 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHands-On Tutorial: Labeling with LLM and Human-in-the-Loop
Nov 07, 2024Training and deploying machine learning models relies on a large amount of human-annotated data. As human labeling becomes increasingly expensive and time-consuming, recent research has developed multiple strategies to speed up annotation and reduce costs and human workload: generating synthetic training data, active learning, and hybrid labeling. This tutorial is oriented toward practical applications: we will present the basics of each strategy, highlight their benefits and limitations, and discuss in detail real-life case studies. Additionally, we will walk through best practices for managing human annotators and controlling the quality of the final dataset. The tutorial includes a hands-on workshop, where attendees will be guided in implementing a hybrid annotation setup. This tutorial is designed for NLP practitioners from both research and industry backgrounds who are involved in or interested in optimizing data labeling projects.
Towards Automating Text Annotation: A Case Study on Semantic Proximity Annotation using GPT-4
Jul 04, 2024



This paper explores using GPT-3.5 and GPT-4 to automate the data annotation process with automatic prompting techniques. The main aim of this paper is to reuse human annotation guidelines along with some annotated data to design automatic prompts for LLMs, focusing on the semantic proximity annotation task. Automatic prompts are compared to customized prompts. We further implement the prompting strategies into an open-source text annotation tool, enabling easy online use via the OpenAI API. Our study reveals the crucial role of accurate prompt design and suggests that prompting GPT-4 with human-like instructions is not straightforwardly possible for the semantic proximity task. We show that small modifications to the human guidelines already improve the performance, suggesting possible ways for future research.
Presence or Absence: Are Unknown Word Usages in Dictionaries?
Jun 02, 2024



In this work, we outline the components and results of our system submitted to the AXOLOTL-24 shared task for Finnish, Russian and German languages. Our system is fully unsupervised. It leverages a graph-based clustering approach to predict mappings between unknown word usages and dictionary entries for Subtask 1, and generates dictionary-like definitions for those novel word usages through the state-of-the-art Large Language Models such as GPT-4 and LLaMA-3 for Subtask 2. In Subtask 1, our system outperforms the baseline system by a large margin, and it offers interpretability for the mapping results by distinguishing between matched and unmatched (novel) word usages through our graph-based clustering approach. Our system ranks first in Finnish and German, and ranks second in Russian on the Subtask 2 test-phase leaderboard. These results show the potential of our system in managing dictionary entries, particularly for updating dictionaries to include novel sense entries. Our code and data are made publicly available\footnote{\url{https://github.com/xiaohemaikoo/axolotl24-ABDN-NLP}}.
The LSCD Benchmark: a Testbed for Diachronic Word Meaning Tasks
Mar 29, 2024


Lexical Semantic Change Detection (LSCD) is a complex, lemma-level task, which is usually operationalized based on two subsequently applied usage-level tasks: First, Word-in-Context (WiC) labels are derived for pairs of usages. Then, these labels are represented in a graph on which Word Sense Induction (WSI) is applied to derive sense clusters. Finally, LSCD labels are derived by comparing sense clusters over time. This modularity is reflected in most LSCD datasets and models. It also leads to a large heterogeneity in modeling options and task definitions, which is exacerbated by a variety of dataset versions, preprocessing options and evaluation metrics. This heterogeneity makes it difficult to evaluate models under comparable conditions, to choose optimal model combinations or to reproduce results. Hence, we provide a benchmark repository standardizing LSCD evaluation. Through transparent implementation results become easily reproducible and by standardization different components can be freely combined. The repository reflects the task's modularity by allowing model evaluation for WiC, WSI and LSCD. This allows for careful evaluation of increasingly complex model components providing new ways of model optimization.
Enriching Word Usage Graphs with Cluster Definitions
Mar 26, 2024



We present a dataset of word usage graphs (WUGs), where the existing WUGs for multiple languages are enriched with cluster labels functioning as sense definitions. They are generated from scratch by fine-tuned encoder-decoder language models. The conducted human evaluation has shown that these definitions match the existing clusters in WUGs better than the definitions chosen from WordNet by two baseline systems. At the same time, the method is straightforward to use and easy to extend to new languages. The resulting enriched datasets can be extremely helpful for moving on to explainable semantic change modeling.
Detection of Non-recorded Word Senses in English and Swedish
Mar 04, 2024



This study addresses the task of Unknown Sense Detection in English and Swedish. The primary objective of this task is to determine whether the meaning of a particular word usage is documented in a dictionary or not. For this purpose, sense entries are compared with word usages from modern and historical corpora using a pre-trained Word-in-Context embedder that allows us to model this task in a few-shot scenario. Additionally, we use human annotations to adapt and evaluate our models. Compared to a random sample from a corpus, our model is able to considerably increase the detected number of word usages with non-recorded senses.
The DURel Annotation Tool: Human and Computational Measurement of Semantic Proximity, Sense Clusters and Semantic Change
Nov 21, 2023



We present the DURel tool that implements the annotation of semantic proximity between uses of words into an online, open source interface. The tool supports standardized human annotation as well as computational annotation, building on recent advances with Word-in-Context models. Annotator judgments are clustered with automatic graph clustering techniques and visualized for analysis. This allows to measure word senses with simple and intuitive micro-task judgments between use pairs, requiring minimal preparation efforts. The tool offers additional functionalities to compare the agreement between annotators to guarantee the inter-subjectivity of the obtained judgments and to calculate summary statistics giving insights into sense frequency distributions, semantic variation or changes of senses over time.
LSCDiscovery: A shared task on semantic change discovery and detection in Spanish
May 13, 2022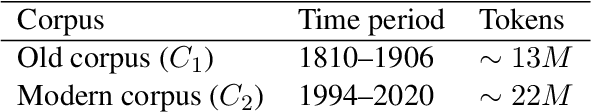
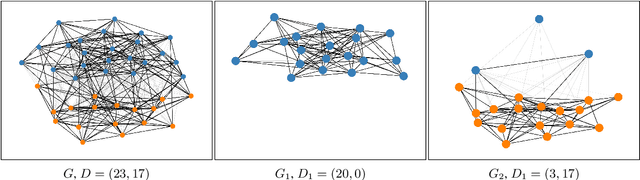

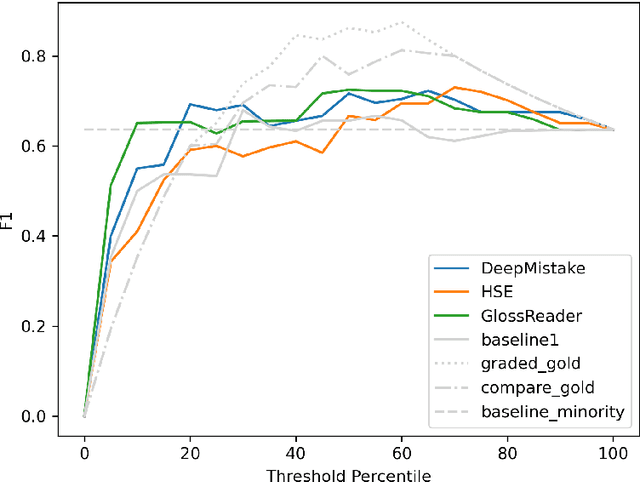
We present the first shared task on semantic change discovery and detection in Spanish and create the first dataset of Spanish words manually annotated for semantic change using the DURel framework (Schlechtweg et al., 2018). The task is divided in two phases: 1) Graded Change Discovery, and 2) Binary Change Detection. In addition to introducing a new language the main novelty with respect to the previous tasks consists in predicting and evaluating changes for all vocabulary words in the corpus. Six teams participated in phase 1 and seven teams in phase 2 of the shared task, and the best system obtained a Spearman rank correlation of 0.735 for phase 1 and an F1 score of 0.716 for phase 2. We describe the systems developed by the competing teams, highlighting the techniques that were particularly useful and discuss the limits of these approaches.
Lexical Semantic Change Discovery
Jun 06, 2021
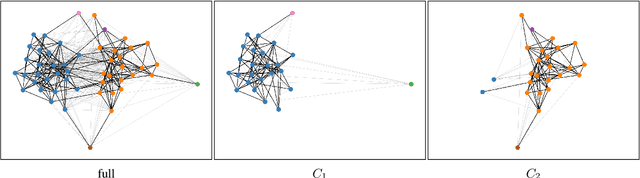

While there is a large amount of research in the field of Lexical Semantic Change Detection, only few approaches go beyond a standard benchmark evaluation of existing models. In this paper, we propose a shift of focus from change detection to change discovery, i.e., discovering novel word senses over time from the full corpus vocabulary. By heavily fine-tuning a type-based and a token-based approach on recently published German data, we demonstrate that both models can successfully be applied to discover new words undergoing meaning change. Furthermore, we provide an almost fully automated framework for both evaluation and discovery.
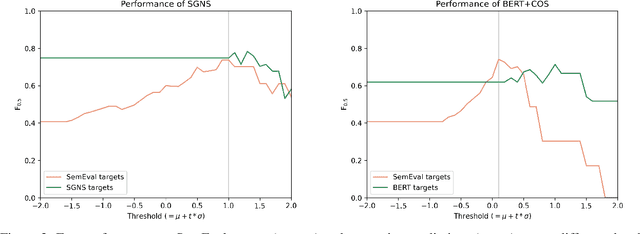
More than just Frequency? Demasking Unsupervised Hypernymy Prediction Methods
May 31, 2021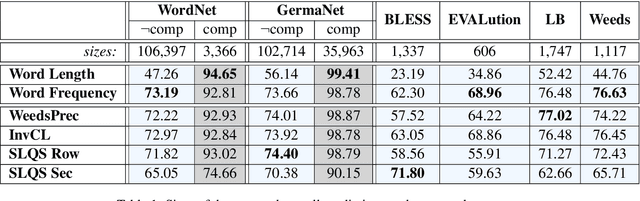

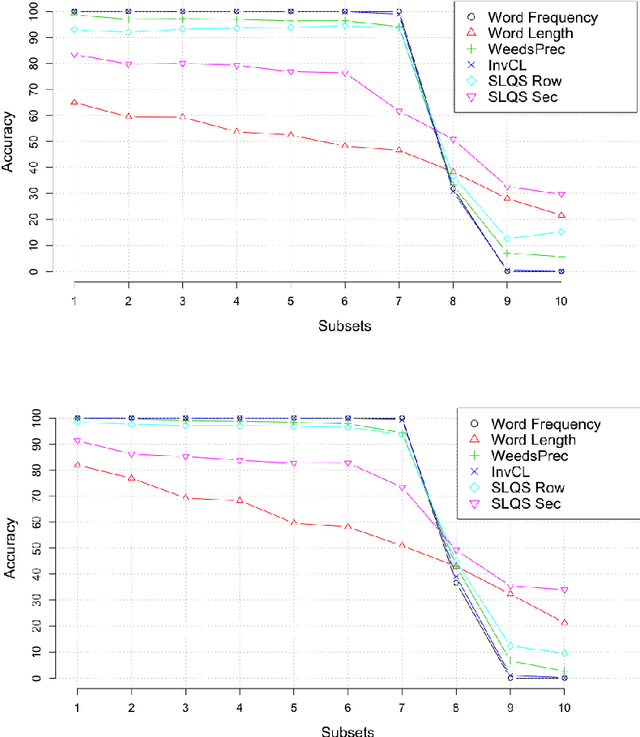
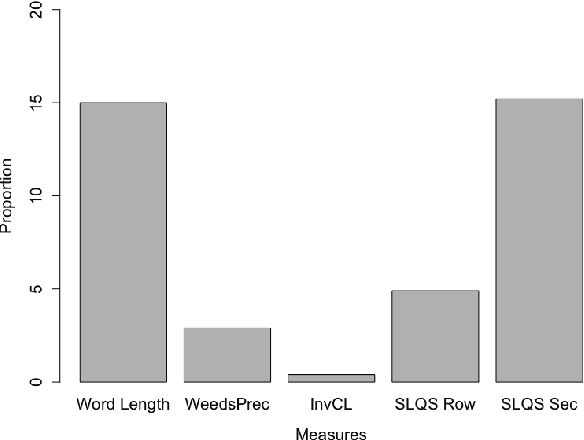
This paper presents a comparison of unsupervised methods of hypernymy prediction (i.e., to predict which word in a pair of words such as fish-cod is the hypernym and which the hyponym). Most importantly, we demonstrate across datasets for English and for German that the predictions of three methods (WeedsPrec, invCL, SLQS Row) strongly overlap and are highly correlated with frequency-based predictions. In contrast, the second-order method SLQS shows an overall lower accuracy but makes correct predictions where the others go wrong. Our study once more confirms the general need to check the frequency bias of a computational method in order to identify frequency-(un)related effects.