 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScores Know Bobs Voice: Speaker Impersonation Attack
Mar 03, 2026Advances in deep learning have enabled the widespread deployment of speaker recognition systems (SRSs), yet they remain vulnerable to score-based impersonation attacks. Existing attacks that operate directly on raw waveforms require a large number of queries due to the difficulty of optimizing in high-dimensional audio spaces. Latent-space optimization within generative models offers improved efficiency, but these latent spaces are shaped by data distribution matching and do not inherently capture speaker-discriminative geometry. As a result, optimization trajectories often fail to align with the adversarial direction needed to maximize victim scores. To address this limitation, we propose an inversion-based generative attack framework that explicitly aligns the latent space of the synthesis model with the discriminative feature space of SRSs. We first analyze the requirements of an inverse model for score-based attacks and introduce a feature-aligned inversion strategy that geometrically synchronizes latent representations with speaker embeddings. This alignment ensures that latent updates directly translate into score improvements. Moreover, it enables new attack paradigms, including subspace-projection-based attacks, which were previously infeasible due to the absence of a faithful feature-to-audio mapping. Experiments show that our method significantly improves query efficiency, achieving competitive attack success rates with on average 10x fewer queries than prior approaches. In particular, the enabled subspace-projection-based attack attains up to 91.65% success using only 50 queries. These findings establish feature-aligned inversion as a key tool for evaluating the robustness of modern SRSs against score-based impersonation threats.
I Can Find You in Seconds! Leveraging Large Language Models for Code Authorship Attribution
Jan 14, 2025



Source code authorship attribution is important in software forensics, plagiarism detection, and protecting software patch integrity. Existing techniques often rely on supervised machine learning, which struggles with generalization across different programming languages and coding styles due to the need for large labeled datasets. Inspired by recent advances in natural language authorship analysis using large language models (LLMs), which have shown exceptional performance without task-specific tuning, this paper explores the use of LLMs for source code authorship attribution. We present a comprehensive study demonstrating that state-of-the-art LLMs can successfully attribute source code authorship across different languages. LLMs can determine whether two code snippets are written by the same author with zero-shot prompting, achieving a Matthews Correlation Coefficient (MCC) of 0.78, and can attribute code authorship from a small set of reference code snippets via few-shot learning, achieving MCC of 0.77. Additionally, LLMs show some adversarial robustness against misattribution attacks. Despite these capabilities, we found that naive prompting of LLMs does not scale well with a large number of authors due to input token limitations. To address this, we propose a tournament-style approach for large-scale attribution. Evaluating this approach on datasets of C++ (500 authors, 26,355 samples) and Java (686 authors, 55,267 samples) code from GitHub, we achieve classification accuracy of up to 65% for C++ and 68.7% for Java using only one reference per author. These results open new possibilities for applying LLMs to code authorship attribution in cybersecurity and software engineering.
Unsupervised Fingerphoto Presentation Attack Detection With Diffusion Models
Sep 27, 2024



Smartphone-based contactless fingerphoto authentication has become a reliable alternative to traditional contact-based fingerprint biometric systems owing to rapid advances in smartphone camera technology. Despite its convenience, fingerprint authentication through fingerphotos is more vulnerable to presentation attacks, which has motivated recent research efforts towards developing fingerphoto Presentation Attack Detection (PAD) techniques. However, prior PAD approaches utilized supervised learning methods that require labeled training data for both bona fide and attack samples. This can suffer from two key issues, namely (i) generalization:the detection of novel presentation attack instruments (PAIs) unseen in the training data, and (ii) scalability:the collection of a large dataset of attack samples using different PAIs. To address these challenges, we propose a novel unsupervised approach based on a state-of-the-art deep-learning-based diffusion model, the Denoising Diffusion Probabilistic Model (DDPM), which is trained solely on bona fide samples. The proposed approach detects Presentation Attacks (PA) by calculating the reconstruction similarity between the input and output pairs of the DDPM. We present extensive experiments across three PAI datasets to test the accuracy and generalization capability of our approach. The results show that the proposed DDPM-based PAD method achieves significantly better detection error rates on several PAI classes compared to other baseline unsupervised approaches.
Skellam Mixture Mechanism: a Novel Approach to Federated Learning with Differential Privacy
Dec 08, 2022


Deep neural networks have strong capabilities of memorizing the underlying training data, which can be a serious privacy concern. An effective solution to this problem is to train models with differential privacy, which provides rigorous privacy guarantees by injecting random noise to the gradients. This paper focuses on the scenario where sensitive data are distributed among multiple participants, who jointly train a model through federated learning (FL), using both secure multiparty computation (MPC) to ensure the confidentiality of each gradient update, and differential privacy to avoid data leakage in the resulting model. A major challenge in this setting is that common mechanisms for enforcing DP in deep learning, which inject real-valued noise, are fundamentally incompatible with MPC, which exchanges finite-field integers among the participants. Consequently, most existing DP mechanisms require rather high noise levels, leading to poor model utility. Motivated by this, we propose Skellam mixture mechanism (SMM), an approach to enforce DP on models built via FL. Compared to existing methods, SMM eliminates the assumption that the input gradients must be integer-valued, and, thus, reduces the amount of noise injected to preserve DP. Further, SMM allows tight privacy accounting due to the nice composition and sub-sampling properties of the Skellam distribution, which are key to accurate deep learning with DP. The theoretical analysis of SMM is highly non-trivial, especially considering (i) the complicated math of differentially private deep learning in general and (ii) the fact that the mixture of two Skellam distributions is rather complex, and to our knowledge, has not been studied in the DP literature. Extensive experiments on various practical settings demonstrate that SMM consistently and significantly outperforms existing solutions in terms of the utility of the resulting model.
FFConv: Fast Factorized Neural Network Inference on Encrypted Data
Feb 06, 2021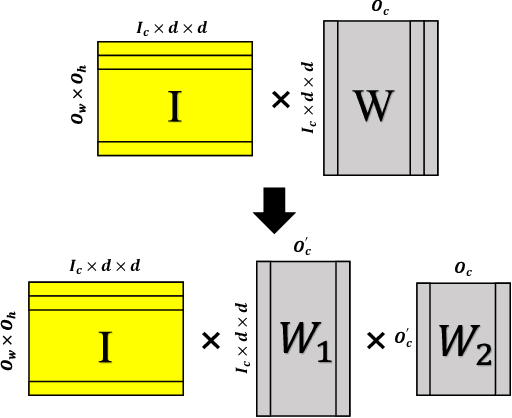
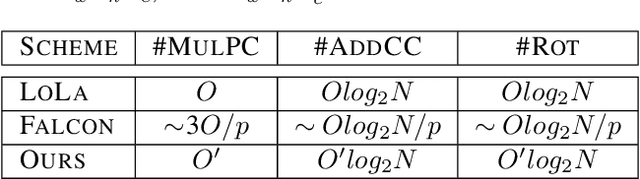
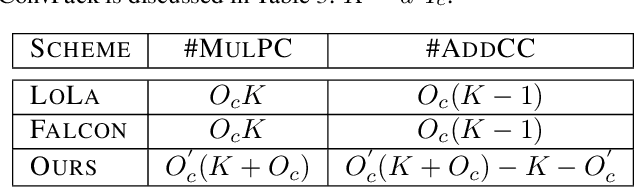
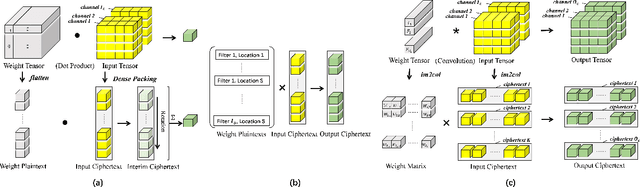
Homomorphic Encryption (HE), allowing computations on encrypted data (ciphertext) without decrypting it first, enables secure but prohibitively slow Neural Network (HENN) inference for privacy-preserving applications in clouds. To reduce HENN inference latency, one approach is to pack multiple messages into a single ciphertext in order to reduce the number of ciphertexts and support massive parallelism of Homomorphic Multiply-Add (HMA) operations between ciphertexts. However, different ciphertext packing schemes have to be designed for different convolution layers and each of them introduces overheads that are far more expensive than HMA operations. In this paper, we propose a low-rank factorization method called FFConv to unify convolution and ciphertext packing. To our knowledge, FFConv is the first work that is capable of accelerating the overheads induced by different ciphertext packing schemes simultaneously, without incurring a significant increase in noise budget. Compared to prior art LoLa and Falcon, our method reduces the inference latency by up to 87% and 12%, respectively, with comparable accuracy on MNIST and CIFAR-10.
PrivFT: Private and Fast Text Classification with Homomorphic Encryption
Aug 19, 2019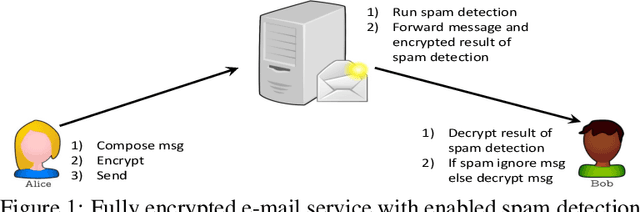
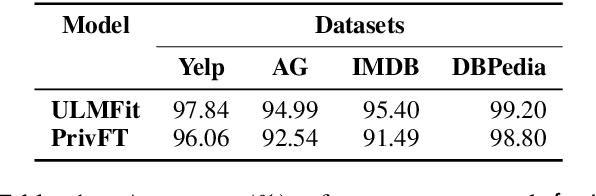
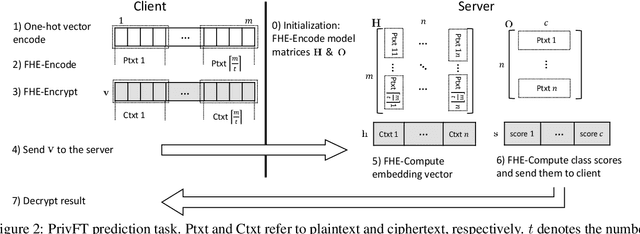
Privacy and security have increasingly become a concern for computing services in recent years. In this work, we present an efficient method for Text Classification while preserving the privacy of the content, using Fully Homomorphic Encryption (FHE). We train a simple supervised model on unencrypted data to achieve competitive results with recent approaches and outline a system for performing inferences directly on encrypted data with zero loss to prediction accuracy. This system is implemented with GPU hardware acceleration to achieve a run time per inference of less than 0.66 seconds, resulting in more than 12$\times$ speedup over its CPU counterpart. Finally, we show how to train this model from scratch using fully encrypted data to generate an encrypted model.
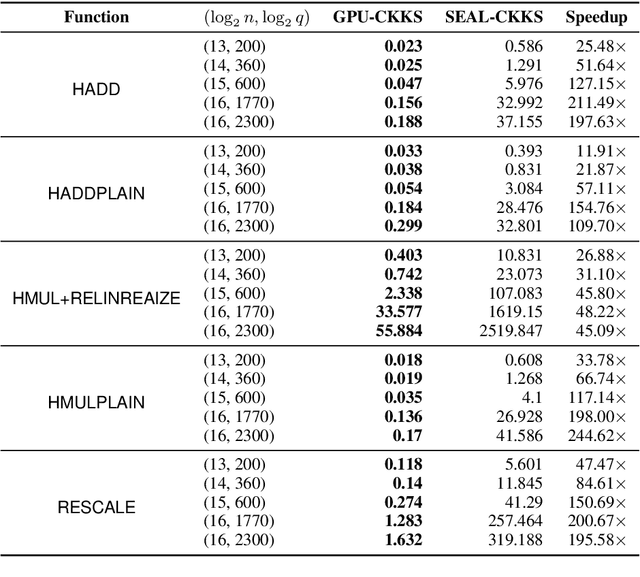
The AlexNet Moment for Homomorphic Encryption: HCNN, the First Homomorphic CNN on Encrypted Data with GPUs
Nov 02, 2018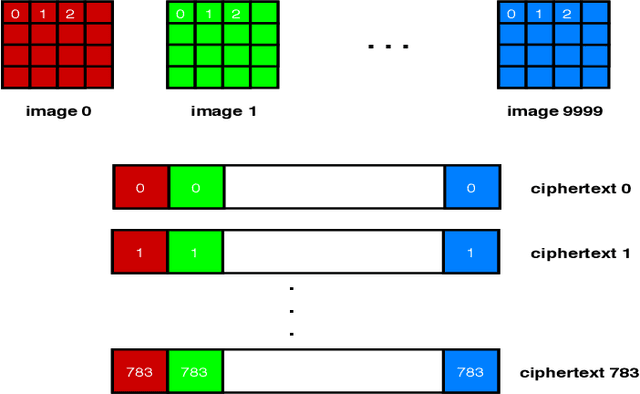

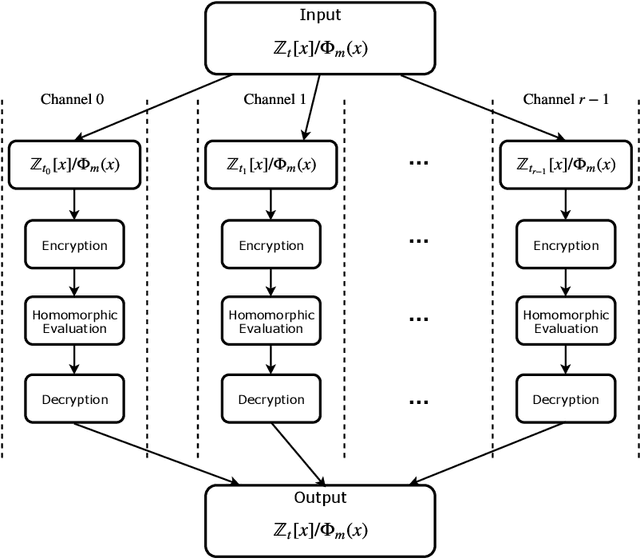
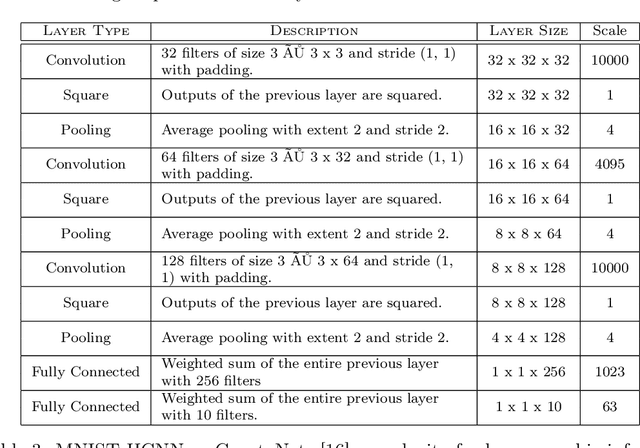
Fully homomorphic encryption, with its widely-known feature of computing on encrypted data, empowers a wide range of privacy-concerned cloud applications including deep learning as a service. This comes at a high cost since FHE includes highly-intensive computation that requires enormous computing power. Although the literature includes a number of proposals to run CNNs on encrypted data, the performance is still far from satisfactory. In this paper, we push the level up and show how to accelerate the performance of running CNNs on encrypted data using GPUs. We evaluated a CNN to classify homomorphically the MNIST dataset into 10 classes. We used a number of techniques such as low-precision training, unified training and testing network, optimized FHE parameters and a very efficient GPU implementation to achieve high performance. Our solution achieved high security level (> 128 bit) and high accuracy (99%). In terms of performance, our best results show that we could classify the entire testing dataset in 14.105 seconds, with per-image amortized time (1.411 milliseconds) 40.41x faster than prior art.