 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiejun Huang
Mitigating Communication Costs in Neural Networks: The Role of Dendritic Nonlinearity
Jun 21, 2023
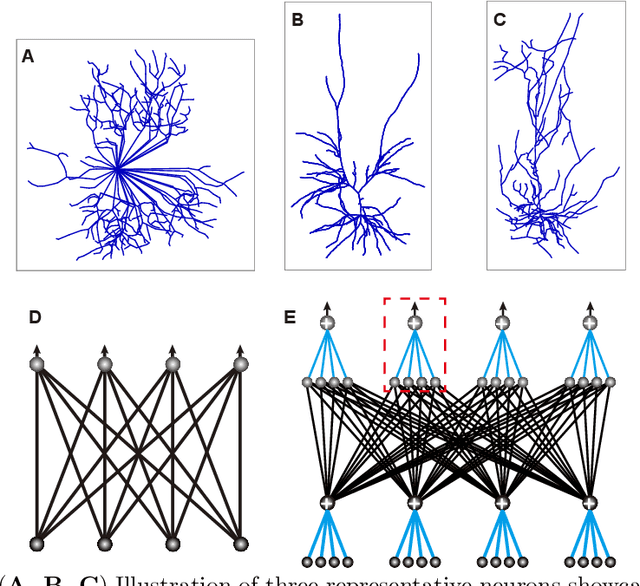
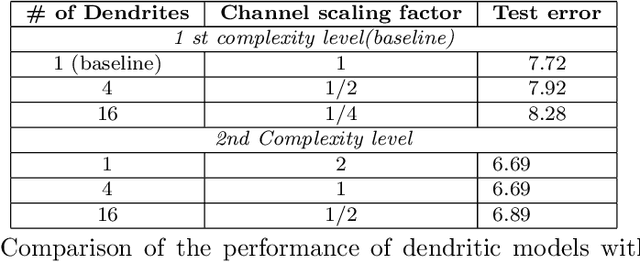
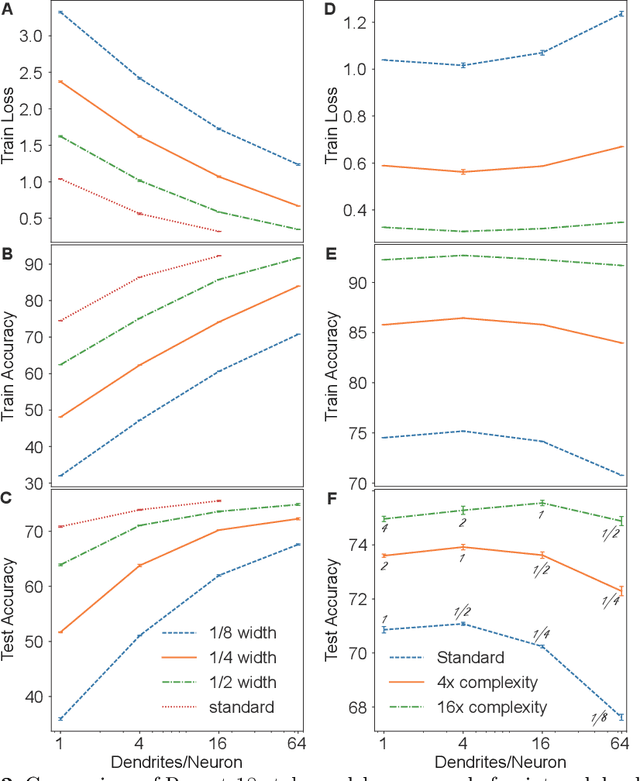

Our comprehension of biological neuronal networks has profoundly influenced the evolution of artificial neural networks (ANNs). However, the neurons employed in ANNs exhibit remarkable deviations from their biological analogs, mainly due to the absence of complex dendritic trees encompassing local nonlinearity. Despite such disparities, previous investigations have demonstrated that point neurons can functionally substitute dendritic neurons in executing computational tasks. In this study, we scrutinized the importance of nonlinear dendrites within neural networks. By employing machine-learning methodologies, we assessed the impact of dendritic structure nonlinearity on neural network performance. Our findings reveal that integrating dendritic structures can substantially enhance model capacity and performance while keeping signal communication costs effectively restrained. This investigation offers pivotal insights that hold considerable implications for the development of future neural network accelerators.
Pushing the Limits of 3D Shape Generation at Scale
Jun 20, 2023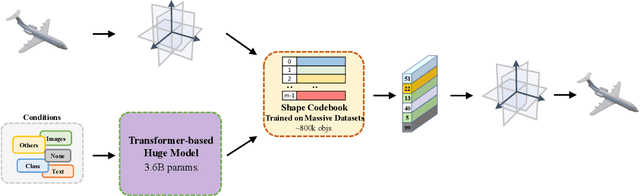
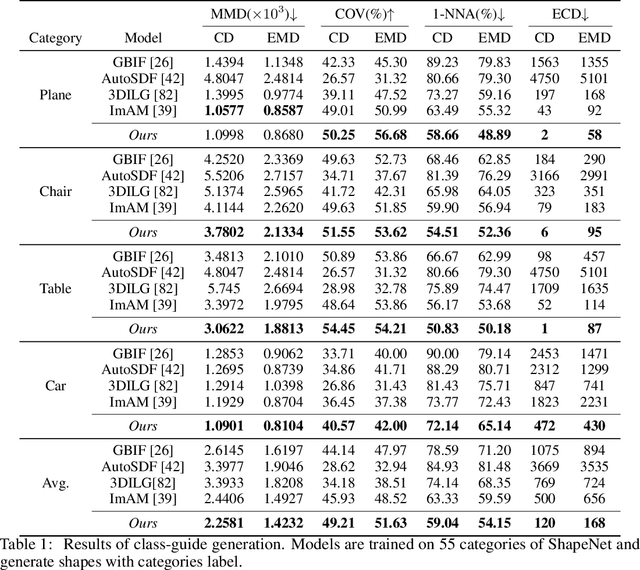


We present a significant breakthrough in 3D shape generation by scaling it to unprecedented dimensions. Through the adaptation of the Auto-Regressive model and the utilization of large language models, we have developed a remarkable model with an astounding 3.6 billion trainable parameters, establishing it as the largest 3D shape generation model to date, named Argus-3D. Our approach addresses the limitations of existing methods by enhancing the quality and diversity of generated 3D shapes. To tackle the challenges of high-resolution 3D shape generation, our model incorporates tri-plane features as latent representations, effectively reducing computational complexity. Additionally, we introduce a discrete codebook for efficient quantization of these representations. Leveraging the power of transformers, we enable multi-modal conditional generation, facilitating the production of diverse and visually impressive 3D shapes. To train our expansive model, we leverage an ensemble of publicly-available 3D datasets, consisting of a comprehensive collection of approximately 900,000 objects from renowned repositories such as ModelNet40, ShapeNet, Pix3D, 3D-Future, and Objaverse. This diverse dataset empowers our model to learn from a wide range of object variations, bolstering its ability to generate high-quality and diverse 3D shapes. Extensive experimentation demonstrate the remarkable efficacy of our approach in significantly improving the visual quality of generated 3D shapes. By pushing the boundaries of 3D generation, introducing novel methods for latent representation learning, and harnessing the power of transformers for multi-modal conditional generation, our contributions pave the way for substantial advancements in the field. Our work unlocks new possibilities for applications in gaming, virtual reality, product design, and other domains that demand high-quality and diverse 3D objects.
Spike timing reshapes robustness against attacks in spiking neural networks
Jun 09, 2023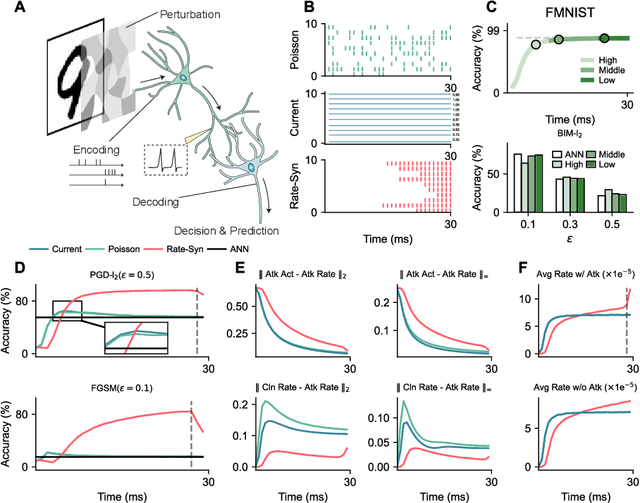
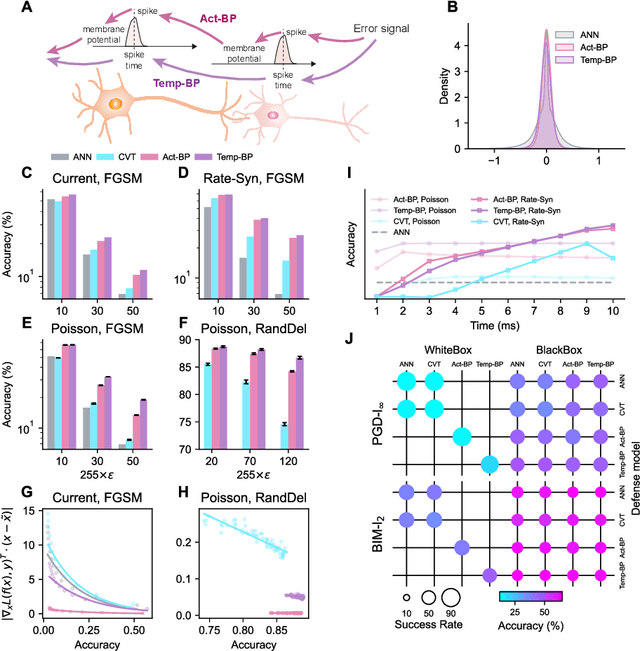
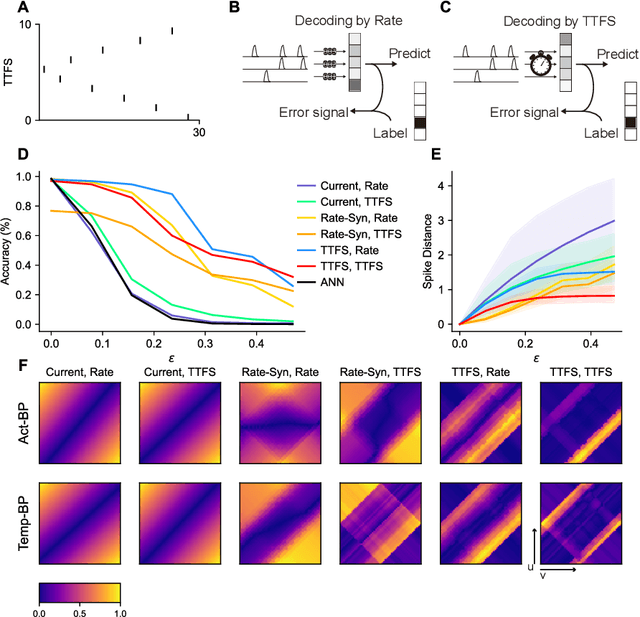
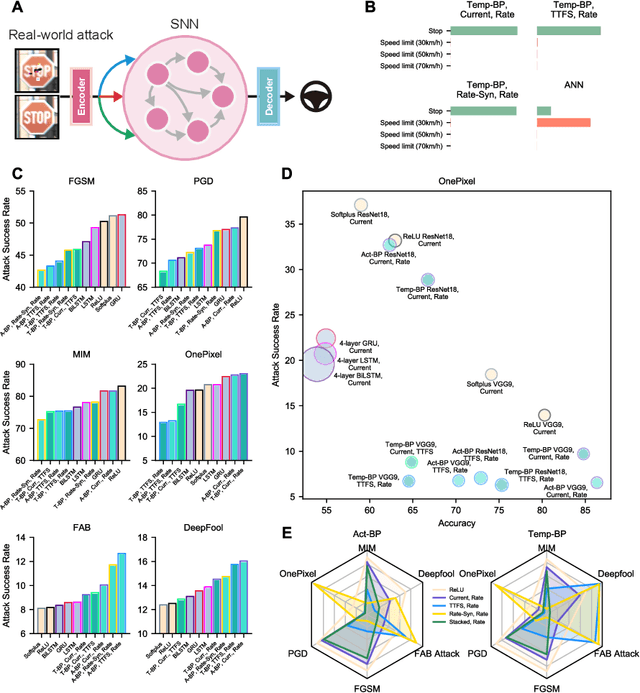
The success of deep learning in the past decade is partially shrouded in the shadow of adversarial attacks. In contrast, the brain is far more robust at complex cognitive tasks. Utilizing the advantage that neurons in the brain communicate via spikes, spiking neural networks (SNNs) are emerging as a new type of neural network model, boosting the frontier of theoretical investigation and empirical application of artificial neural networks and deep learning. Neuroscience research proposes that the precise timing of neural spikes plays an important role in the information coding and sensory processing of the biological brain. However, the role of spike timing in SNNs is less considered and far from understood. Here we systematically explored the timing mechanism of spike coding in SNNs, focusing on the robustness of the system against various types of attacks. We found that SNNs can achieve higher robustness improvement using the coding principle of precise spike timing in neural encoding and decoding, facilitated by different learning rules. Our results suggest that the utility of spike timing coding in SNNs could improve the robustness against attacks, providing a new approach to reliable coding principles for developing next-generation brain-inspired deep learning.
Large-scale Dataset Pruning with Dynamic Uncertainty
Jun 08, 2023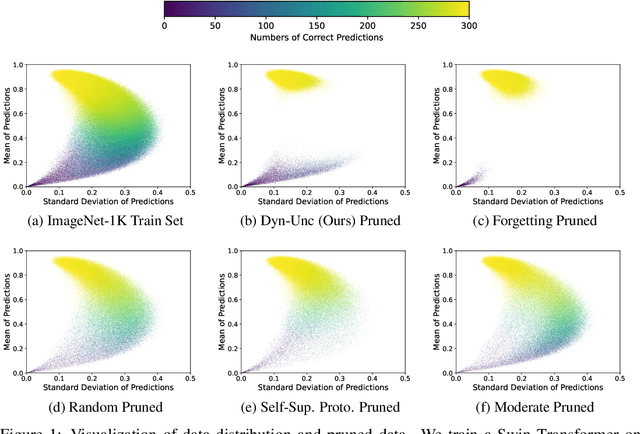
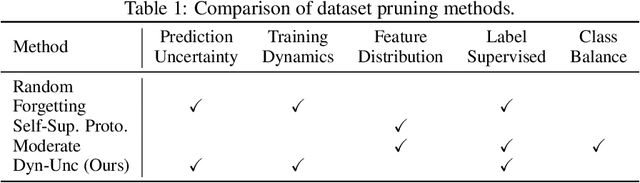

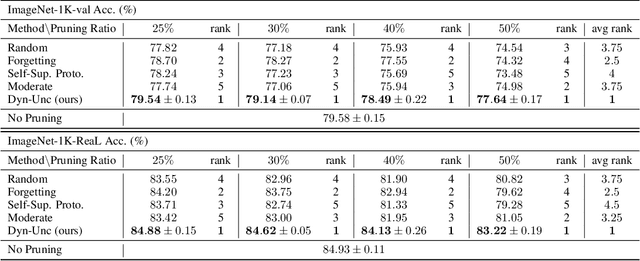
The state of the art of many learning tasks, e.g., image classification, is advanced by collecting larger datasets and then training larger models on them. As the outcome, the increasing computational cost is becoming unaffordable. In this paper, we investigate how to prune the large-scale datasets, and thus produce an informative subset for training sophisticated deep models with negligible performance drop. We propose a simple yet effective dataset pruning method by exploring both the prediction uncertainty and training dynamics. To our knowledge, this is the first work to study dataset pruning on large-scale datasets, i.e., ImageNet-1K and ImageNet-21K, and advanced models, i.e., Swin Transformer and ConvNeXt. Extensive experimental results indicate that our method outperforms the state of the art and achieves 75% lossless compression ratio on both ImageNet-1K and ImageNet-21K. The code and pruned datasets are available at https://github.com/BAAI-DCAI/Dataset-Pruning.
HUB: Guiding Learned Optimizers with Continuous Prompt Tuning
May 31, 2023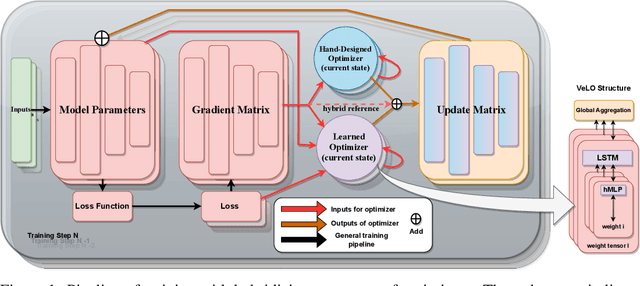
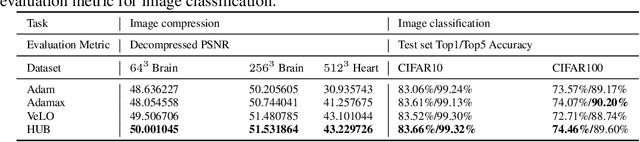
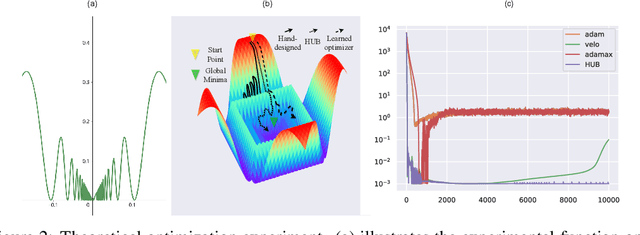
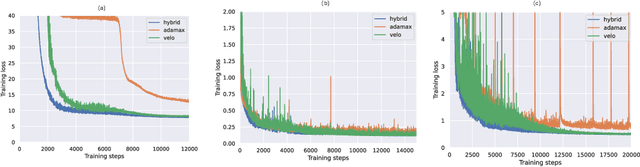
Learned optimizers are a crucial component of meta-learning. Recent advancements in scalable learned optimizers have demonstrated their superior performance over hand-designed optimizers in various tasks. However, certain characteristics of these models, such as an unstable learning curve, limited ability to handle unseen tasks and network architectures, difficult-to-control behaviours, and poor performance in fine-tuning tasks impede their widespread adoption. To tackle the issue of generalization in scalable learned optimizers, we propose a hybrid-update-based (HUB) optimization strategy inspired by recent advancements in hard prompt tuning and result selection techniques used in large language and vision models. This approach can be easily applied to any task that involves hand-designed or learned optimizer. By incorporating hand-designed optimizers as the second component in our hybrid approach, we are able to retain the benefits of learned optimizers while stabilizing the training process and, more importantly, improving testing performance. We validate our design through a total of 17 tasks, consisting of thirteen training from scratch and four fine-tuning settings. These tasks vary in model sizes, architectures, or dataset sizes, and the competing optimizers are hyperparameter-tuned. We outperform all competitors in 94% of the tasks with better testing performance. Furthermore, we conduct a theoretical analysis to examine the potential impact of our hybrid strategy on the behaviours and inherited traits of learned optimizers.
SegGPT: Segmenting Everything In Context
Apr 06, 2023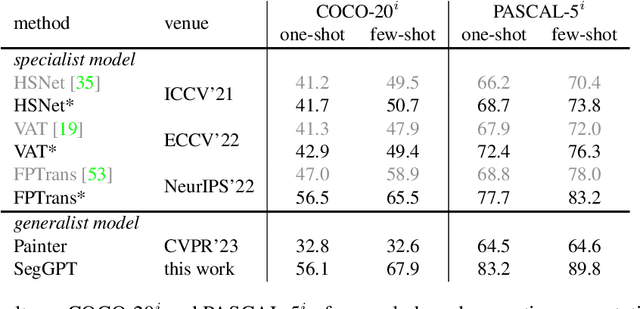
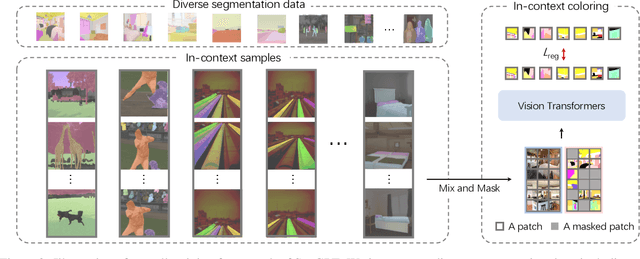
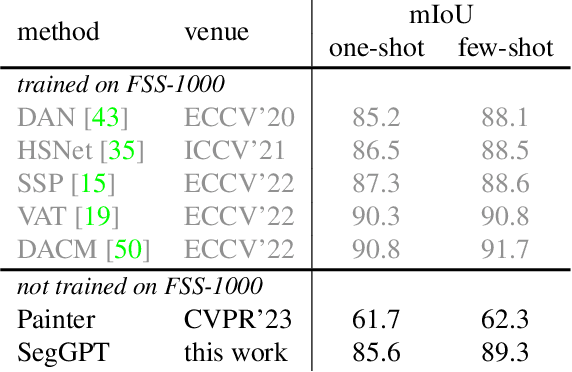
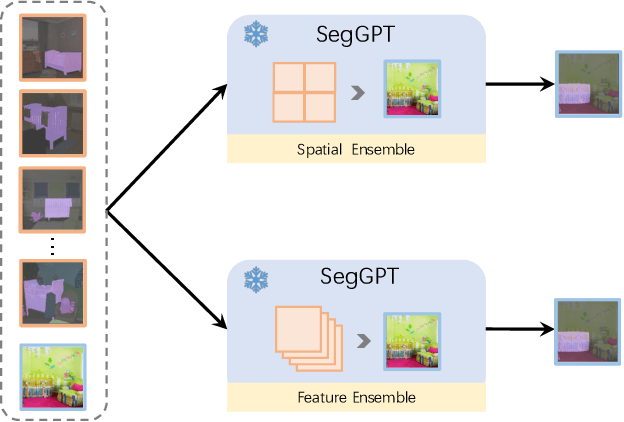
We present SegGPT, a generalist model for segmenting everything in context. We unify various segmentation tasks into a generalist in-context learning framework that accommodates different kinds of segmentation data by transforming them into the same format of images. The training of SegGPT is formulated as an in-context coloring problem with random color mapping for each data sample. The objective is to accomplish diverse tasks according to the context, rather than relying on specific colors. After training, SegGPT can perform arbitrary segmentation tasks in images or videos via in-context inference, such as object instance, stuff, part, contour, and text. SegGPT is evaluated on a broad range of tasks, including few-shot semantic segmentation, video object segmentation, semantic segmentation, and panoptic segmentation. Our results show strong capabilities in segmenting in-domain and out-of-domain targets, either qualitatively or quantitatively.
Spike Stream Denoising via Spike Camera Simulation
Apr 06, 2023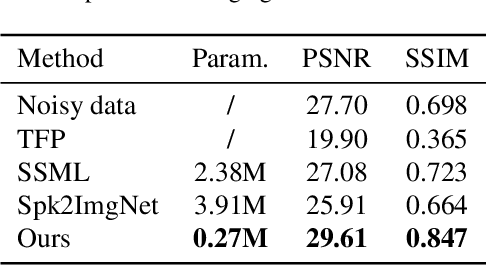


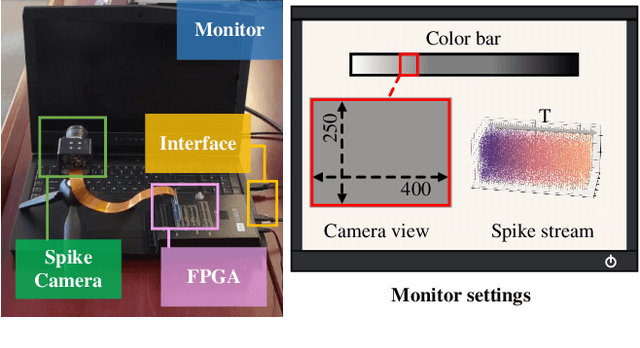
As a neuromorphic sensor with high temporal resolution, the spike camera shows enormous potential in high-speed visual tasks. However, the high-speed sampling of light propagation processes by existing cameras brings unavoidable noise phenomena. Eliminating the unique noise in spike stream is always a key point for spike-based methods. No previous work has addressed the detailed noise mechanism of the spike camera. To this end, we propose a systematic noise model for spike camera based on its unique circuit. In addition, we carefully constructed the noise evaluation equation and experimental scenarios to measure noise variables. Based on our noise model, the first benchmark for spike stream denoising is proposed which includes clear (noisy) spike stream. Further, we design a tailored spike stream denoising framework (DnSS) where denoised spike stream is obtained by decoding inferred inter-spike intervals. Experiments show that DnSS has promising performance on the proposed benchmark. Eventually, DnSS can be generalized well on real spike stream.
Exploring Asymmetric Tunable Blind-Spots for Self-supervised Denoising in Real-World Scenarios
Mar 29, 2023
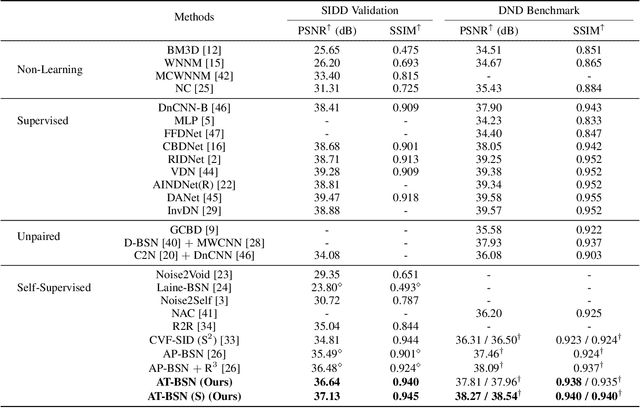
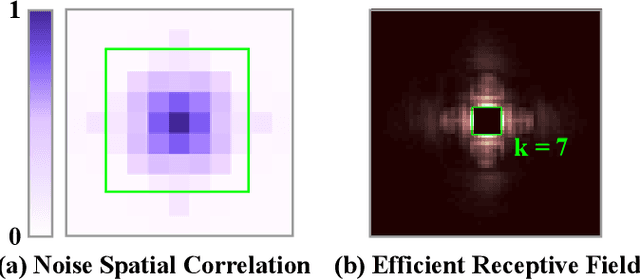
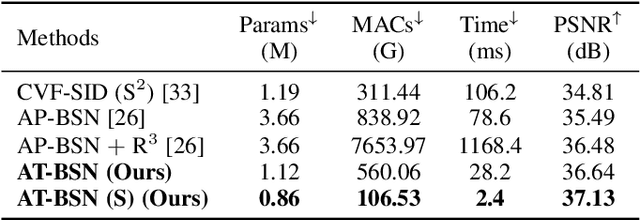
Self-supervised denoising has attracted widespread attention due to its ability to train without clean images. However, noise in real-world scenarios is often spatially correlated, which causes many self-supervised algorithms based on the pixel-wise independent noise assumption to perform poorly on real-world images. Recently, asymmetric pixel-shuffle downsampling (AP) has been proposed to disrupt the spatial correlation of noise. However, downsampling introduces aliasing effects, and the post-processing to eliminate these effects can destroy the spatial structure and high-frequency details of the image, in addition to being time-consuming. In this paper, we systematically analyze downsampling-based methods and propose an Asymmetric Tunable Blind-Spot Network (AT-BSN) to address these issues. We design a blind-spot network with a freely tunable blind-spot size, using a large blind-spot during training to suppress local spatially correlated noise while minimizing damage to the global structure, and a small blind-spot during inference to minimize information loss. Moreover, we propose blind-spot self-ensemble and distillation of non-blind-spot network to further improve performance and reduce computational complexity. Experimental results demonstrate that our method achieves state-of-the-art results while comprehensively outperforming other self-supervised methods in terms of image texture maintaining, parameter count, computation cost, and inference time.
EVA-02: A Visual Representation for Neon Genesis
Mar 22, 2023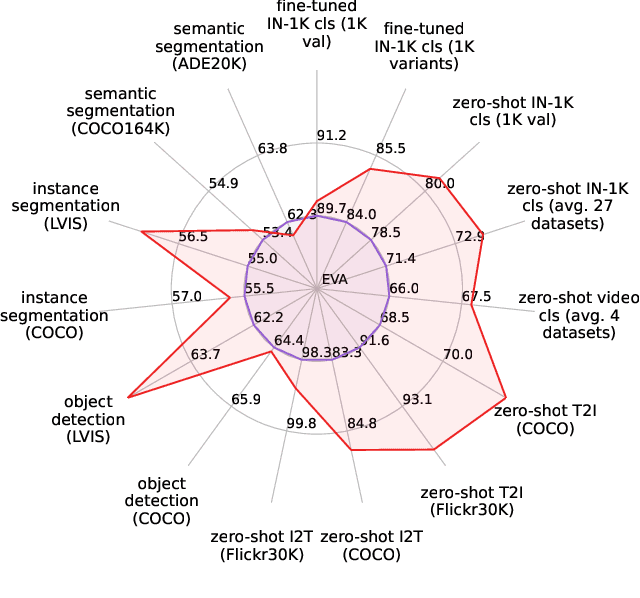

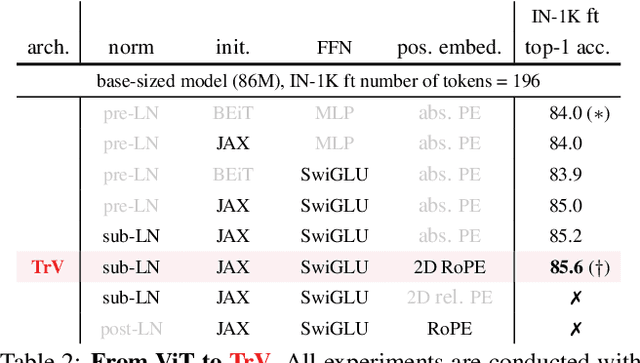
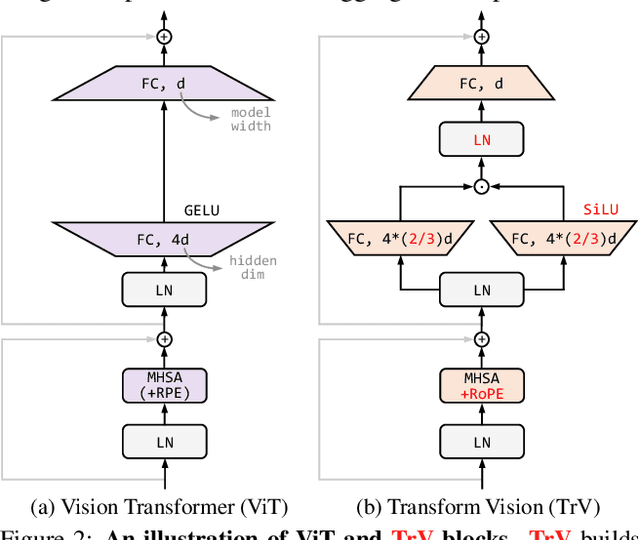
We launch EVA-02, a next-generation Transformer-based visual representation pre-trained to reconstruct strong and robust language-aligned vision features via masked image modeling. With an updated plain Transformer architecture as well as extensive pre-training from an open & accessible giant CLIP vision encoder, EVA-02 demonstrates superior performance compared to prior state-of-the-art approaches across various representative vision tasks, while utilizing significantly fewer parameters and compute budgets. Notably, using exclusively publicly accessible training data, EVA-02 with only 304M parameters achieves a phenomenal 90.0 fine-tuning top-1 accuracy on ImageNet-1K val set. Additionally, our EVA-02-CLIP can reach up to 80.4 zero-shot top-1 on ImageNet-1K, outperforming the previous largest & best open-sourced CLIP with only ~1/6 parameters and ~1/6 image-text training data. We offer four EVA-02 variants in various model sizes, ranging from 6M to 304M parameters, all with impressive performance. To facilitate open access and open research, we release the complete suite of EVA-02 to the community at https://github.com/baaivision/EVA/tree/master/EVA-02.