 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Foundation Models for Music Understanding
Sep 15, 2024
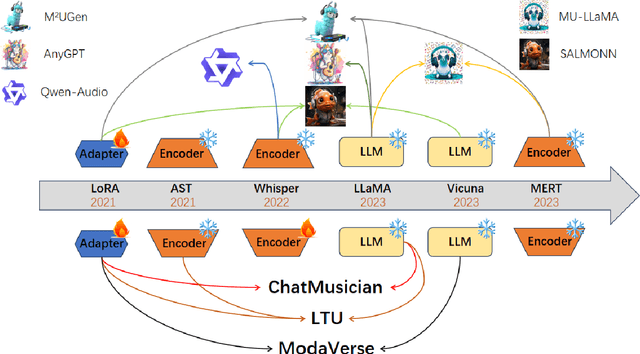
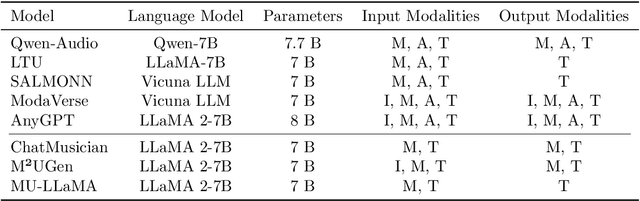
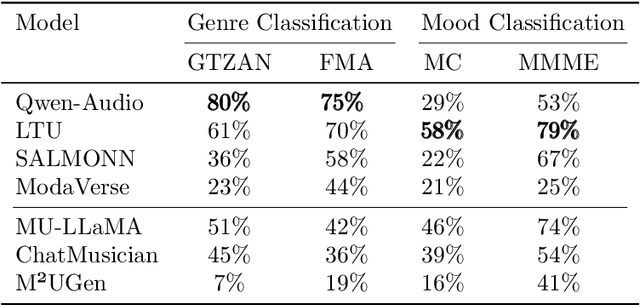
Music is essential in daily life, fulfilling emotional and entertainment needs, and connecting us personally, socially, and culturally. A better understanding of music can enhance our emotions, cognitive skills, and cultural connections. The rapid advancement of artificial intelligence (AI) has introduced new ways to analyze music, aiming to replicate human understanding of music and provide related services. While the traditional models focused on audio features and simple tasks, the recent development of large language models (LLMs) and foundation models (FMs), which excel in various fields by integrating semantic information and demonstrating strong reasoning abilities, could capture complex musical features and patterns, integrate music with language and incorporate rich musical, emotional and psychological knowledge. Therefore, they have the potential in handling complex music understanding tasks from a semantic perspective, producing outputs closer to human perception. This work, to our best knowledge, is one of the early reviews of the intersection of AI techniques and music understanding. We investigated, analyzed, and tested recent large-scale music foundation models in respect of their music comprehension abilities. We also discussed their limitations and proposed possible future directions, offering insights for researchers in this field.
ModalityMirror: Improving Audio Classification in Modality Heterogeneity Federated Learning with Multimodal Distillation
Aug 28, 2024Multimodal Federated Learning frequently encounters challenges of client modality heterogeneity, leading to undesired performances for secondary modality in multimodal learning. It is particularly prevalent in audiovisual learning, with audio is often assumed to be the weaker modality in recognition tasks. To address this challenge, we introduce ModalityMirror to improve audio model performance by leveraging knowledge distillation from an audiovisual federated learning model. ModalityMirror involves two phases: a modality-wise FL stage to aggregate uni-modal encoders; and a federated knowledge distillation stage on multi-modality clients to train an unimodal student model. Our results demonstrate that ModalityMirror significantly improves the audio classification compared to the state-of-the-art FL methods such as Harmony, particularly in audiovisual FL facing video missing. Our approach unlocks the potential for exploiting the diverse modality spectrum inherent in multi-modal FL.
A Comprehensive Review of Multimodal Large Language Models: Performance and Challenges Across Different Tasks
Aug 02, 2024
In an era defined by the explosive growth of data and rapid technological advancements, Multimodal Large Language Models (MLLMs) stand at the forefront of artificial intelligence (AI) systems. Designed to seamlessly integrate diverse data types-including text, images, videos, audio, and physiological sequences-MLLMs address the complexities of real-world applications far beyond the capabilities of single-modality systems. In this paper, we systematically sort out the applications of MLLM in multimodal tasks such as natural language, vision, and audio. We also provide a comparative analysis of the focus of different MLLMs in the tasks, and provide insights into the shortcomings of current MLLMs, and suggest potential directions for future research. Through these discussions, this paper hopes to provide valuable insights for the further development and application of MLLM.
Potential of Multimodal Large Language Models for Data Mining of Medical Images and Free-text Reports
Jul 08, 2024



Medical images and radiology reports are crucial for diagnosing medical conditions, highlighting the importance of quantitative analysis for clinical decision-making. However, the diversity and cross-source heterogeneity of these data challenge the generalizability of current data-mining methods. Multimodal large language models (MLLMs) have recently transformed many domains, significantly affecting the medical field. Notably, Gemini-Vision-series (Gemini) and GPT-4-series (GPT-4) models have epitomized a paradigm shift in Artificial General Intelligence (AGI) for computer vision, showcasing their potential in the biomedical domain. In this study, we evaluated the performance of the Gemini, GPT-4, and 4 popular large models for an exhaustive evaluation across 14 medical imaging datasets, including 5 medical imaging categories (dermatology, radiology, dentistry, ophthalmology, and endoscopy), and 3 radiology report datasets. The investigated tasks encompass disease classification, lesion segmentation, anatomical localization, disease diagnosis, report generation, and lesion detection. Our experimental results demonstrated that Gemini-series models excelled in report generation and lesion detection but faces challenges in disease classification and anatomical localization. Conversely, GPT-series models exhibited proficiency in lesion segmentation and anatomical localization but encountered difficulties in disease diagnosis and lesion detection. Additionally, both the Gemini series and GPT series contain models that have demonstrated commendable generation efficiency. While both models hold promise in reducing physician workload, alleviating pressure on limited healthcare resources, and fostering collaboration between clinical practitioners and artificial intelligence technologies, substantial enhancements and comprehensive validations remain imperative before clinical deployment.
Embracing Federated Learning: Enabling Weak Client Participation via Partial Model Training
Jun 21, 2024In Federated Learning (FL), clients may have weak devices that cannot train the full model or even hold it in their memory space. To implement large-scale FL applications, thus, it is crucial to develop a distributed learning method that enables the participation of such weak clients. We propose EmbracingFL, a general FL framework that allows all available clients to join the distributed training regardless of their system resource capacity. The framework is built upon a novel form of partial model training method in which each client trains as many consecutive output-side layers as its system resources allow. Our study demonstrates that EmbracingFL encourages each layer to have similar data representations across clients, improving FL efficiency. The proposed partial model training method guarantees convergence to a neighbor of stationary points for non-convex and smooth problems. We evaluate the efficacy of EmbracingFL under a variety of settings with a mixed number of strong, moderate (~40% memory), and weak (~15% memory) clients, datasets (CIFAR-10, FEMNIST, and IMDB), and models (ResNet20, CNN, and LSTM). Our empirical study shows that EmbracingFL consistently achieves high accuracy as like all clients are strong, outperforming the state-of-the-art width reduction methods (i.e. HeteroFL and FjORD).
Creating a Lens of Chinese Culture: A Multimodal Dataset for Chinese Pun Rebus Art Understanding
Jun 14, 2024Large vision-language models (VLMs) have demonstrated remarkable abilities in understanding everyday content. However, their performance in the domain of art, particularly culturally rich art forms, remains less explored. As a pearl of human wisdom and creativity, art encapsulates complex cultural narratives and symbolism. In this paper, we offer the Pun Rebus Art Dataset, a multimodal dataset for art understanding deeply rooted in traditional Chinese culture. We focus on three primary tasks: identifying salient visual elements, matching elements with their symbolic meanings, and explanations for the conveyed messages. Our evaluation reveals that state-of-the-art VLMs struggle with these tasks, often providing biased and hallucinated explanations and showing limited improvement through in-context learning. By releasing the Pun Rebus Art Dataset, we aim to facilitate the development of VLMs that can better understand and interpret culturally specific content, promoting greater inclusiveness beyond English-based corpora.
Revisiting OPRO: The Limitations of Small-Scale LLMs as Optimizers
May 16, 2024Numerous recent works aim to enhance the efficacy of Large Language Models (LLMs) through strategic prompting. In particular, the Optimization by PROmpting (OPRO) approach provides state-of-the-art performance by leveraging LLMs as optimizers where the optimization task is to find instructions that maximize the task accuracy. In this paper, we revisit OPRO for automated prompting with relatively small-scale LLMs, such as LLaMa-2 family and Mistral 7B. Our investigation reveals that OPRO shows limited effectiveness in small-scale LLMs, with limited inference capabilities constraining optimization ability. We suggest future automatic prompting engineering to consider both model capabilities and computational costs. Additionally, for small-scale LLMs, we recommend direct instructions that clearly outline objectives and methodologies as robust prompt baselines, ensuring efficient and effective prompt engineering in ongoing research.
Eye-gaze Guided Multi-modal Alignment Framework for Radiology
Mar 19, 2024



In multi-modal frameworks, the alignment of cross-modal features presents a significant challenge. The predominant approach in multi-modal pre-training emphasizes either global or local alignment between modalities, utilizing extensive datasets. This bottom-up driven method often suffers from a lack of interpretability, a critical concern in radiology. Previous studies have integrated high-level labels in medical images or text, but these still rely on manual annotation, a costly and labor-intensive process. Our work introduces a novel approach by using eye-gaze data, collected synchronously by radiologists during diagnostic evaluations. This data, indicating radiologists' focus areas, naturally links chest X-rays to diagnostic texts. We propose the Eye-gaze Guided Multi-modal Alignment (EGMA) framework to harness eye-gaze data for better alignment of image and text features, aiming to reduce reliance on manual annotations and thus cut training costs. Our model demonstrates robust performance, outperforming other state-of-the-art methods in zero-shot classification and retrieval tasks. The incorporation of easily-obtained eye-gaze data during routine radiological diagnoses signifies a step towards minimizing manual annotation dependency. Additionally, we explore the impact of varying amounts of eye-gaze data on model performance, highlighting the feasibility and utility of integrating this auxiliary data into multi-modal pre-training.
Understanding LLMs: A Comprehensive Overview from Training to Inference
Jan 06, 2024



The introduction of ChatGPT has led to a significant increase in the utilization of Large Language Models (LLMs) for addressing downstream tasks. There's an increasing focus on cost-efficient training and deployment within this context. Low-cost training and deployment of LLMs represent the future development trend. This paper reviews the evolution of large language model training techniques and inference deployment technologies aligned with this emerging trend. The discussion on training includes various aspects, including data preprocessing, training architecture, pre-training tasks, parallel training, and relevant content related to model fine-tuning. On the inference side, the paper covers topics such as model compression, parallel computation, memory scheduling, and structural optimization. It also explores LLMs' utilization and provides insights into their future development.
High Efficiency Inference Accelerating Algorithm for NOMA-based Mobile Edge Computing
Dec 26, 2023Splitting the inference model between device, edge server, and cloud can improve the performance of EI greatly. Additionally, the non-orthogonal multiple access (NOMA), which is the key supporting technologies of B5G/6G, can achieve massive connections and high spectrum efficiency. Motivated by the benefits of NOMA, integrating NOMA with model split in MEC to reduce the inference latency further becomes attractive. However, the NOMA based communication during split inference has not been properly considered in previous works. Therefore, in this paper, we integrate the NOMA into split inference in MEC, and propose the effective communication and computing resource allocation algorithm to accelerate the model inference at edge. Specifically, when the mobile user has a large model inference task needed to be calculated in the NOMA-based MEC, it will take the energy consumption of both device and edge server and the inference latency into account to find the optimal model split strategy, subchannel allocation strategy (uplink and downlink), and transmission power allocation strategy (uplink and downlink). Since the minimum inference delay and energy consumption cannot be satisfied simultaneously, and the variables of subchannel allocation and model split are discrete, the gradient descent (GD) algorithm is adopted to find the optimal tradeoff between them. Moreover, the loop iteration GD approach (Li-GD) is proposed to reduce the complexity of GD algorithm that caused by the parameter discrete. Additionally, the properties of the proposed algorithm are also investigated, which demonstrate the effectiveness of the proposed algorithms.