 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScores Know Bobs Voice: Speaker Impersonation Attack
Mar 03, 2026Advances in deep learning have enabled the widespread deployment of speaker recognition systems (SRSs), yet they remain vulnerable to score-based impersonation attacks. Existing attacks that operate directly on raw waveforms require a large number of queries due to the difficulty of optimizing in high-dimensional audio spaces. Latent-space optimization within generative models offers improved efficiency, but these latent spaces are shaped by data distribution matching and do not inherently capture speaker-discriminative geometry. As a result, optimization trajectories often fail to align with the adversarial direction needed to maximize victim scores. To address this limitation, we propose an inversion-based generative attack framework that explicitly aligns the latent space of the synthesis model with the discriminative feature space of SRSs. We first analyze the requirements of an inverse model for score-based attacks and introduce a feature-aligned inversion strategy that geometrically synchronizes latent representations with speaker embeddings. This alignment ensures that latent updates directly translate into score improvements. Moreover, it enables new attack paradigms, including subspace-projection-based attacks, which were previously infeasible due to the absence of a faithful feature-to-audio mapping. Experiments show that our method significantly improves query efficiency, achieving competitive attack success rates with on average 10x fewer queries than prior approaches. In particular, the enabled subspace-projection-based attack attains up to 91.65% success using only 50 queries. These findings establish feature-aligned inversion as a key tool for evaluating the robustness of modern SRSs against score-based impersonation threats.
I Can Find You in Seconds! Leveraging Large Language Models for Code Authorship Attribution
Jan 14, 2025



Source code authorship attribution is important in software forensics, plagiarism detection, and protecting software patch integrity. Existing techniques often rely on supervised machine learning, which struggles with generalization across different programming languages and coding styles due to the need for large labeled datasets. Inspired by recent advances in natural language authorship analysis using large language models (LLMs), which have shown exceptional performance without task-specific tuning, this paper explores the use of LLMs for source code authorship attribution. We present a comprehensive study demonstrating that state-of-the-art LLMs can successfully attribute source code authorship across different languages. LLMs can determine whether two code snippets are written by the same author with zero-shot prompting, achieving a Matthews Correlation Coefficient (MCC) of 0.78, and can attribute code authorship from a small set of reference code snippets via few-shot learning, achieving MCC of 0.77. Additionally, LLMs show some adversarial robustness against misattribution attacks. Despite these capabilities, we found that naive prompting of LLMs does not scale well with a large number of authors due to input token limitations. To address this, we propose a tournament-style approach for large-scale attribution. Evaluating this approach on datasets of C++ (500 authors, 26,355 samples) and Java (686 authors, 55,267 samples) code from GitHub, we achieve classification accuracy of up to 65% for C++ and 68.7% for Java using only one reference per author. These results open new possibilities for applying LLMs to code authorship attribution in cybersecurity and software engineering.
Unsupervised Fingerphoto Presentation Attack Detection With Diffusion Models
Sep 27, 2024



Smartphone-based contactless fingerphoto authentication has become a reliable alternative to traditional contact-based fingerprint biometric systems owing to rapid advances in smartphone camera technology. Despite its convenience, fingerprint authentication through fingerphotos is more vulnerable to presentation attacks, which has motivated recent research efforts towards developing fingerphoto Presentation Attack Detection (PAD) techniques. However, prior PAD approaches utilized supervised learning methods that require labeled training data for both bona fide and attack samples. This can suffer from two key issues, namely (i) generalization:the detection of novel presentation attack instruments (PAIs) unseen in the training data, and (ii) scalability:the collection of a large dataset of attack samples using different PAIs. To address these challenges, we propose a novel unsupervised approach based on a state-of-the-art deep-learning-based diffusion model, the Denoising Diffusion Probabilistic Model (DDPM), which is trained solely on bona fide samples. The proposed approach detects Presentation Attacks (PA) by calculating the reconstruction similarity between the input and output pairs of the DDPM. We present extensive experiments across three PAI datasets to test the accuracy and generalization capability of our approach. The results show that the proposed DDPM-based PAD method achieves significantly better detection error rates on several PAI classes compared to other baseline unsupervised approaches.
Formally Certified Approximate Model Counting
Jun 17, 2024Approximate model counting is the task of approximating the number of solutions to an input Boolean formula. The state-of-the-art approximate model counter for formulas in conjunctive normal form (CNF), ApproxMC, provides a scalable means of obtaining model counts with probably approximately correct (PAC)-style guarantees. Nevertheless, the validity of ApproxMC's approximation relies on a careful theoretical analysis of its randomized algorithm and the correctness of its highly optimized implementation, especially the latter's stateful interactions with an incremental CNF satisfiability solver capable of natively handling parity (XOR) constraints. We present the first certification framework for approximate model counting with formally verified guarantees on the quality of its output approximation. Our approach combines: (i) a static, once-off, formal proof of the algorithm's PAC guarantee in the Isabelle/HOL proof assistant; and (ii) dynamic, per-run, verification of ApproxMC's calls to an external CNF-XOR solver using proof certificates. We detail our general approach to establish a rigorous connection between these two parts of the verification, including our blueprint for turning the formalized, randomized algorithm into a verified proof checker, and our design of proof certificates for both ApproxMC and its internal CNF-XOR solving steps. Experimentally, we show that certificate generation adds little overhead to an approximate counter implementation, and that our certificate checker is able to fully certify $84.7\%$ of instances with generated certificates when given the same time and memory limits as the counter.
Certified MaxSAT Preprocessing
Apr 26, 2024



Building on the progress in Boolean satisfiability (SAT) solving over the last decades, maximum satisfiability (MaxSAT) has become a viable approach for solving NP-hard optimization problems, but ensuring correctness of MaxSAT solvers has remained an important concern. For SAT, this is largely a solved problem thanks to the use of proof logging, meaning that solvers emit machine-verifiable proofs of (un)satisfiability to certify correctness. However, for MaxSAT, proof logging solvers have started being developed only very recently. Moreover, these nascent efforts have only targeted the core solving process, ignoring the preprocessing phase where input problem instances can be substantially reformulated before being passed on to the solver proper. In this work, we demonstrate how pseudo-Boolean proof logging can be used to certify the correctness of a wide range of modern MaxSAT preprocessing techniques. By combining and extending the VeriPB and CakePB tools, we provide formally verified, end-to-end proof checking that the input and preprocessed output MaxSAT problem instances have the same optimal value. An extensive evaluation on applied MaxSAT benchmarks shows that our approach is feasible in practice.
Blackbox End-to-End Verification of Ground Robot Safety and Liveness
Mar 12, 2019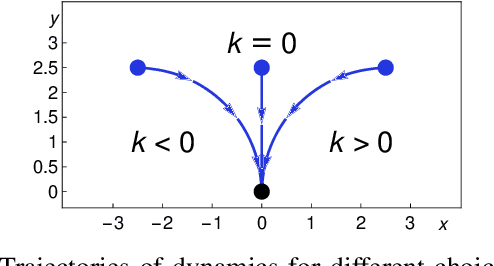
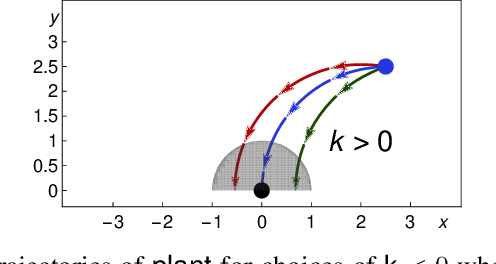
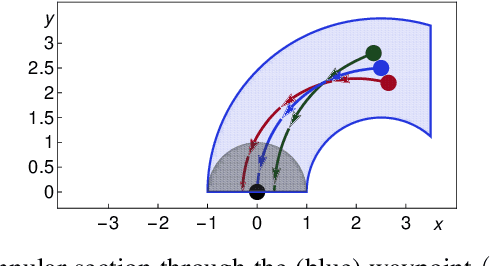
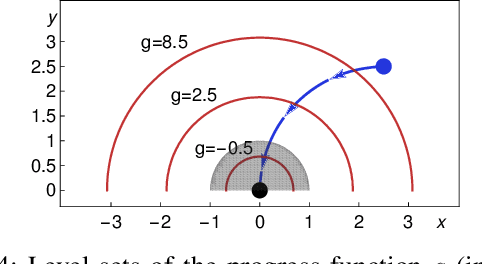
We formally prove end-to-end correctness of a ground robot implemented in a simulator. We use an untrusted controller supervised by a verified sandbox. Contributions include: (i) A model of the robot in differential dynamic logic, which specifies assumptions on the controller and robot kinematics, (ii) Formal proofs of safety and liveness for a waypoint-following problem with speed limits, (iii) An automatically synthesized sandbox, which is automatically proven to enforce model compliance at runtime, and (iv) Controllers, planners, and environments for the simulations. The verified sandbox is used to safeguard (unverified) controllers in a realistic simulated environment. Experimental evaluation of the resulting sandboxed implementation confirms safety and high model-compliance, with an inherent trade-off between compliance and performance. The verified sandbox thus serves as a valuable bidirectional link between formal methods and implementation, automating both enforcement of safety and model validation simultaneously.
Improved Recurrent Neural Networks for Session-based Recommendations
Sep 16, 2016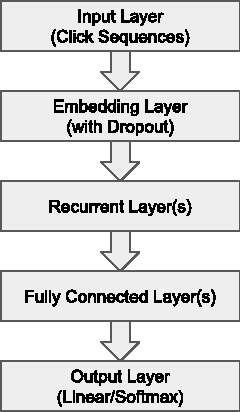
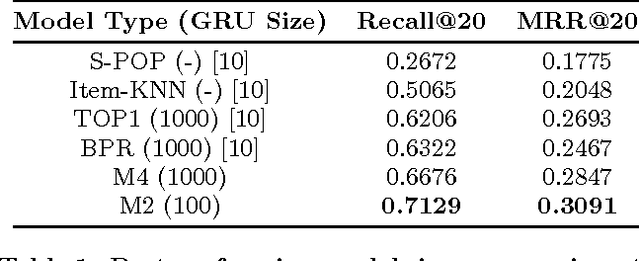
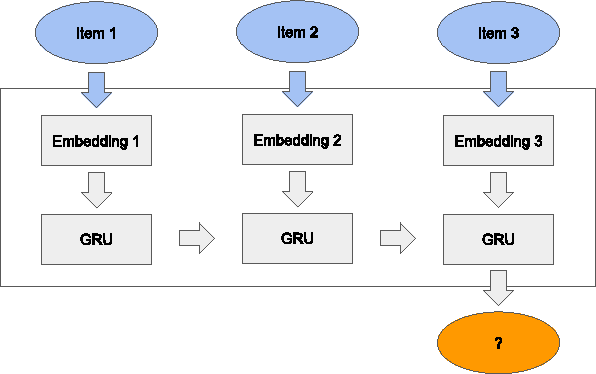
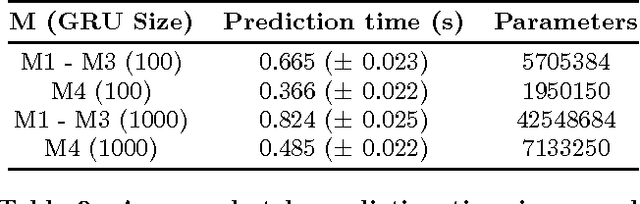
Recurrent neural networks (RNNs) were recently proposed for the session-based recommendation task. The models showed promising improvements over traditional recommendation approaches. In this work, we further study RNN-based models for session-based recommendations. We propose the application of two techniques to improve model performance, namely, data augmentation, and a method to account for shifts in the input data distribution. We also empirically study the use of generalised distillation, and a novel alternative model that directly predicts item embeddings. Experiments on the RecSys Challenge 2015 dataset demonstrate relative improvements of 12.8% and 14.8% over previously reported results on the Recall@20 and Mean Reciprocal Rank@20 metrics respectively.
Multi-Modal Hybrid Deep Neural Network for Speech Enhancement
Jun 15, 2016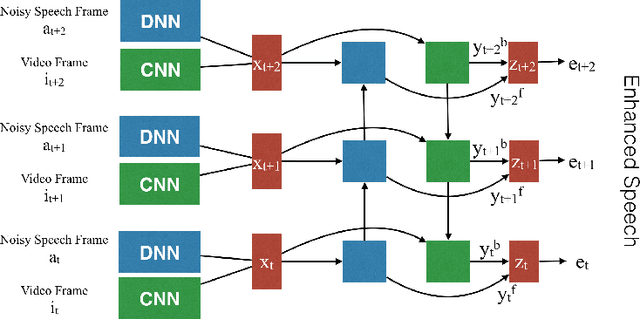
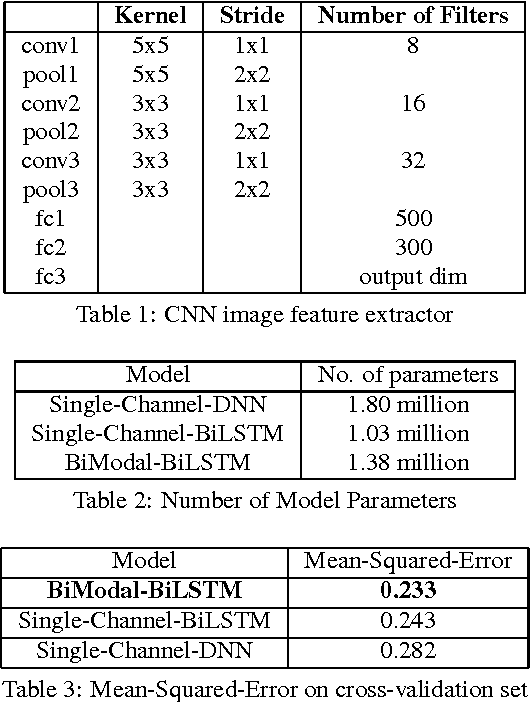
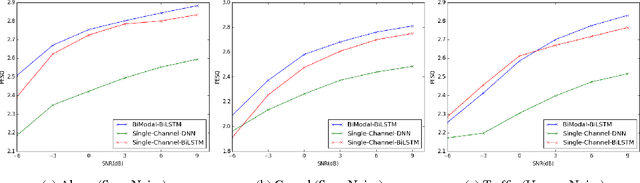
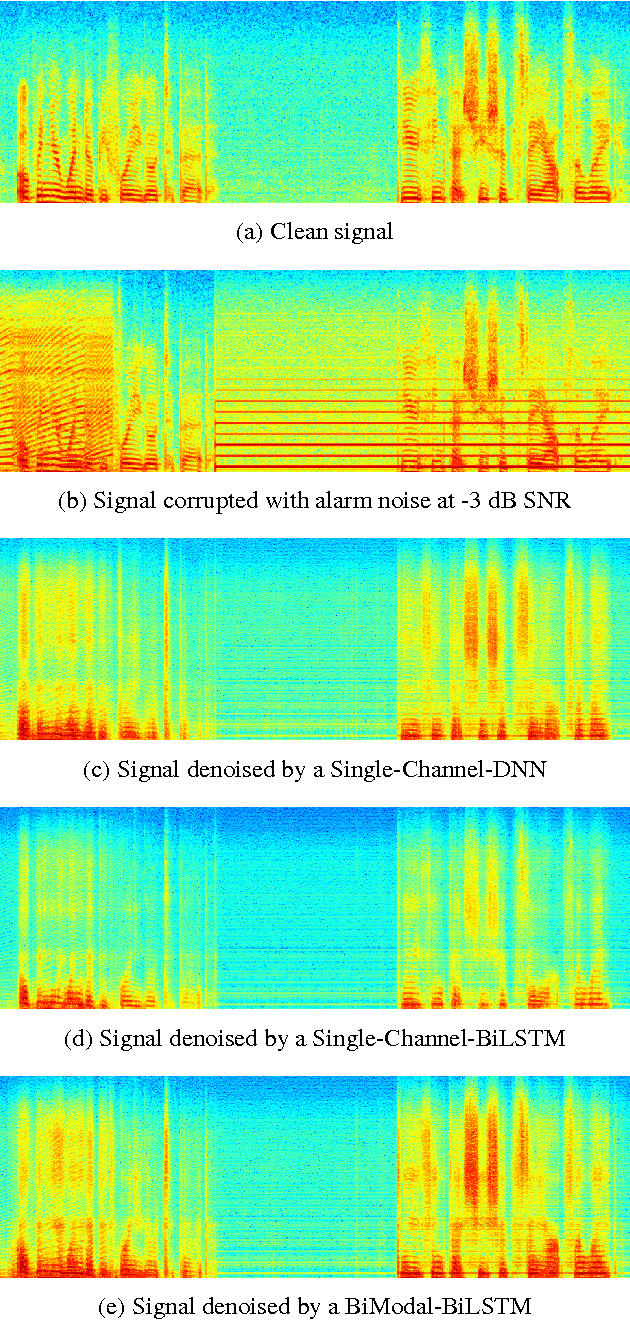
Deep Neural Networks (DNN) have been successful in en- hancing noisy speech signals. Enhancement is achieved by learning a nonlinear mapping function from the features of the corrupted speech signal to that of the reference clean speech signal. The quality of predicted features can be improved by providing additional side channel information that is robust to noise, such as visual cues. In this paper we propose a novel deep learning model inspired by insights from human audio visual perception. In the proposed unified hybrid architecture, features from a Convolution Neural Network (CNN) that processes the visual cues and features from a fully connected DNN that processes the audio signal are integrated using a Bidirectional Long Short-Term Memory (BiLSTM) network. The parameters of the hybrid model are jointly learned using backpropagation. We compare the quality of enhanced speech from the hybrid models with those from traditional DNN and BiLSTM models.