 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIFA: Unified Faithfulness Evaluation Framework for Text-to-Video and Video-to-Text Generation
Jul 09, 2025

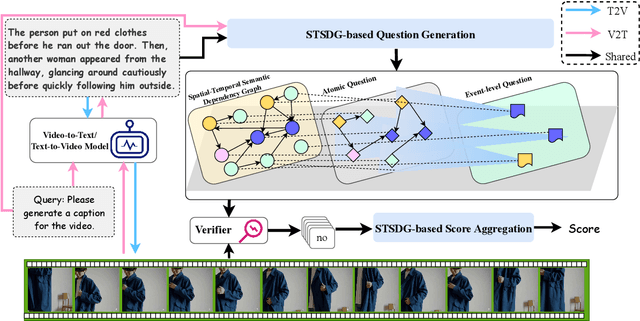
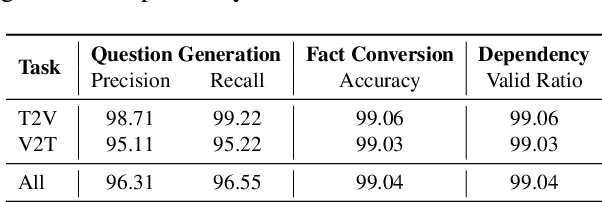
Video Multimodal Large Language Models (VideoMLLMs) have achieved remarkable progress in both Video-to-Text and Text-to-Video tasks. However, they often suffer fro hallucinations, generating content that contradicts the visual input. Existing evaluation methods are limited to one task (e.g., V2T) and also fail to assess hallucinations in open-ended, free-form responses. To address this gap, we propose FIFA, a unified FaIthFulness evAluation framework that extracts comprehensive descriptive facts, models their semantic dependencies via a Spatio-Temporal Semantic Dependency Graph, and verifies them using VideoQA models. We further introduce Post-Correction, a tool-based correction framework that revises hallucinated content. Extensive experiments demonstrate that FIFA aligns more closely with human judgment than existing evaluation methods, and that Post-Correction effectively improves factual consistency in both text and video generation.
BizBench: A Quantitative Reasoning Benchmark for Business and Finance
Nov 11, 2023As large language models (LLMs) impact a growing number of complex domains, it is becoming increasingly important to have fair, accurate, and rigorous evaluation benchmarks. Evaluating the reasoning skills required for business and financial NLP stands out as a particularly difficult challenge. We introduce BizBench, a new benchmark for evaluating models' ability to reason about realistic financial problems. BizBench comprises 8 quantitative reasoning tasks. Notably, BizBench targets the complex task of question-answering (QA) for structured and unstructured financial data via program synthesis (i.e., code generation). We introduce three diverse financially-themed code-generation tasks from newly collected and augmented QA data. Additionally, we isolate distinct financial reasoning capabilities required to solve these QA tasks: reading comprehension of financial text and tables, which is required to extract correct intermediate values; and understanding domain knowledge (e.g., financial formulas) needed to calculate complex solutions. Collectively, these tasks evaluate a model's financial background knowledge, ability to extract numeric entities from financial documents, and capacity to solve problems with code. We conduct an in-depth evaluation of open-source and commercial LLMs, illustrating that BizBench is a challenging benchmark for quantitative reasoning in the finance and business domain.
Trankit: A Light-Weight Transformer-based Toolkit for Multilingual Natural Language Processing
Jan 14, 2021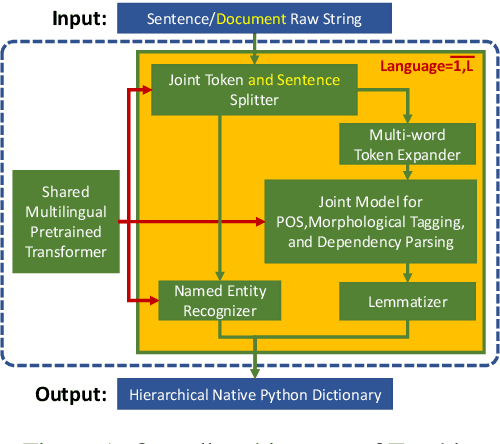
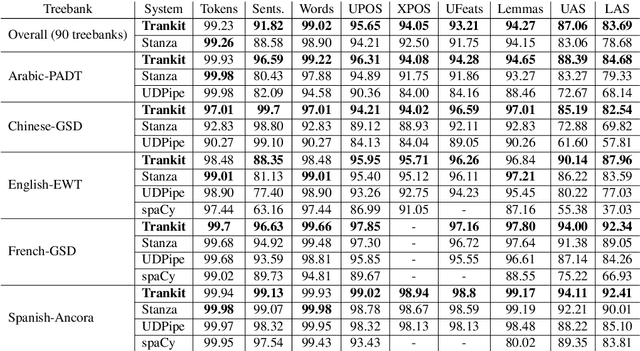
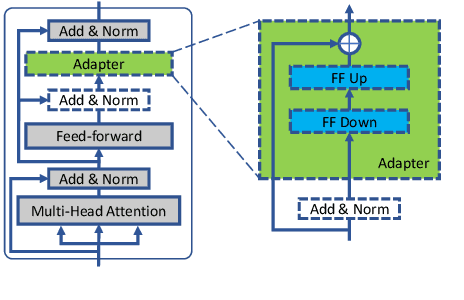

We introduce Trankit, a light-weight Transformer-based Toolkit for multilingual Natural Language Processing (NLP). It provides a trainable pipeline for fundamental NLP tasks over 100 languages, and 90 pretrained pipelines for 56 languages. Built on a state-of-the-art pretrained language model, Trankit significantly outperforms prior multilingual NLP pipelines over sentence segmentation, part-of-speech tagging, morphological feature tagging, and dependency parsing while maintaining competitive performance for tokenization, multi-word token expansion, and lemmatization over 90 Universal Dependencies treebanks. Despite the use of a large pretrained transformer, our toolkit is still efficient in memory usage and speed. This is achieved by our novel plug-and-play mechanism with Adapters where a multilingual pretrained transformer is shared across pipelines for different languages. Our toolkit along with pretrained models and code are publicly available at: https://github.com/nlp-uoregon/trankit. A demo website for our toolkit is also available at: http://nlp.uoregon.edu/trankit. Finally, we create a demo video for Trankit at: https://youtu.be/q0KGP3zGjGc.