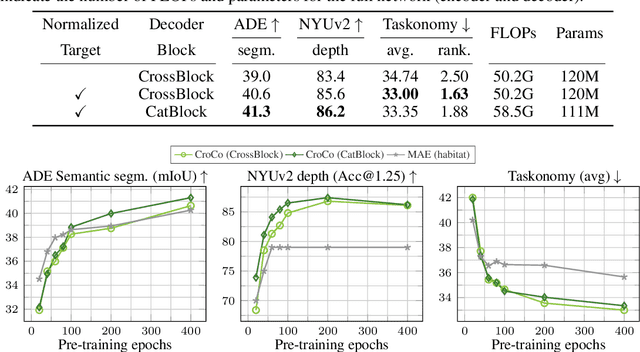


Masked Image Modeling (MIM) has recently been established as a potent pre-training paradigm. A pretext task is constructed by masking patches in an input image, and this masked content is then predicted by a neural network using visible patches as sole input. This pre-training leads to state-of-the-art performance when finetuned for high-level semantic tasks, e.g. image classification and object detection. In this paper we instead seek to learn representations that transfer well to a wide variety of 3D vision and lower-level geometric downstream tasks, such as depth prediction or optical flow estimation. Inspired by MIM, we propose an unsupervised representation learning task trained from pairs of images showing the same scene from different viewpoints. More precisely, we propose the pretext task of cross-view completion where the first input image is partially masked, and this masked content has to be reconstructed from the visible content and the second image. In single-view MIM, the masked content often cannot be inferred precisely from the visible portion only, so the model learns to act as a prior influenced by high-level semantics. In contrast, this ambiguity can be resolved with cross-view completion from the second unmasked image, on the condition that the model is able to understand the spatial relationship between the two images. Our experiments show that our pretext task leads to significantly improved performance for monocular 3D vision downstream tasks such as depth estimation. In addition, our model can be directly applied to binocular downstream tasks like optical flow or relative camera pose estimation, for which we obtain competitive results without bells and whistles, i.e., using a generic architecture without any task-specific design.