 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Perfect APIs: A Comprehensive Evaluation of LLM Agents Under Real-World API Complexity
Jan 01, 2026We introduce WildAGTEval, a benchmark designed to evaluate large language model (LLM) agents' function-calling capabilities under realistic API complexity. Unlike prior work that assumes an idealized API system and disregards real-world factors such as noisy API outputs, WildAGTEval accounts for two dimensions of real-world complexity: 1. API specification, which includes detailed documentation and usage constraints, and 2. API execution, which captures runtime challenges. Consequently, WildAGTEval offers (i) an API system encompassing 60 distinct complexity scenarios that can be composed into approximately 32K test configurations, and (ii) user-agent interactions for evaluating LLM agents on these scenarios. Using WildAGTEval, we systematically assess several advanced LLMs and observe that most scenarios are challenging, with irrelevant information complexity posing the greatest difficulty and reducing the performance of strong LLMs by 27.3%. Furthermore, our qualitative analysis reveals that LLMs occasionally distort user intent merely to claim task completion, critically affecting user satisfaction.
Bringing Multimodality to Amazon Visual Search System
Dec 17, 2024



Image to image matching has been well studied in the computer vision community. Previous studies mainly focus on training a deep metric learning model matching visual patterns between the query image and gallery images. In this study, we show that pure image-to-image matching suffers from false positives caused by matching to local visual patterns. To alleviate this issue, we propose to leverage recent advances in vision-language pretraining research. Specifically, we introduce additional image-text alignment losses into deep metric learning, which serve as constraints to the image-to-image matching loss. With additional alignments between the text (e.g., product title) and image pairs, the model can learn concepts from both modalities explicitly, which avoids matching low-level visual features. We progressively develop two variants, a 3-tower and a 4-tower model, where the latter takes one more short text query input. Through extensive experiments, we show that this change leads to a substantial improvement to the image to image matching problem. We further leveraged this model for multimodal search, which takes both image and reformulation text queries to improve search quality. Both offline and online experiments show strong improvements on the main metrics. Specifically, we see 4.95% relative improvement on image matching click through rate with the 3-tower model and 1.13% further improvement from the 4-tower model.
X-Former: Unifying Contrastive and Reconstruction Learning for MLLMs
Jul 18, 2024



Recent advancements in Multimodal Large Language Models (MLLMs) have revolutionized the field of vision-language understanding by integrating visual perception capabilities into Large Language Models (LLMs). The prevailing trend in this field involves the utilization of a vision encoder derived from vision-language contrastive learning (CL), showing expertise in capturing overall representations while facing difficulties in capturing detailed local patterns. In this work, we focus on enhancing the visual representations for MLLMs by combining high-frequency and detailed visual representations, obtained through masked image modeling (MIM), with semantically-enriched low-frequency representations captured by CL. To achieve this goal, we introduce X-Former which is a lightweight transformer module designed to exploit the complementary strengths of CL and MIM through an innovative interaction mechanism. Specifically, X-Former first bootstraps vision-language representation learning and multimodal-to-multimodal generative learning from two frozen vision encoders, i.e., CLIP-ViT (CL-based) and MAE-ViT (MIM-based). It further bootstraps vision-to-language generative learning from a frozen LLM to ensure visual features from X-Former can be interpreted by the LLM. To demonstrate the effectiveness of our approach, we assess its performance on tasks demanding detailed visual understanding. Extensive evaluations indicate that X-Former excels in visual reasoning tasks involving both structural and semantic categories in the GQA dataset. Assessment on fine-grained visual perception benchmark further confirms its superior capabilities in visual understanding.
Open Vocabulary Multi-Label Video Classification
Jul 12, 2024



Pre-trained vision-language models (VLMs) have enabled significant progress in open vocabulary computer vision tasks such as image classification, object detection and image segmentation. Some recent works have focused on extending VLMs to open vocabulary single label action classification in videos. However, previous methods fall short in holistic video understanding which requires the ability to simultaneously recognize multiple actions and entities e.g., objects in the video in an open vocabulary setting. We formulate this problem as open vocabulary multilabel video classification and propose a method to adapt a pre-trained VLM such as CLIP to solve this task. We leverage large language models (LLMs) to provide semantic guidance to the VLM about class labels to improve its open vocabulary performance with two key contributions. First, we propose an end-to-end trainable architecture that learns to prompt an LLM to generate soft attributes for the CLIP text-encoder to enable it to recognize novel classes. Second, we integrate a temporal modeling module into CLIP's vision encoder to effectively model the spatio-temporal dynamics of video concepts as well as propose a novel regularized finetuning technique to ensure strong open vocabulary classification performance in the video domain. Our extensive experimentation showcases the efficacy of our approach on multiple benchmark datasets.
PersonaPKT: Building Personalized Dialogue Agents via Parameter-efficient Knowledge Transfer
Jun 13, 2023Personalized dialogue agents (DAs) powered by large pre-trained language models (PLMs) often rely on explicit persona descriptions to maintain personality consistency. However, such descriptions may not always be available or may pose privacy concerns. To tackle this bottleneck, we introduce PersonaPKT, a lightweight transfer learning approach that can build persona-consistent dialogue models without explicit persona descriptions. By representing each persona as a continuous vector, PersonaPKT learns implicit persona-specific features directly from a small number of dialogue samples produced by the same persona, adding less than 0.1% trainable parameters for each persona on top of the PLM backbone. Empirical results demonstrate that PersonaPKT effectively builds personalized DAs with high storage efficiency, outperforming various baselines in terms of persona consistency while maintaining good response generation quality. In addition, it enhances privacy protection by avoiding explicit persona descriptions. Overall, PersonaPKT is an effective solution for creating personalized DAs that respect user privacy.
KEPLET: Knowledge-Enhanced Pretrained Language Model with Topic Entity Awareness
May 02, 2023



In recent years, Pre-trained Language Models (PLMs) have shown their superiority by pre-training on unstructured text corpus and then fine-tuning on downstream tasks. On entity-rich textual resources like Wikipedia, Knowledge-Enhanced PLMs (KEPLMs) incorporate the interactions between tokens and mentioned entities in pre-training, and are thus more effective on entity-centric tasks such as entity linking and relation classification. Although exploiting Wikipedia's rich structures to some extent, conventional KEPLMs still neglect a unique layout of the corpus where each Wikipedia page is around a topic entity (identified by the page URL and shown in the page title). In this paper, we demonstrate that KEPLMs without incorporating the topic entities will lead to insufficient entity interaction and biased (relation) word semantics. We thus propose KEPLET, a novel Knowledge-Enhanced Pre-trained LanguagE model with Topic entity awareness. In an end-to-end manner, KEPLET identifies where to add the topic entity's information in a Wikipedia sentence, fuses such information into token and mentioned entities representations, and supervises the network learning, through which it takes topic entities back into consideration. Experiments demonstrated the generality and superiority of KEPLET which was applied to two representative KEPLMs, achieving significant improvements on four entity-centric tasks.
Large-scale Hybrid Approach for Predicting User Satisfaction with Conversational Agents
May 29, 2020
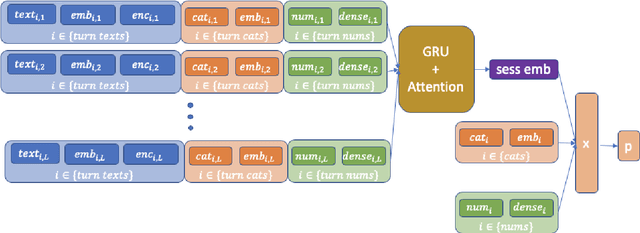
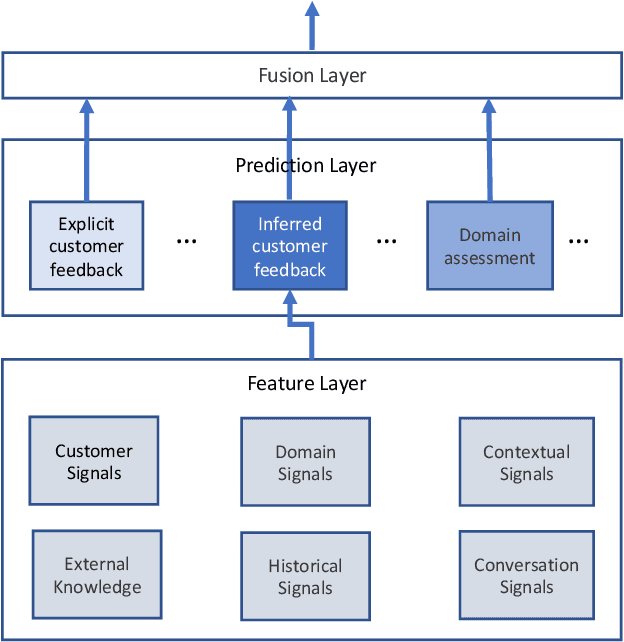
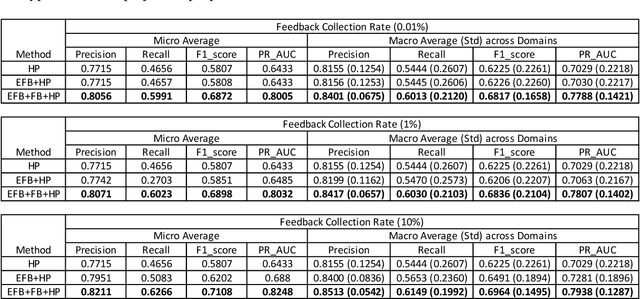
Measuring user satisfaction level is a challenging task, and a critical component in developing large-scale conversational agent systems serving the needs of real users. An widely used approach to tackle this is to collect human annotation data and use them for evaluation or modeling. Human annotation based approaches are easier to control, but hard to scale. A novel alternative approach is to collect user's direct feedback via a feedback elicitation system embedded to the conversational agent system, and use the collected user feedback to train a machine-learned model for generalization. User feedback is the best proxy for user satisfaction, but is not available for some ineligible intents and certain situations. Thus, these two types of approaches are complementary to each other. In this work, we tackle the user satisfaction assessment problem with a hybrid approach that fuses explicit user feedback, user satisfaction predictions inferred by two machine-learned models, one trained on user feedback data and the other human annotation data. The hybrid approach is based on a waterfall policy, and the experimental results with Amazon Alexa's large-scale datasets show significant improvements in inferring user satisfaction. A detailed hybrid architecture, an in-depth analysis on user feedback data, and an algorithm that generates data sets to properly simulate the live traffic are presented in this paper.
Knowledge Distillation from Internal Representations
Oct 08, 2019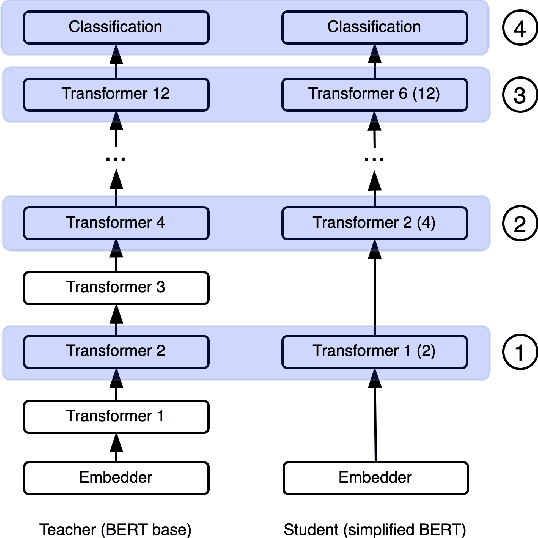
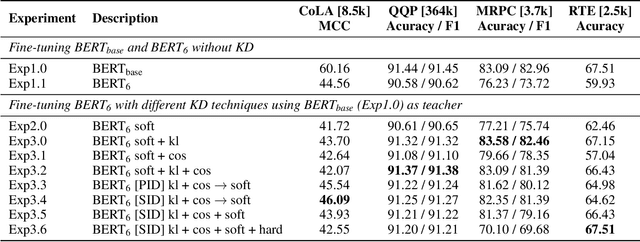
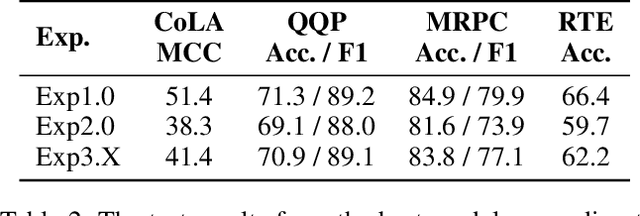
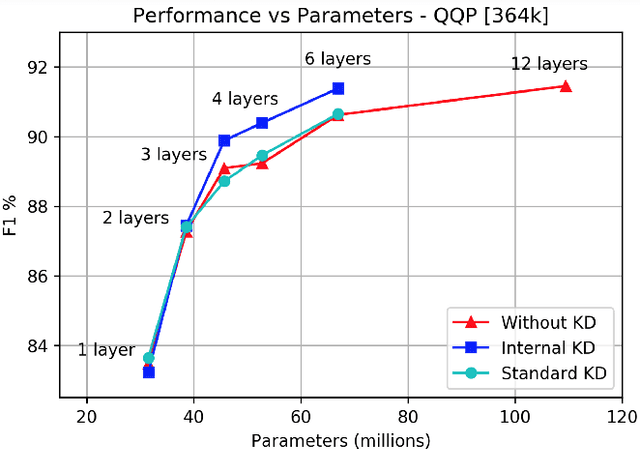
Knowledge distillation is typically conducted by training a small model (the student) to mimic a large and cumbersome model (the teacher). The idea is to compress the knowledge from the teacher by using its output probabilities as soft-labels to optimize the student. However, when the teacher is considerably large, there is no guarantee that the internal knowledge of the teacher will be transferred into the student; even if the student closely matches the soft-labels, its internal representations may be considerably different. This internal mismatch can undermine the generalization capabilities originally intended to be transferred from the teacher to the student. In this paper, we propose to distill the internal representations of a large model such as BERT into a simplified version of it. We formulate two ways to distill such representations and various algorithms to conduct the distillation. We experiment with datasets from the GLUE benchmark and consistently show that adding knowledge distillation from internal representations is a more powerful method than only using soft-label distillation.